- The paper introduces Pisces, a novel foundation model that decouples image understanding and generation using separate visual encoders.
- It employs tailored projection and pooling strategies to optimize each task, resulting in significant benchmark improvements over specialized models.
- Joint training of image modalities enhances both tasks, and detailed caption pretraining boosts generation performance.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
This paper introduces \modelname{}, a unified multimodal foundation model designed for both image understanding and generation (2506.10395). \modelname{} addresses the limitations of existing multimodal models by employing a novel architecture that decouples visual representations for image understanding and generation, allowing each task to leverage distinct image encoders and projection layers. This approach enables the model to achieve state-of-the-art performance on a wide range of benchmarks, surpassing even specialized models in certain tasks.
Model Architecture and Design
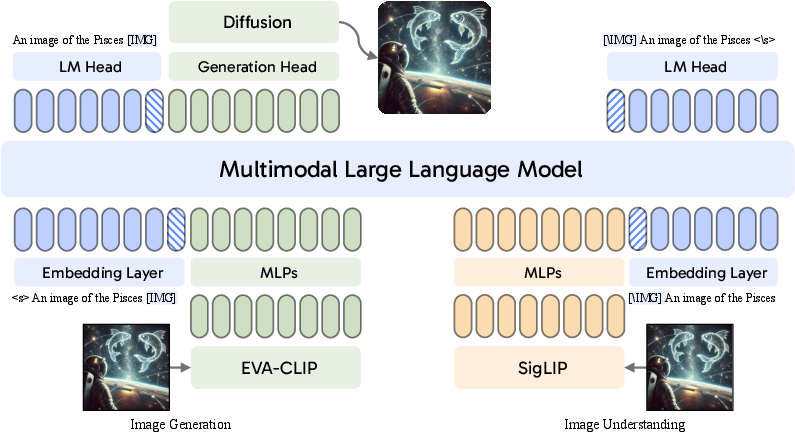
Figure 1: The main architecture of \modelname{}, illustrating separate visual encoders and projection layers for image generation (left) and image understanding (right), sharing the same multimodal LLM.
The architecture of \modelname{} is inspired by recent multimodal models and incorporates a pretrained LLM, separate image encoders for image understanding (ϕ) and image generation (φ), and a diffusion model. A key innovation is the decoupled visual encoding architecture, which recognizes the intrinsic differences between the visual representations needed for image understanding and generation. Image understanding benefits from detailed, semantically rich information extracted from raw images, necessitating a long sequence of image vectors. In contrast, image generation requires compressing pixel-level information into a compact sequence of vectors optimized for autoregressive generation.
For image understanding, the encoder ϕ processes the input image I into a sequence of continuous image representations ϕ(I), which are then projected into the LLM's latent space:
Vn=MLPs(ϕ(I))∈Rn×d
where n is the number of visual tokens, and d is the hidden dimension.
For image generation, the encoder φ processes the image I into a sequence of continuous vectors φ(I). To reduce the computational burden of autoregressively generating long sequences, average pooling is applied to decrease the number of visual tokens:
Vm=MLP(Poola×a(φ(I)))∈Rm×d
where Poola×a denotes 2D pooling with a stride of a, resulting in m tokens.
The LLM manages both tasks through a carefully designed training objective. For image understanding, image vectors Vn are prepended to text embeddings T to create X=[Vn;T], while for image generation, image vectors Vm are appended to text embeddings T, forming X=[T;Vm]. The unified training objective is defined as:
$\mathcal{L} = - \sum^{\mathcal{D} \sum_{i=1}^{N} P_{\theta}(x_i | x_1,x_2,...,x_{n-1})$
where xi represents either a discrete text token or a continuous image vector, and θ represents the parameters of the multimodal LLM. A conditional diffusion model acts as a decoder, reconstructing the image from the predicted visual vectors Vm.
Training Methodology
The training process for \modelname{} is divided into three stages: multimodal pretraining, fine-grained multimodal pretraining, and instruction tuning for image understanding and generation.
- Multimodal Pretraining: The model is pretrained on 150 million high-quality image-caption pairs from Shutterstock for both image captioning and generation. Detailed captions generated by the Llama 3.2 model are used for image understanding.
- Fine-Grained Multimodal Pretraining: The model continues pretraining on 70 million image and detailed caption pairs. This stage enhances alignment between textual tokens and visual features.
- Instruction Tuning: The model is further refined on a curated instruction-tuning dataset comprising 8 million high-quality image-text pairs for image understanding and 4 million image-caption pairs for image generation.
The multimodal LLM is initialized with LLaMA-3.1-Instruct 8B, using siglip-so400m-patch14-384 as the vision encoder for image understanding and a CLIP model trained with MAE reconstruction loss and contrastive loss as the vision encoder for image generation. The SDXL model is used as an image decoder, reconstructing images from gen-CLIP image embeddings.
Experimental Results and Analysis
\modelname{}'s performance was evaluated on a comprehensive set of benchmarks for both image understanding and generation.
Image Understanding
On general multimodal benchmarks, \modelname{} achieves state-of-the-art performance compared to open-source unified models, even outperforming models two to four times larger. For instance, it achieves 26.3\% higher scores on MMBench compared to EMU3 and 8.6\% higher scores on MME-P compared to Seed-X. \modelname{} also excels on domain-specific benchmarks, including vision-centric, knowledge-based, and OCR benchmarks, achieving comparable or superior performance to specialized models.
Image Generation

Figure 2: Qualitative comparison of image generation results, demonstrating \modelname{}'s ability to follow complex user prompts and generate high-quality images.
\modelname{} achieves competitive performance on the GenEval benchmark among unified understanding and generation models, demonstrating its strong instruction-following capabilities in image generation. Qualitative results further illustrate the model's ability to generate high-quality images from complex user prompts.
Synergistic Relationship
Ablation studies reveal a synergistic relationship between image understanding and generation. Training these tasks together within a unified multimodal framework shows that image understanding significantly enhances image generation performance, and conversely, image generation benefits image understanding performance. This is supported by experiments where models trained without either image understanding or image generation tasks show degraded performance.
Benefits of Decoupled Vision Encoders
The effectiveness of using decoupled visual encoders is verified through ablation studies. Using a single encoder (gen-CLIP) for both image understanding and generation results in on-par performance for image generation but inferior image understanding performance. Training SDXL to decode SigLIP features did not achieve the same level of reconstruction performance as Gen-CLIP+SDXL, highlighting the benefit of decoupling image encoders.
Impact of the Number of Visual Tokens
Experiments varying the number of visual tokens for image generation demonstrate that longer sequence lengths pose a significant challenge for LLMs. Reducing the number of visual tokens lowers the training loss, with an intermediate approach of pooling with a stride of 3 providing the best balance between low loss and preserving crucial visual information.
Effect of Detailed Captions on Image Generation
The significance of the second-stage pretraining on detailed captions is illustrated by comparing models trained with short captions versus long captions. Incorporating more short captions does not yield further improvement in the model's FID, whereas using long captions consistently enhances image generation performance.
Conclusion
\modelname{} effectively bridges the gap between image understanding and generation by introducing an asymmetrical visual encoding architecture and task-specific training techniques. The model achieves strong performance across diverse modalities, demonstrating the potential of unified multimodal foundation models. The insights gained from \modelname{} can inspire future research in developing more robust and versatile approaches to multimodal modeling.

