- The paper introduces a three-stage framework that identifies, analyzes, and synthesizes legal distinctions within case-based reasoning.
- It shows that while LLMs perform well on simple comparisons, their accuracy sharply declines in complex hierarchical reasoning tasks.
- Findings reveal that increased reasoning length leads to inefficiency, underscoring the need for advancements in legal AI models.
Thinking Longer, Not Always Smarter: Evaluating LLM Capabilities in Hierarchical Legal Reasoning
Introduction to Hierarchical Legal Reasoning
"Thinking Longer, Not Always Smarter: Evaluating LLM Capabilities in Hierarchical Legal Reasoning" (2510.08710) examines the capacity of LLMs to perform hierarchical reasoning within complex legal frameworks. Legal reasoning, especially in the context of case-based reasoning, involves drawing analogies to past precedents while distinguishing current cases from less favorable ones. This nuanced reasoning process poses significant challenges for AI systems, necessitating an understanding of legal concepts that extend beyond mere pattern matching.
(Figure 1)
Figure 1: The decomposed framework for identifying significant distinctions, which consists of three steps: (1) identify distinctions, (2) analyze argumentative roles of a distinction via legal knowledge hierarchy, and (3) identify significant distinctions. Red and blue presents the favoring side of the factors.
The authors present a formal framework that decomposes this complex reasoning into three tasks: identification of distinctions, analysis of these distinctions, and their evaluation as significant or otherwise. This structure mimics the hierarchical nature of legal reasoning by utilizing factual predicates and organizing them into a legal knowledge hierarchy, aiming to replicate the nuanced decision-making processes found in legal practice.
Methodology and Framework Development
The paper develops a structured methodology to assess the capability of LLMs to engage in hierarchical reasoning through a three-stage framework. This involves identifying significant factual distinctions between cases, leveraging a hierarchy based on the CATO framework. Each step requires increasingly complex reasoning, testing the LLM's ability to transition from surface-level analysis to deep cognitive synthesis.
- Task 1 - Identification of Distinctions: Focuses on determining factual differences that could impact analogical reasoning.
- Task 2 - Argumentative Analysis: Examines the roles these distinctions play within a legal hierarchy, considering how they can be emphasized or downplayed depending on the context.
- Task 3 - Synthesizing Significant Distinctions: Requires the integration of previous analyses to determine which distinctions hold significant weight in the argument.
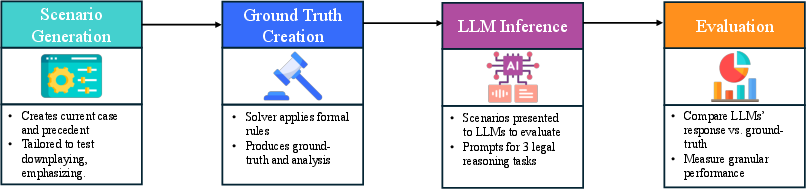
Figure 2: The evaluation pipeline, which consists of scenario generation, ground truth creation, LLM inference, and evaluation.
The evaluation involves creating structured scenarios wherein LLMs are prompted to perform each of these tasks. Ground truth is established via a symbolic solver, providing a baseline for LLM performance.
Empirical Results and Analysis
The results highlight a paradox: while LLMs can achieve high accuracy on simpler tasks, their performance deteriorates significantly as the complexity of reasoning tasks increases. Task 1 sees perfect scores, indicating proficiency in basic comparison, but accuracy ranges from 64.82% to 92.09% for Task 2, and plummets to as low as 11.46% for Task 3.
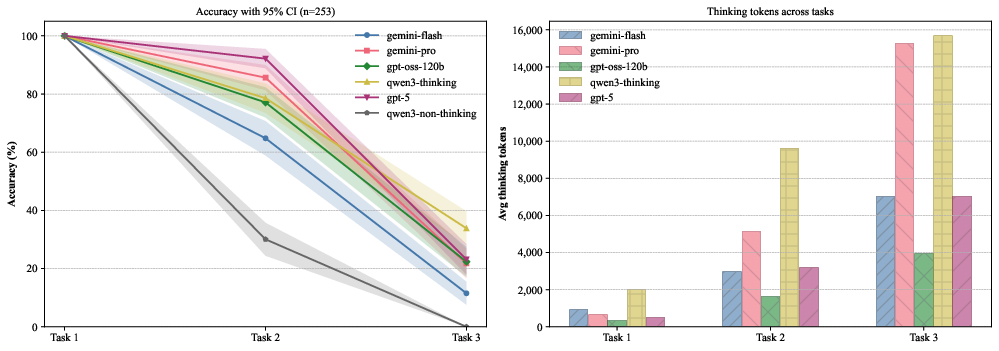
Figure 3: Model performance across Tasks 1--3. The left panel illustrates accuracy, showing a decline as tasks become more complex. The right panel displays the average number of thinking tokens used, which increases with task difficulty.
Models also demonstrated a tendency to expend more computational resources on incorrect responses than correct ones, an indicator that longer reasoning does not equate to more effective problem-solving. This inefficiency points to fundamental limitations in the current design and training of LLMs when faced with tasks that require high-level abstraction and integration of multiple reasoning processes.
Implications for AI in Legal Practice
These findings underscore the challenges of deploying AI systems in legal contexts where accuracy and reliability are paramount. The inability to reliably engage in integrated reasoning may limit the utility of LLMs in case-based legal reasoning and other areas requiring deep cognitive synthesis.
The research provides a roadmap for future developments in AI, emphasizing the need for improvements in reasoning capabilities. By delineating the strengths and weaknesses of current LLMs, it highlights areas where further development is necessary to achieve robust, trustworthy legal AI systems.
Conclusion
This careful examination of LLM abilities in hierarchical legal reasoning reveals both their potential and their current limitations. While capable of handling simple distinctions, the complexity inherent in legal reasoning presents clear challenges, necessitating ongoing research to close the gap between current capabilities and the sophisticated reasoning demands of the legal profession. The results advocate for continued refinement of AI models to enhance their capacity for realistic and reliable applications in legal contexts.

