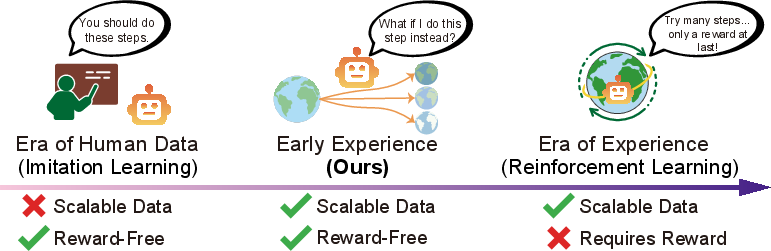
Agent Learning via Early Experience
Abstract: A long-term goal of language agents is to learn and improve through their own experience, ultimately outperforming humans in complex, real-world tasks. However, training agents from experience data with reinforcement learning remains difficult in many environments, which either lack verifiable rewards (e.g., websites) or require inefficient long-horizon rollouts (e.g., multi-turn tool use). As a result, most current agents rely on supervised fine-tuning on expert data, which is challenging to scale and generalizes poorly. This limitation stems from the nature of expert demonstrations: they capture only a narrow range of scenarios and expose the agent to limited environment diversity. We address this limitation with a middle-ground paradigm we call early experience: interaction data generated by the agent's own actions, where the resulting future states serve as supervision without reward signals. Within this paradigm we study two strategies of using such data: (1) Implicit world modeling, which uses collected states to ground the policy in environment dynamics; and (2) Self-reflection, where the agent learns from its suboptimal actions to improve reasoning and decision-making. We evaluate across eight diverse environments and multiple model families. Our approaches consistently improve effectiveness and out-of-domain generalization, highlighting the value of early experience. Moreover, in environments with verifiable rewards, our results provide promising signals that early experience offers a strong foundation for subsequent reinforcement learning, positioning it as a practical bridge between imitation learning and fully experience-driven agents.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “Agent Learning via Early Experience”
1. What is this paper about?
This paper is about teaching smart computer programs, called language agents, to get better at doing tasks by learning from their own actions—without needing a “score” or reward from the environment. The authors propose a new way to train these agents called early experience, which lets them try things, see what happens next, and use those outcomes to improve.
2. What questions are they trying to answer?
The paper aims to answer three simple questions:
- How can we help agents learn from their own actions when there’s no clear reward or score (like many real websites and tools)?
- Can agents improve by watching what happens after they take different actions, even if those actions are not perfect?
- Will this kind of learning make agents more reliable, better at new situations, and a stronger starting point for later training with rewards?
3. How did they do it?
The researchers introduce early experience: the agent tries different actions in the same situation, records what happens next, and uses those “future states” as lessons. Think of it like trying different buttons on a website and learning from the pages that show up.
They explore two training strategies under this idea:
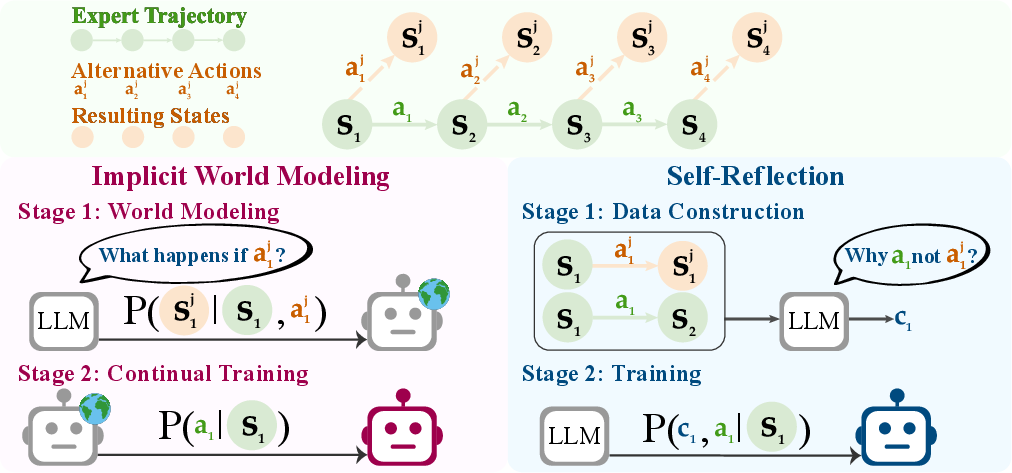
- Implicit World Modeling (IWM): Imagine learning the “rules of the world.” The agent looks at a situation (what it sees on the screen), tries an action (like clicking a button), and practices predicting what will happen next (the next screen or result). This helps the agent build an internal sense of cause and effect—what action leads to what outcome—without needing a reward.
- Self-Reflection (SR): This is like keeping a learning journal. The agent compares the expert’s action (the “good” choice) with its own alternative actions and reads the different outcomes. It then writes a short explanation of why the expert’s action was better. The agent trains on these explanations so it can make smarter decisions next time.
To test these ideas, the authors ran experiments on eight different types of tasks, including:
- Web shopping and browsing
- Using tools over many steps (like APIs or search)
- Planning a multi-day trip
- Simulated science and household tasks
They tried multiple model sizes and families to make sure the results weren’t just a one-off.
4. What did they find, and why is it important?
Across many tasks and models, early experience helped agents more than standard “copy the expert” training.
Here are the main takeaways:
- Better success rates: On average, agents improved by around 9–10 percentage points over standard imitation learning. That’s a meaningful jump across very different tasks.
- Stronger generalization: Agents handled new or changed situations better (called out-of-domain generalization), gaining roughly 9–10 points on average. In simple terms, they didn’t fall apart when the task changed a bit.
- Data efficiency: They could match or beat the baseline even with about half the amount of expert data, which saves time and effort.
- Scales well: The approach works for larger models too—not just small ones.
- Great foundation for later training with rewards: In places where rewards were available, starting from early-experience-trained models led to even better final performance after reinforcement learning, improving by up to about 6 percentage points. So early experience is a strong “warm-up” phase.
Why this matters: Many real-world environments (like websites) don’t give a clear reward or score for every action. Early experience turns “what happens next” into useful learning signals, so agents can improve without needing that score.
5. What’s the bigger impact?
This work offers a practical bridge between two worlds:
- Imitation learning (copying experts), which is easy to start but limited.
- Reinforcement learning (learning from rewards), which can be powerful but is hard to run in many real settings.
By letting agents learn from their own early experiences—predicting outcomes and reflecting on mistakes—this approach makes agents:
- More robust in messy, real environments
- Less dependent on expensive human-made examples
- Better prepared for later, reward-based training
In short, early experience helps build smarter, more independent agents that can improve in the kinds of real tasks we actually care about—even when there’s no scoreboard to guide them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed as concrete directions future work can act on.
- Data coverage limitation: Early experience is collected only around expert-visited states (alternative actions at expert states), leaving exploration of off-expert regions of the state space largely unaddressed; study on-policy rollouts and multi-step autonomous exploration is missing.
- Alternative action sampling: No sensitivity or ablation on the number of alternatives K, sampling temperature, or selection heuristics; evaluate uncertainty/disagreement-driven sampling or diversity-promoting strategies to improve coverage and learning efficiency.
- One-step dynamics only: Implicit world modeling predicts single-step next states; its ability to capture long-horizon dependencies and delayed effects is untested; explore multi-step prediction, rollout consistency, and trajectory-level modeling.
- No inference-time use of the learned model: The implicit world model is not leveraged for planning, lookahead, or value-guided search at inference; quantify whether using the model online improves performance or sample efficiency.
- Missing metrics for model quality: The paper does not report next-state prediction accuracy/calibration or correlate model-prediction loss with downstream task gains; add alignment analyses between auxiliary loss and task outcomes.
- Reflection quality control: Reflections are generated by an LLM without verification; assess rate of hallucinated or incorrect rationales and test automatic or human validation filters and their impact on learning.
- Local (myopic) reflection: Reflections compare immediate next states of expert vs. alternatives; evaluate trajectory-level reflection that reasons over multi-step consequences and long-delayed outcomes.
- Expert bias and noise: The approach presumes expert actions are preferable; robustness when expert demonstrations are suboptimal or inconsistent is not analyzed; probe methods to detect and correct expert errors.
- Cost and efficiency: The environment interaction budget, wall-clock, token/compute cost to collect rollout data, and amortized cost-benefit vs. acquiring more demonstrations or running RL are not reported; provide detailed cost-effectiveness studies.
- Safety and irreversibility: Executing non-expert actions in real environments (e.g., the web) can have side effects; only simulators are used; develop safe exploration protocols, sandboxing, and rollback mechanisms for live settings.
- Scaling limits: Results are shown up to ~8B models; behavior at larger scales (e.g., 30B–70B or MoE) and scaling laws of early experience vs. model size remain unknown.
- Real-world non-stationarity: Evaluation largely avoids dynamic, rate-limited, or adversarial environments (e.g., anti-bot websites, UI redesigns); test robustness under non-determinism, partial observability, and frequent schema/DOM drift.
- OOD stress testing: OOD splits are predefined; no controlled stress tests of domain drift, tool schema changes, retrieval distribution shifts, or UI perturbations; design systematic perturbation suites.
- RL integration depth: Only warm-start benefits are shown; missing learning curves, sample-efficiency gains, stability effects, and final asymptotes across different RL algorithms and reward densities.
- From early experience to rewards/values: Methods for distilling early experience into reward models, value functions, or critics are not explored; investigate learned rewards or preference models derived from reflections/next-state signals.
- Baselines to classic aggregation: No head-to-head comparison with DAgger, dataset aggregation with expert relabeling, scheduled sampling, or HER-style relabeling adapted to language agents; include competitive imitation+exploration baselines.
- Combining IWM and SR: IWM and SR are evaluated separately; joint training, multi-task schedules, curriculum ordering, and loss weighting are unexplored; test whether combining them yields additive or synergistic gains.
- Small gains in open action spaces: Improvements on open, combinatorial action spaces (e.g., WebArena) are modest; perform failure-mode analysis to identify whether action diversity, observation noise, or grounding is the bottleneck.
- Multimodal states: The approach assumes textual state representations; extension to multimodal inputs (screenshots, GUI pixels, DOM+vision) and their effect on IWM and SR is untested.
- Stochasticity and uncertainty: No modeling of environment stochasticity or calibration of predictive uncertainty; explore uncertainty-aware training, ensembling, or distributional modeling to handle noisy/partial observations.
- Exploration bias from initial policy: Alternative actions are sampled from the initial policy, potentially biasing data toward existing mistakes; assess entropy-regularized, curiosity-driven, or disagreement-based exploration to diversify experience.
- Inference-time behavior and latency: SR trains chain-of-thought (CoT); it is unclear whether CoT is required at inference, and its effect on latency, token cost, and success rates is not measured; quantify performance–latency trade-offs.
- Memory and long-horizon credit assignment: No explicit episodic memory or credit assignment beyond one step; evaluate memory-augmented policies and reflection mechanisms that carry over lessons across steps/episodes.
- Tool-use reliability: For API tasks, argument grammar constraints, programmatic validators, and repair loops are not integrated; study synergy with constrained decoding or tool-grounded verification during training and inference.
- Metrics beyond success/F1: Calibration, safety violations/side effects, number of steps to solve, and action efficiency are not reported; broaden evaluation to reflect practical deployment criteria.
- Variance and reproducibility: Confidence intervals, seed variability, and run-to-run variance under environment stochasticity are not presented; report statistical robustness and sensitivity to random seeds.
- Privacy/compliance: Storing and training on raw next states (e.g., web content) can raise privacy or policy issues; establish data handling, redaction, and compliance procedures for early-experience logs.
Practical Applications
Immediate Applications
The following are concrete, deployable use cases that leverage the paper’s early experience paradigm—Implicit World Modeling (IWM) and Self-Reflection (SR)—to improve language agents without requiring verifiable reward signals.
- Sector: E-commerce (WebShop-like sites)
- Use case: Shopping assistants that reliably honor user constraints (budget, color, size) and adapt to site changes by learning from their own clicks and error messages.
- Tools/products/workflows: “Early Experience Collector” (logs action→next-state traces), IWM pretraining stage, SR-based rationale generator for constraint satisfaction.
- Assumptions/dependencies: Access to DOM/state snapshots or textual page states; sandboxed interaction to avoid unintended purchases; seed expert demos to anchor learning.
- Sector: Customer Support and Operations (Tau-Bench, BFCL-like API orchestration)
- Use case: Policy-compliant support agents that improve tool sequencing and argument selection by reflecting on suboptimal tool calls.
- Tools/products/workflows: SR training for policy adherence, “Tool-Use Correctness Validator” to compare expert vs. alternative tool calls; experience replay pipeline across APIs.
- Assumptions/dependencies: API availability with instrumented logs; access to policy documents; safe test environments for exploration.
- Sector: Enterprise RPA (web and desktop automation)
- Use case: Agents that robustly automate repetitive workflows (form filling, data entry, report generation) by grounding policies in predictable environment transitions (IWM) and learning recovery strategies (SR).
- Tools/products/workflows: IWM warm-up on interaction logs; SR mixed with imitation data; “Early Experience MLOps” pipeline to continuously ingest and train on internal agent traces.
- Assumptions/dependencies: Instrumented UI/DOM accessibility trees or structured app states; reversible actions; change-management and safety gates.
- Sector: Search and Knowledge Work (SearchQA)
- Use case: Query refinement assistants that explore multiple search queries, observe retrieval outcomes, and improve answer quality without external supervision.
- Tools/products/workflows: Early-experience rollouts of alternative queries; SR for reasoning about retrieved snippets; OOD evaluation harness.
- Assumptions/dependencies: Stable retrieval APIs; logged query→result traces; initial demonstration data for task anchoring.
- Sector: Travel and Planning (TravelPlanner)
- Use case: Itinerary planners that learn long-horizon constraint handling (e.g., budget, travel time, venue availability) by reflecting on plan revisions and failed steps.
- Tools/products/workflows: SR curriculum on exploratory plan variants; IWM to internalize typical planning transitions; “Constraint-aware planning trainer.”
- Assumptions/dependencies: Access to planning tools/data; instrumented next-state descriptions; seeded expert plans.
- Sector: Scientific/Technical Simulation (ScienceWorld)
- Use case: Procedure assistants that learn experimental steps from textual lab outputs, reducing reliance on fully optimal demonstrations.
- Tools/products/workflows: IWM pretraining on state transitions (tool outputs, materials states); SR for selecting optimal action sequences.
- Assumptions/dependencies: Simulators producing textual next states; curated initial demos; safe exploration budgets.
- Sector: Software Development (agent-enabled testing and QA)
- Use case: Agent test harnesses that build robustness by systematically executing non-expert actions and learning from observed failures.
- Tools/products/workflows: “Rollout Dataset Builder” (state-action-next-state triples), regression detection via reflective rationales; IWM as pre-deployment stabilization.
- Assumptions/dependencies: CI/CD integration; instrumented environments; compute budget for next-token training.
- Sector: RL Engineering (for tasks with verifiable rewards)
- Use case: Stronger RL warm-starts using early experience checkpoints that carry over gains in success rates and stability.
- Tools/products/workflows: RL recipes initialized with IWM/SR models; reward instrumentation only where feasible; “Early→RL bridge” workflow.
- Assumptions/dependencies: Reliable reward functions; simulators or controlled environments; continuity between early-experience and RL state/action formats.
- Academia (agent research groups)
- Use case: Scalable, reward-free training setups that improve effectiveness and OOD generalization across diverse benchmarks without heavy human data reliance.
- Tools/products/workflows: Shared pipelines for IWM and SR; OOD split evaluators; dataset mixers for expert + reflective corpora.
- Assumptions/dependencies: Access to open benchmarks; reproducible environment resets; transparent logging and data governance.
- Policy and Governance (model risk management)
- Use case: Auditable learning from agent-generated traces to reduce dependence on human-labelled data, with clear rationales for decisions (via SR).
- Tools/products/workflows: “Experience-driven audit ledger” storing action→outcome→reflection; governance dashboards tracking error modes and improvements.
- Assumptions/dependencies: Data retention policies; privacy-safe logging; approval flows for exploration in production-like environments.
- Daily life (personal assistants)
- Use case: Assistants that learn from early mistakes when filling forms, scheduling, or shopping—becoming more reliable without explicit user feedback loops.
- Tools/products/workflows: Local “Early Experience Cache” of interactions; SR rationales to avoid repeated errors; lightweight IWM on the user’s apps.
- Assumptions/dependencies: Opt-in user logging; safe execution mode; simple textualization of app states (or UI accessibility extraction).
Long-Term Applications
The following use cases extend the paradigm to higher-stakes domains, broader automation, and continuously learning systems; they typically require further research, scaling, safety tooling, and standardization.
- Sector: Healthcare (clinical operations and EMR navigation)
- Use case: Agents that learn EMR workflows (prior authorization, chart assembly) from interaction traces without needing reward functions, improving reliability and reducing burden.
- Tools/products/workflows: EMR “Early Experience Instrumentation,” SR for policy compliance (HIPAA, consent), IWM for predictable UI transitions.
- Assumptions/dependencies: Strong privacy controls; sandboxed EMR copies; robust UI textualization; human-in-the-loop approvals.
- Sector: Finance (back-office automation, KYC/AML compliance)
- Use case: Compliance-first agents that develop dependable tool sequences and documentation rationales from their own traces.
- Tools/products/workflows: SR-generated rationales embedded in audit artifacts; IWM for platform change resilience; continuous experience replay.
- Assumptions/dependencies: Strict auditability; reversible actions; risk controls; regulator-aligned logging standards.
- Sector: Robotics and Embodied AI
- Use case: Household/service robots that internalize environment dynamics through implicit world modeling, gradually transitioning to real-world data from early, safe interactions.
- Tools/products/workflows: Sim-to-real pipelines augmented with early experience; curriculum learning over alternative actions; reflective correction of suboptimal behaviors.
- Assumptions/dependencies: High-fidelity simulators; safe exploration constraints; multimodal state capture beyond text (vision→language bridges).
- Sector: Education (adaptive tutoring across LMS platforms)
- Use case: Tutors that refine their instructional strategies and platform navigation by reflecting on multi-step interactions and student outcomes (even without explicit reward signals).
- Tools/products/workflows: LMS instrumentation for next-state capture; SR for pedagogical rationales; IWM to stabilize across LMS variants.
- Assumptions/dependencies: Privacy-compliant logging; content/assessment integrations; careful evaluation of learning efficacy.
- Sector: Energy and Industrial Operations
- Use case: Operator assistants that learn control-panel workflows, data dashboards, and alert triage sequences from exploratory interactions in simulators before deployment.
- Tools/products/workflows: Experience-driven simulators; IWM for process regularities; SR to codify decision criteria and safety protocols.
- Assumptions/dependencies: High-fidelity digital twins; stringent safety gates; approval loops; structured state textualization.
- Cross-domain Continuous Learning (“Era of Experience” agents)
- Use case: Agents that continuously collect, curate, and learn from their own early experience, then periodically transition to RL where rewards exist.
- Tools/products/workflows: “AgentOps” platforms combining experience collection, reflection synthesis, IWM pretraining, RL fine-tuning, and OOD monitoring.
- Assumptions/dependencies: Standardized experience data schemas; scalable storage/indexing; governance over continual updates; drift detection.
- Experience Data Standards and Ecosystem
- Use case: Interoperable formats for state-action-next-state traces and reflective rationales to enable shared corpora and tooling across vendors and research labs.
- Tools/products/workflows: Open standards for “Future State Logs,” reflection metadata, and safety labels; libraries for ingestion and training.
- Assumptions/dependencies: Community coordination; privacy and IP policies; benchmark evolution to support reward-free learning.
- Safe Exploration Frameworks
- Use case: Formal guardrails for reward-free exploratory actions (rollback, containment, intent filters) enabling broader adoption in regulated settings.
- Tools/products/workflows: “Exploration Scheduler” with risk tiers; automatic rollback and diffing; SR to capture decision trade-offs for audits.
- Assumptions/dependencies: Policy definitions; tooling for reversible execution; robust anomaly detection.
- Auto-curriculum Generation
- Use case: Systems that transform early experience failures into new training tasks and subgoals, improving coverage of rare states and long-horizon dependencies.
- Tools/products/workflows: Curriculum builders that mine reflective rationales; task synthesizers for practice on failure modes; staged IWM/SR training.
- Assumptions/dependencies: Reliable failure detection; scalable synthesis pipelines; careful curation to avoid spurious curricula.
- Human-in-the-loop Oversight and Governance
- Use case: Combining SR rationales with expert review to build validated “lesson libraries” that guide agents in high-stakes domains.
- Tools/products/workflows: Reviewer dashboards; rationale scoring; escalation workflows; continuous improvement cycles.
- Assumptions/dependencies: Expert availability; compensation and workflow design; integration with compliance teams.
- Marketplace for Experience-Augmented Datasets
- Use case: Shared repositories of anonymized early-experience traces and reflection corpora to accelerate development across sectors.
- Tools/products/workflows: Data cleaning and de-identification; licensing; evaluation suites for OOD robustness.
- Assumptions/dependencies: Legal frameworks; quality controls; standardized benchmarks and validators.
- Multimodal Extensions (text+vision+UI)
- Use case: Extending early experience to rich UI and visual states by converting them into textual summaries or structured representations for IWM/SR training.
- Tools/products/workflows: Vision-to-language converters; accessibility-tree summarizers; multimodal tokenization strategies.
- Assumptions/dependencies: High-quality perceptual models; consistent summarization; careful handling of large, noisy state spaces.
Glossary
- Accessibility trees: Structured representations of webpage elements used by assistive technologies; here, they serve as a detailed web-state format for agents. "WebArena presents noisy, fine-grained web states as accessibility trees, requiring reasoning over hundreds of DOM-like elements."
- Action space: The set of all actions available to an agent in an environment. "Across our eight environments, the action spaces fall into three regimes."
- Behavior cloning: A supervised learning approach that trains a policy to mimic expert actions. "Most language agents are trained with SFT, also known as imitation learning or behavior cloning in the RL literature, on expert trajectories..."
- Chain-of-thought: A natural-language reasoning trace generated by an LLM; used as a training target to improve decision-making. "We then prompt a LLM to generate a chain-of-thought explaining why the expert action is preferable to the alternative ..."
- Credit assignment: The process of determining which actions in a sequence led to an outcome, for allocating learning signal. "making credit assignment and training inefficient and unstable."
- Discount factor: A scalar in RL that downweights future rewards relative to immediate ones. " is the discount factor, and specifies the initial state distribution."
- Distribution shift: A mismatch between training and deployment distributions that causes performance degradation. "However, this approach suffers from distribution shift and lacks awareness of action consequences."
- DOM (Document Object Model): A tree-structured representation of webpage elements and content used to reflect changes in web environments. "reflecting changes in the environment such as updated DOM structures, new tool outputs, error messages, or task progression."
- Early experience: Agent-generated interaction data whose future states serve as supervision without explicit rewards. "early experience: interaction data generated by the agent's own actions, where the resulting future states serve as supervision without reward signals."
- Exploration–exploitation: The RL trade-off between trying new actions and using known ones that yield reward. "Traditional explorationâexploitation strategies in RL collect trajectories that are later refined through reward feedback."
- Hindsight Experience Replay: An RL technique that relabels outcomes as goals to densify sparse rewards. "Methods like Hindsight Experience Replay densify sparse rewards by retrofitting achieved outcomes as goals..."
- Imitation learning: Training a policy via supervised learning on expert state–action pairs, without using rewards. "Most language agents are trained with SFT, also known as imitation learning or behavior cloning in the RL literature..."
- Implicit world modeling: An auxiliary training objective where the policy predicts next states from state–action pairs to internalize environment dynamics. "Implicit world modeling (left) augments expert trajectories with alternative actions and predicted next states, training the policy to internalize transition dynamics before deployment."
- Initial state distribution: The probability distribution over starting states in an MDP. " specifies the initial state distribution."
- Long-horizon rollouts: Extended interaction sequences with delayed outcomes, often making learning inefficient. "require inefficient long-horizon rollouts (e.g., multi-turn tool use)."
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, transitions, rewards, and discounting. "We formalize the language agent decision-making problem as a Markov Decision Process (MDP;~\cite{bellman1957markovian}), which provides the mathematical foundation for our early experience paradigm."
- Next-token prediction loss: A language modeling objective used here to train state or rationale prediction. "We define the training objective as a next-token prediction loss:"
- Out-of-domain (OOD): Test or deployment settings that differ from the training distribution. "we explore early experience in environments with out-of-domain (OOD) splits, using the same checkpoints..."
- Out-of-domain generalization: The ability of a model to perform well on OOD tasks or distributions. "improve task effectiveness, out-of-domain generalization, and downstream reinforcement learning performance"
- Policy: A mapping from states to a distribution over actions that governs agent behavior. "The agent maintains a policy , parameterized by , which maps states to action distributions"
- Probability simplex: The set of all probability distributions over a discrete set. " denotes the probability simplex over ."
- Reinforcement learning (RL): Training agents to maximize expected cumulative reward through interaction with an environment. "one promising solution is reinforcement learning (RL), where agents are trained by optimizing for expected cumulative reward returned by the environment."
- Reward function: A function that provides scalar feedback signals given a state and action. "The reward function provides feedback signals when available"
- Self-reflection: Training agents to analyze and learn from their own suboptimal actions and resulting states through generated rationales. "Self-reflection (right) augments expert actions with self-generated explanations , training the policy to reason about and revise its own decisions."
- State space: The set of all possible states an environment can present to the agent. " denotes the state space and represents the action space."
- Supervised fine-tuning (SFT): Updating a model on labeled data using supervised objectives, often on expert trajectories. "Most current language agents are instead trained on expert-curated data with supervised fine-tuning (SFT;~\cite{Deng2023Mind2web, pahuja2025explorer, Prabhakar2025XLAM})."
- Transition function: The stochastic mapping from a state and action to a distribution over next states. "The transition function governs state dynamics"
- Verifiable rewards: Reliable reward signals provided by the environment that can be checked or measured. "which either lack verifiable rewards (e.g., websites) or require inefficient long-horizon rollouts (e.g., multi-turn tool use)."
- World models: Models that predict future states (and possibly rewards) based on observed transitions, aiding planning or learning. "World models~\citep{sutton1991dyna,ha2018world,Hafner2020Dreamv1,hafner2021dreamerv2} are traditionally trained on observed state transitions to predict future states and rewards"
Collections
Sign up for free to add this paper to one or more collections.