IASC: Interactive Agentic System for ConLangs
Abstract: We present a system that uses LLMs as a tool in the development of Constructed Languages. The system is modular in that one first creates a target phonology for the language using an agentic approach that refines its output at each step with commentary feedback on its previous attempt. Next, a set of sentences is 'translated' from their English original into a morphosyntactic markup that reflects the word order and morphosyntactic feature specifications of the desired target language, with affixes represented as morphosyntactic feature bundles. From this translated corpus, a lexicon is constructed using the phonological model and the set of morphemes (stems and affixes) extracted from the 'translated' sentences. The system is then instructed to provide an orthography for the language, using an existing script such as Latin or Cyrillic. Finally, the system writes a brief grammatical handbook of the language. The system can also translate further sentences into the target language. Our goal is twofold. First, we hope that these tools will be fun to use for creating artificially constructed languages. Second, we are interested in exploring what LLMs 'know' about language-not what they know about any particular language or linguistic phenomenon, but how much they know about and understand language and linguistic concepts. As we shall see, there is a fairly wide gulf in capabilities both among different LLMs and among different linguistic specifications, with it being notably easier for systems to deal with more common patterns than rarer ones. An additional avenue that we explore is the application of our approach to translating from high-resource into low-resource languages. While the results so far are mostly negative, we provide some evidence that an improved version of the present system could afford some real gains in such tasks. https://github.com/SakanaAI/IASC
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a step-by-step, interactive system that helps people create constructed languages (ConLangs) using LLMs. Think of it like building your own imaginary language in phases: picking sounds, deciding grammar rules, inventing word spellings, and writing a short grammar guide. The system is designed to be fun and flexible for creators, and it also lets researchers test what LLMs understand about how languages work.
Objectives and Research Questions
The paper has two main goals:
- Build a practical, modular tool that helps users design ConLangs with real language-like features, while keeping the creator in control.
- Use that tool to explore what LLMs “know” about language—not about specific languages like French or Japanese, but about general ideas like word order, case marking, and tense.
The authors ask simple but important questions:
- Can LLMs follow detailed grammar instructions, like changing word order or adding endings to show tense or number?
- Are LLMs better at common patterns (like English-like grammar) than rare ones?
- Can this approach help with translating into low-resource languages (languages with limited data)? The early answer is mostly “not yet,” but there’s potential.
Methods and Approach
How the system works
The system builds a ConLang in five main steps:
- Phonology and phonotactics: Choose the set of sounds and the rules for how they can be combined.
- Morphosyntax: Convert English sentences into a structured “gloss” that marks grammar features (like case, number, tense) and word order for the target language.
- Lexicon: Create the word list (stems and affixes) by matching the grammar annotations to sound patterns.
- Orthography: Pick how the language is written (e.g., Latin letters, Cyrillic).
- Grammar guide and naming: Generate a short handbook with rules, examples, and a name for the language.
At each step, the LLM proposes something, gets feedback, and improves its output—like a student iteratively revising homework after comments from a teacher.
Phonotactics (sound patterns)
Phonotactics are the “sound-building rules” of a language—what sounds exist and how they can combine. For example, Hawaiian allows simple syllables; Russian allows complex clusters.
- The system prompts an LLM to write a small Python program that generates morphemes (basic meaningful pieces of words) matching the target language’s sound patterns.
- It tests the program’s outputs and asks the LLM to refine its code if important sounds are missing or the output is unrealistic. Example: for Welsh, it added a distinctive sound, the voiceless lateral fricative (written as “ll” in Welsh, IPA /ɬ/).
- It checks the quality by comparing the generated morphemes to real-language patterns using a statistic called “perplexity.” Lower perplexity means the generated sounds fit the target language better. The test uses 3‑gram models over IPA (a standard system to write sounds) built from Wiktionary data.
Analogy: Phonotactics is like deciding which LEGO bricks you have and which shapes you’re allowed to build.
Morphosyntax (word forms and sentence structure)
Morphosyntax combines morphology (word parts like prefixes/suffixes) and syntax (word order).
- The system doesn’t directly invent “final translated sentences.” Instead, it creates interlinear glosses—clean, labeled versions of sentences that mark features like:
- Case (who’s doing what to whom), e.g., nominative, accusative, ergative, absolutive.
- Number (singular, dual, plural, paucal).
- Person (first, second, third).
- Tense/aspect (past, present, future, perfect, etc.).
- Word order (SOV, SVO, VSO, etc.).
- Extras like inclusive/exclusive “we” (whether “we” includes the listener).
- The system applies these features in steps (“cumulative morphosyntax”). For example, first change word order, then add case markers, then add tense—one feature at a time—so the LLM doesn’t get confused by a huge instruction list.
Analogy: It’s like editing a sentence layer-by-layer: first shuffle the words, then add grammatical labels, then add endings.
Evaluation setup
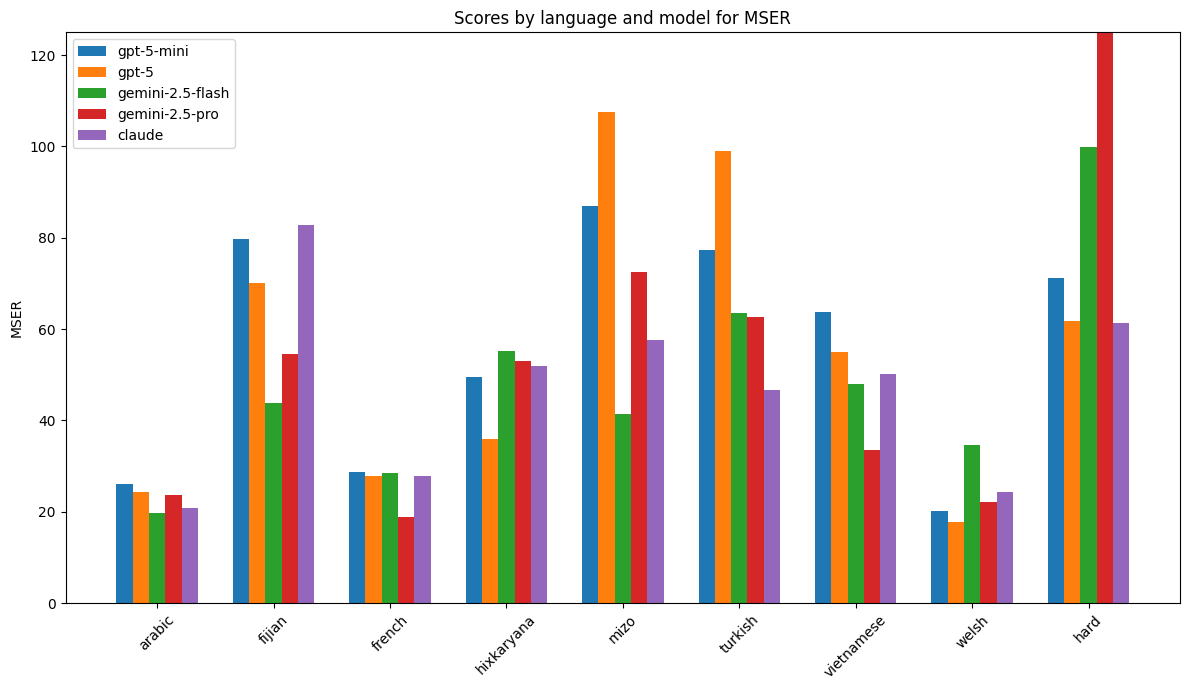
- The authors built a set of 45 English sentences and 9 different feature sets inspired by typologically diverse languages (like Arabic, Fijian, Hixkaryana, Mizo, Turkish, Vietnamese, Welsh, French).
- They also wrote short stories and targeted sentence lists to test specific grammar ideas (e.g., examples that force inclusive vs. exclusive “we”).
- For phonotactics, they compared outputs against 49 languages with enough IPA data.
Main Findings and Why They Matter
- The system can guide LLMs to help build realistic ConLang components with human feedback at each step. This gives creators control while harnessing AI’s speed and breadth.
- LLMs vary in quality. In phonotactics tests:
- Claude 3.5 Sonnet did best; it matched the target language’s sound patterns most often (top match in 4/10 cases, and within the top-10 in 5/10).
- GPT‑4o, Qwen2.5, and Llama 3.3 did worse.
- LLMs tend to handle common, well-documented patterns better than rare or unusual ones.
- Technical detail matters: matching generated sounds to Wiktionary data depends on how finely the sounds are written. For instance, Japanese entries in Wiktionary use very detailed IPA (more “micro” sounds), which can penalize models that generate simpler, more “phoneme-level” outputs.
- Early tests on using this approach for helping translation into low-resource languages were mostly negative, but the authors saw hints that improved versions could help.
Why it matters:
- It shows LLMs have usable “metalinguistic” knowledge (knowledge about language as a system), but their strengths are uneven.
- The modular approach is a practical way to probe and improve AI’s grasp of grammar.
Implications and Potential Impact
- For creators: This is a fun, flexible tool for making deep, realistic ConLangs—like a guided studio where you set the rules and the AI fills in details you can refine.
- For linguistics and AI research: The system is a testbed to measure what LLMs understand about language structure. It can reveal gaps (e.g., struggles with unusual case systems or complex morphology) and suggest how to train better models.
- For low-resource languages: While current results are limited, the idea of using grammar-aware prompts to steer LLMs may help future systems support languages with little data.
- For education: The step-by-step, labeled approach can teach grammar concepts through hands-on creation.
Code is released, so others can try, test, and build on the system: https://github.com/SakanaAI/IASC
Helpful mini glossary
- Phonology/phonotactics: What sounds a language uses and how they can combine.
- Morphology: How words change form (like adding endings to mark tense or number).
- Syntax: How words are ordered in sentences.
- Case: Labels showing roles in a sentence (subject, object). Nominative–accusative vs. ergative–absolutive are two major systems for marking these roles.
- Inclusive/exclusive “we”: Whether “we” includes the person you’re talking to.
- Interlinear gloss: A line-by-line breakdown of a sentence showing grammar features.
- Perplexity: A measure of how well generated text fits a model. Lower is better.
- IPA: A standard alphabet for writing speech sounds across languages.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions, written to guide actionable future work.
- Phonotactic evaluation relies on 3-gram models trained on Wiktionary IPA transcriptions with heterogeneous transcription granularity across languages; a standardized, phoneme-level dataset and normalization protocol are needed to avoid confounds from fine vs. coarse-grained IPA.
- Only 10 target languages are tested for phonotactic similarity (with a top-10 perplexity check); scaling to a larger, typologically diverse set and reporting statistical significance (and variance across runs/seeds) is missing.
- The perplexity-based metric for phonotactic match conflates inventory and syllable-structure differences; alternative metrics (e.g., distributional similarity of phoneme inventories, syllable templates, sonority profiles, cluster distributions) and human judgments are not explored.
- The phonotactic generator enforces simple space-separated phoneme outputs and basic cluster functions; syllabification, sonority sequencing, positional constraints, and prosodic structure are not modeled or evaluated.
- The “phonological rule set” module is not integrated; there is no quantitative or qualitative evaluation of rule plausibility or their effects on generated morphemes and downstream modules.
- Morphosyntax module lacks reported quantitative results: there is no accuracy, consistency, or error analysis per feature (e.g., word order, case, number, tense–aspect, agreement), nor any human or expert evaluation.
- The cumulative vs. single-pass morphosyntactic transformation is only anecdotally motivated; a systematic comparison (accuracy, robustness, error propagation across stages, cost/latency) is missing.
- Error propagation in the cumulative approach is not tracked; there is no mechanism to detect, diagnose, or correct compounding errors across iterative transformations.
- Detection/assignment of features absent in English surface forms (e.g., inclusive/exclusive “we,” definiteness, evidentiality, switch-reference, mood distinctions) is unspecified; rigorous extraction strategies, heuristics, or semantic parsing requirements are not defined or validated.
- The morphosyntax feature set has constrained typological coverage: no support for infixes, circumfixes, templatic morphology (e.g., Semitic roots-and-patterns), clitics, reduplication, tone, vowel harmony, case stacking, split ergativity, polypersonal agreement, noun class/gender systems, incorporation, or switch-reference.
- Case-marking strategies are simplified to prefix/suffix/pre-/postpositional words; clitic particles, enclitic case markers, head vs. dependent marking interactions, and alignment splits are not modeled.
- The interlinear glossing schema uses ad hoc abbreviations; standardization to existing conventions (e.g., Leipzig Glossing Rules, UniMorph tags) and explicit mappings are not provided.
- The construction of the lexicon from morphosyntactic translations is under-specified and unevaluated: handling of homophony, synonymy, polysemy, allomorphy, derivational morphology, and paradigm completeness is not addressed.
- Orthography assignment (Latin/Cyrillic or other scripts) is not evaluated for grapheme–phoneme consistency, diacritic policies, readability, typographic constraints, or script-specific conventions; novel script design is unexplored.
- Grammar handbook generation is not assessed for internal consistency, faithfulness to defined grammar G, coverage of paradigms, and alignment with actual generated sentences; no human-linguist evaluation is reported.
- End-to-end consistency across modules (phonotactics → lexicon → morphosyntax → orthography → handbook → translation) is not measured; there is no automated consistency checker or cross-module validation.
- The English-only source texts introduce an English-centric bias; applicability to other source languages (especially morphologically rich or typologically distant ones) is not evaluated.
- The curated dataset (16 stories, 45 sentences × 9 grammars) is small and model-generated; a larger, publicly released set with gold glosses and diverse linguistic phenomena is needed for robust benchmarking.
- The extraction of features like DUAL from English (e.g., “two towers”) is informal; formal rules or models for numerical, quantificational, and semantic feature detection (including vague or implicit quantities) are missing.
- Low-resource translation application is only mentioned with “mostly negative” preliminary results; details (languages, tasks, baselines, metrics, ablations) and controlled experiments on grammar-informed prompting or constrained decoding are absent.
- The impact of different prompting strategies (chain-of-thought, self-refinement, tool-use, code execution, verifier agents) on linguistic correctness is not studied via ablations.
- LLM comparison is limited (Claude, GPT-4o, Qwen2.5, Llama 3.3) and informal; prompt sensitivity, reproducibility across runs/seeds, model-size effects, and training-data influence are not investigated.
- Agentic refinement lacks convergence criteria, stopping rules, and principled iteration scheduling; automated validation hooks and corrective feedback mechanisms are not defined.
- OOV filtering and selection of Wiktionary languages may bias evaluation; alternative IPA resources, normalized pipelines, and checks for transcription consistency are not used.
- The claim that the system can translate further sentences into the target language is not backed by quantitative translation-quality evaluation (accuracy vs. grammatical specification, fluency, consistency).
- The formal specification of grammar G (feature interactions, constraints, conflict resolution when features co-occur or clash) is not fully defined; a schema with validation and constraint-solving is needed.
- Scalability, compute cost, and latency of the full agentic pipeline (code generation, iterative refinement, multi-stage morphosyntax) are not measured; practical deployment considerations are unaddressed.
- Ethical and licensing considerations for the generated datasets and language artifacts (stories, glosses, lexicons) are not discussed, including provenance, intended use, and user control in creative outputs.
Glossary
- Ablative: A grammatical case often marking separation, source, or means. "ablative"
- Absolutive: The case that marks intransitive subjects and transitive direct objects in ergative languages. "absolutive"
- Active: A voice where the subject performs the action. "active"
- Adposition: A relational function word (preposition or postposition) that links nouns to other elements. "adposition_noun_word_order"
- Adjective agreement: Morphological agreement where adjectives inflect to match features of the nouns they modify. "adjective_agreement"
- Affix: A bound morpheme attached to a stem to encode grammatical information. "with affixes represented as morphosyntactic feature bundles (e.g. 3SGERG for a third singular ergative marker)"
- Agentic approach: An iterative, self-refining method where an LLM acts as an agent to improve its own outputs. "using an agentic approach that refines its output at each step"
- Aspect: A grammatical category describing the temporal structure of an event (e.g., completed vs. ongoing). "tense--aspect"
- Case: Morphological marking that encodes the syntactic or semantic role of a noun phrase. "modify the case-marking system"
- Chain-of-Thought: An LLM prompting strategy that encourages explicit step-by-step reasoning. "Chain-of-Thought and other `thinking' strategies"
- Comparative: A degree of comparison indicating that one entity exceeds another in some property. "comparative"
- ConLang: A constructed language designed to resemble natural language in expressiveness and structure. "ConLangs"
- Constructed Language: An artificially created language intended to be as expressive as natural languages. "The term \"Constructed Language\"—often shortened to \"ConLang\"—is used"
- Conditional: A mood expressing hypothetical or contingent situations. "conditional"
- Dative: A case often marking indirect objects or recipients. "dative"
- Definiteness: A grammatical feature distinguishing specific/identified referents from non-specific ones. "definiteness"
- Dependent-marking: Marking grammatical relations on dependents (e.g., nouns) rather than on heads. "dependent-marking"
- Dual: A grammatical number category referring to exactly two entities. "dual"
- Equative: A degree of comparison indicating equality of some property. "equative"
- Ergative: A case marking subjects of transitive verbs in ergative-absolutive systems. "ergative"
- Ergative-absolutive: A case alignment where transitive subjects are ergative and intransitive subjects/objects are absolutive. "ergative-absolutive"
- Genitive: A case often marking possession or association. "genitive"
- Gloss: A morpheme-by-morpheme annotation scheme using abbreviated labels for features. "is called a gloss"
- Head-final: A syntactic configuration where heads follow their dependents (e.g., verb at clause end). "head-final"
- Head-initial: A syntactic configuration where heads precede their dependents (e.g., verb at clause start). "head-initial"
- Head-marking: Marking grammatical relations on heads (e.g., verbs) rather than on dependents. "head-marking"
- Indicative: A mood used for stating facts or making assertions. "indicative"
- Infinitive: A non-finite verb form often used to express actions in a general or abstract way. "infinitive"
- Instrumental: A case marking the means or instrument by which an action is performed. "instrumental"
- Interlinear gloss: A structured line-by-line annotation of sentences showing morpheme-level analysis. "given in the form of an interlinear gloss"
- IPA (International Phonetic Alphabet): A standardized system for phonetic transcription of speech sounds. "IPA transcriptions"
- Locative: A case marking location or spatial relations. "locative"
- Low-resource language: A language with limited available data for training computational models. "low-resource languages"
- Mood: A grammatical category expressing modality such as factuality, commands, or hypotheticals. "mood"
- Morphology: The study of word structure and the formation of words from morphemes. "Morphology addresses how a word is structured"
- Morpheme: The minimal meaningful unit of language (e.g., stems, prefixes, suffixes). "morpheme"
- Morphosyntax: The combined study of how grammatical information is marked on words (morphology) and how words are arranged (syntax). "The term \"morphosyntax\" denotes the linguistic study of grammar"
- N-gram LLM: A probabilistic model predicting tokens based on the previous n−1 tokens. "3-gram LLMs"
- Nominal number: Number features expressed on nouns (e.g., singular, dual, paucal, plural). "nominal_number"
- Nominative: A case typically marking the subject of a clause. "nominative"
- Nominative-accusative: A case alignment marking all subjects nominative and direct objects accusative. "nominative-accusative"
- Nonpast: A tense category covering present and future reference without past. "nonpast"
- Orthography: The conventional writing system or script used to represent a language. "provide an orthography for the language"
- OOV (Out-of-Vocabulary): Tokens or symbols not present in the model’s known vocabulary. "OOV symbols"
- OVS: A typological word order where Object precedes Verb and Subject. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- OSV: A typological word order where Object precedes Subject and Verb. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- Passive: A voice where the patient/theme is promoted to subject and the agent is demoted or omitted. "passive"
- Paucal: A number category denoting a few entities (more than two, fewer than many). "paucal"
- Perfect: An aspect indicating a completed action with relevance to the present state. "perfect"
- Perplexity: A measure of how well a probability model predicts a sample; lower means better fit. "compute the perplexity"
- Phoneme: The minimal contrastive unit of sound in a language. "phoneme"
- Phoneme inventory: The set of distinct phonemes used in a language. "phoneme inventory"
- Phonology: The study of sound systems and patterns in languages. "phonology"
- Phonotactics: Constraints governing permissible sequences of phonemes in a language. "phonotactics"
- Platykurtosis: A statistical property indicating fewer extreme values (outliers) than a normal distribution. "platykurtosis"
- Postposition: An adposition that follows its complement (noun phrase). "postpositional word"
- Recent past: A tense/aspect category referring to events shortly before the reference time. "recent past"
- Relativization: The grammatical process of forming relative clauses modifying nouns. "Relativization"
- Relativizer: A morpheme or word introducing a relative clause. "relativizer_morpheme"
- Remote past: A tense/aspect category indicating events far before the reference time. "remote past"
- SOV: A typological word order where Subject precedes Object and Verb. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- SVO: A typological word order where Subject precedes Verb and Object. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- Subjunctive: A mood used for irrealis contexts like wishes, doubts, or hypotheticals. "subjunctive"
- Superlative: A degree of comparison indicating the highest degree of a property. "superlative"
- Tense: A grammatical category encoding time reference (past, present, future). "Languages mark various kinds of tense information on verbs"
- Typologically unusual: Patterns that are rare across the world’s languages. "typologically unusual"
- VOS: A typological word order where Verb precedes Object and Subject. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- VSO: A typological word order where Verb precedes Subject and Object. "Literal[\"SOV\", \"SVO\", \"VSO\", \"VOS\", \"OSV\", \"OVS\"]"
- Voice: A verbal category indicating the relation between participants and the verb (e.g., active, passive). "voice"
- WALS (World Atlas of Language Structures): A database of cross-linguistic structural features and their distributions. "The World Atlas of Language Structures \citep{WALS}"
- Zipf’s Law: A power-law distribution commonly observed in word frequencies in natural language. "Zipf's Law"
Practical Applications
Immediate Applications
Below is a concise set of practical use cases that can be deployed now, leveraging the paper’s modular, agentic ConLang pipeline (phonotactics → morphosyntax → lexicon → orthography → grammar handbook → translation), its evaluation approach, and released code.
- ConLang prototyping for media production (entertainment, gaming)
- Tools/workflows: “ConLang Studio” pipeline that rapidly generates a language sketch with consistent phonotactics, orthography (Latin/Cyrillic), lexicon, and a brief grammar handbook; an internal translation utility for script lines; asset handoffs to localization pipelines.
- Assumptions/dependencies: Requires LLMs with sufficient context length and stable prompt adherence; human linguistic review for internal consistency and cultural sensitivity; production workflows must accept AI-generated glosses and scripts.
- Indie author and tabletop RPG language creation (publishing, creative tools)
- Tools/workflows: Plugin for writing apps (e.g., Scrivener) to produce names, phrases, and grammatical notes; a workflow to iteratively refine phonotactics and morphosyntax for specific settings.
- Assumptions/dependencies: Consistency checks across narrative arcs; simple post-editing to avoid typological “uncanny valley”; licensing clarity for AI-generated languages.
- Linguistics education and courseware (education)
- Tools/workflows: Classroom modules that demonstrate word-order changes (SOV/OSV/etc.), case-marking strategies (prefix/suffix/adposition), tense–aspect remoteness, dual/paucal number, inclusive/exclusive “we,” relativization strategies, and adjective agreement via cumulative morphosyntax exercises; Jupyter notebooks for phonotactics generation and targeted practice stories.
- Assumptions/dependencies: Instructor oversight to correct edge cases (e.g., English-specific lexical quirks like scissors); alignment with curricular standards; access to LLMs or local models.
- Synthetic data generation for NLP model probing (academia, software)
- Tools/workflows: Controlled corpora that isolate morphosyntactic features (e.g., unusual case systems, non-English word orders) for benchmarking LLMs; re-usable gloss schema aligned to WALS features; perplexity-based phonotactic similarity checks using OpenGrm N-gram models.
- Assumptions/dependencies: Synthetic data must be clearly scoped to avoid misleading conclusions; transcription granularity mismatches (e.g., Wiktionary IPA detail variance) should be normalized where possible.
- Product and brand naming informed by target phonotactics (marketing)
- Tools/workflows: Phonotactic generator calibrated to a target language family (e.g., “Welsh-like” or “Turkish-like”) to produce memorable, pronounceable name candidates; agentic feedback loop to add salient phonemes or cluster constraints.
- Assumptions/dependencies: Human vetting for cultural appropriateness; awareness of trademark and linguistic meanings across markets.
- Rapid glossing and pedagogical translation exercises (education, low-resource language training)
- Tools/workflows: Interlinear gloss generation to train students on feature bundles (e.g., 3SGERG, dual/plural distinctions), building discipline around feature-controlled rephrasing and typological awareness.
- Assumptions/dependencies: Not a substitute for field linguistics; careful framing so learners understand gloss abstraction vs. surface realizations.
- Model evaluation and QA for LLMs’ metalinguistic competence (academia, AI quality assurance)
- Tools/workflows: Repeatable test suites using targeted grammatical constructions and cumulative transformation; cross-model comparisons (e.g., Claude vs. GPT vs. Qwen vs. Llama) to quantify strengths/weaknesses on typologically rare phenomena.
- Assumptions/dependencies: Stable evaluation criteria; acknowledgment that performance varies by model family, prompt style, and feature rarity.
- Community-driven collaborative conlanging (daily life, online communities)
- Tools/workflows: GitHub-based modular contributions (phonology rules, lexicon entries, orthography choices), versioning of language “releases,” shared story corpora for feature testing.
- Assumptions/dependencies: Clear contribution guidelines; etiquette and governance to keep the language consistent; moderation to avoid appropriative or insensitive design.
- Previsualization of orthography and script choices (design, UX in media)
- Tools/workflows: Visual mockups of Latin/Cyrillic mappings for subtitles, signage, UI; style-guide output from the grammar handbook module for art and localization teams.
- Assumptions/dependencies: Limited to existing scripts in current tooling; future expansion needed for bespoke scripts or calligraphic systems.
- Lightweight agentic code generation for micro-generators (software engineering)
- Tools/workflows: The paper’s iterative self-refinement paradigm (feedback on produced code + sample outputs + error messages) reused to build compact generators (e.g., syllable cluster builders, lexeme samplers) in other domains.
- Assumptions/dependencies: Requires a feedback loop and small test datasets; best for constrained domains where generated code can be validated quickly.
Long-Term Applications
The following use cases require additional research, scaling, or engineering to mature (e.g., improved feature fidelity, data normalization, and human–AI workflows).
- Grammar-augmented translation for low-resource languages (NLP, language tech)
- Tools/products/workflows: Feature-controlled translation pipelines where English (or a high-resource source) is mapped to target morphosyntactic bundles, then realized in the low-resource language; semi-supervised training leveraging glossed synthetic data to bootstrap lexicons and inflection tables; “language sketch” aids for human translators.
- Assumptions/dependencies: Current results are mostly negative; needs better alignment between gloss abstractions and realistic surface forms; robust lexicon induction and community validation; speech/text corpora for model fine-tuning; ethical collaboration with language communities.
- Digital language documentation and revitalization scaffolding (policy, academia, NGOs)
- Tools/products/workflows: Rapid orthography proposals, feature inventories, and interlinear gloss templates to accelerate early documentation phases; community-controlled customization of morphosyntax settings; onboarding materials derived from grammar handbooks.
- Assumptions/dependencies: Strong community consent; local linguistic leadership; careful IP and data sovereignty policies; avoidance of AI overreach in defining language norms.
- Standards for typological feature bundles and gloss schemas (academia, standards bodies)
- Tools/products/workflows: Shared schema for features (e.g., case strategies, inclusive/exclusive, dual/paucal, relativization) with mappings to WALS-like inventories; evaluation protocols for phonotactic similarity metrics that account for transcription granularity.
- Assumptions/dependencies: Broad consensus-building; tooling support to ensure cross-repo compatibility; transparent provenance tracking.
- Fictional-language conversational agents (entertainment, HCI)
- Tools/products/workflows: In-universe assistants that understand and produce a show/game’s ConLang (text and potentially speech), supporting player interactions, quest dialogue, and lore discovery; standardized grammar APIs for NLU/NLG.
- Assumptions/dependencies: Needs robust lexicon growth, disambiguation rules, and phonology-to-TTS pipelines; safety filters and usability tuning.
- Personalized typology-aware language tutors (education)
- Tools/products/workflows: AI tutors that generate exercises targeting specific morphosyntactic gaps (e.g., relative clauses, case marking, word order alternations), explain typological variation, and adapt via targeted stories and sentence sets.
- Assumptions/dependencies: Pedagogical validation; user models; explainability and transparency on errors and rare patterns.
- Agentic program synthesis beyond linguistics (software, robotics)
- Tools/products/workflows: Generalizing the paper’s iterative improvement loop to synthesize small domain-specific generators (e.g., motion primitives with constraints, symbolic planners), validated by domain-specific metrics analogous to perplexity.
- Assumptions/dependencies: Requires measurable fitness functions; robust error feedback; careful scoping to avoid compounding subtle errors.
- HCI command languages with reduced ambiguity (software, robotics)
- Tools/products/workflows: Constructed micro-languages informed by morphosyntax (e.g., consistent case marking or word order) to reduce misinterpretation in voice or text commands; feature-controlled grammar design for enterprise workflows.
- Assumptions/dependencies: Extensive user testing; potential trade-off between naturalness and precision; interoperability with existing NLU systems.
- Policy frameworks for AI-generated languages in media and education (policy)
- Tools/products/workflows: Guidelines on crediting, rights, and cultural representation; best practices for community consultation when using real-language typologies; procurement standards for educational deployments.
- Assumptions/dependencies: Multi-stakeholder engagement; alignment with IP law; ethical review processes.
- Integrated phonology and speech pipelines (NLP, speech tech)
- Tools/products/workflows: Expansion from phonotactics to realistic phonological rule sets and TTS/ASR for ConLangs; speech-based evaluation to probe human-like phonological biases.
- Assumptions/dependencies: High-quality phonological modeling; dataset creation for pronunciation; careful evaluation vs. human judgments.
- Sustainable compute and evaluation practices (energy, academia)
- Tools/products/workflows: Benchmark suites that minimize compute while maintaining typological coverage; standardized small-model baselines for metalinguistic tasks (aligned with BabyLM-like initiatives).
- Assumptions/dependencies: Community adoption; reproducible pipelines; clear reporting on data sources and transcription detail.
Cross-cutting assumptions and dependencies
- Variability across LLM families: The paper documents capability differences (e.g., Claude outperforming others in certain phonotactic or morphosyntactic tasks).
- Transcription granularity: Wiktionary IPA detail varies by language; phonotactic similarity metrics must normalize or stratify by transcription level.
- Prompt length and modularity: The cumulative morphosyntax approach is preferred over single-pass prompts; longer, detailed prompts risk exceeding context limits and degrading adherence.
- Abstraction vs. surface form: Gloss-level transformations are pedagogically powerful but can diverge from real languages’ surface realizations; careful mapping is necessary for production use.
- Human-in-the-loop: Linguist review, community validation, and editorial oversight are essential for quality, ethics, and cultural respect.
- Licensing and IP: Clarify ownership and re-use rights for AI-generated grammars, lexicons, and scripts, especially in commercial settings.
Collections
Sign up for free to add this paper to one or more collections.