- The paper introduces FLORES-101, offering a high-quality, multi-way parallel dataset for evaluating multilingual and low-resource translation systems.
- It employs rigorous human evaluation and automated quality controls, including the innovative spBLEU metric, to ensure consistent translation quality across 101 languages.
- Empirical results reveal that direct many-to-many translation often outperforms English-centric pivoting, highlighting both challenges and opportunities in low-resource MT.
Flores-101: A High-Coverage Benchmark for Multilingual and Low-Resource Machine Translation
Motivation and Benchmark Design
The FLORES-101 benchmark, introduced in "The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation" (2106.03193), addresses a central bottleneck in multilingual MT: the absence of high-quality, many-to-many evaluation resources, especially for languages with limited parallel data. Pre-existing datasets are fragmented in terms of language coverage, domain diversity, and translation quality assurance; moreover, most are built either predominantly via automatic alignment or cover only English-centric translation contexts.
FLORES-101 curates 3,001 sentences from English Wikipedia, spanning diverse domains (WikiNews, WikiJunior, WikiVoyage) and topics. Each sentence is professionally translated into 101 languages through a rigorously controlled annotation process involving manual selection of source sentences, multi-provider translation, automated checks, and multiple rounds of human evaluation. Critically, the benchmark provides full multi-way parallel alignment, enabling evaluation of any L2 language pair (where L=101), supporting both many-to-many and regional translation directions.
Quality Assurance and Automated Checks
Producing accurate references in truly low-resource languages is non-trivial, given the scarcity and variability among professional translators. The annotation pipeline incorporates two key pilots: selecting optimal LSPs and establishing efficient, bias-minimizing retranslation flows. Automatic QC heuristics play an essential role, especially to guard against copy-paste from commercial MT engines—a major failure mode that can corrupt reference quality.
(Figure 1)
Figure 1: High sentence-level spBLEU scores in gray indicate reference copies from commercial MT engines, a pitfall mitigated by automatic checks; unaffected languages in blue have proper score distributions.
Errant references are detected via sentence-level spBLEU differences between the reference and the output of popular MT engines. When violations exceed preset thresholds (e.g., >10% high-BLEU overlap with engine output), entire sets are rejected and retranslated, ensuring corpus integrity prior to human evaluation.
Human Evaluation and Translation Quality
Human-based Translation Quality Scores (TQS) are calculated per language using error counts by independent LSP reviewers. Errors span grammar, spelling, mistranslation, unnatural phrasing, and omission/addition, each rated by severity. A minimum TQS of 90% is enforced for dataset inclusion.
(Figure 2)
Figure 2: Translation Quality Scores for all 101 languages demonstrate consistent high standards enforced by iterative quality control.
Notably, even severely low-resource languages achieved required quality levels after retranslation—45 languages required at least one retransmission, with an average turnaround of ~2 months per language. Mistranslation remains the dominant error type; domain-to-domain translation difficulty does not show strong correlation across languages, indicating robustness of the reference annotations.
The SentencePiece BLEU Metric for Universal Evaluation
Traditional BLEU evaluation is compromised by inconsistent language-specific tokenization and the prevalence of custom scripts in low-resource languages. FLORES-101 proposes SentencePiece BLEU (spBLEU), leveraging a 256k-token universal SPM tokenizer trained on all benchmark languages with temperature-upsampling for data-poor languages. This design yields a single consistent automatic metric, extendable to future languages and eliminating reliance on costly custom tokenizers.
spBLEU displays strong Spearman and Kendall τ correlation with standard BLEU in European languages, and surpasses character-level BLEU alternatives in languages that historically required bespoke tokenization (Hindi, Tamil, Chinese). Model selection results using spBLEU align with both BLEU and human evaluation, validating its utility for both research benchmarking and model development cycles.
Empirical Evaluation of Multilingual Models
FLORES-101 serves as a comprehensive benchmarking resource for assessing MT models across a diversity of translation scenarios. The paper applies the benchmark to evaluate many-to-many Transformer-based models (e.g., M2M-124, OPUS-100) on all 101×101 directions and several regional clusters.
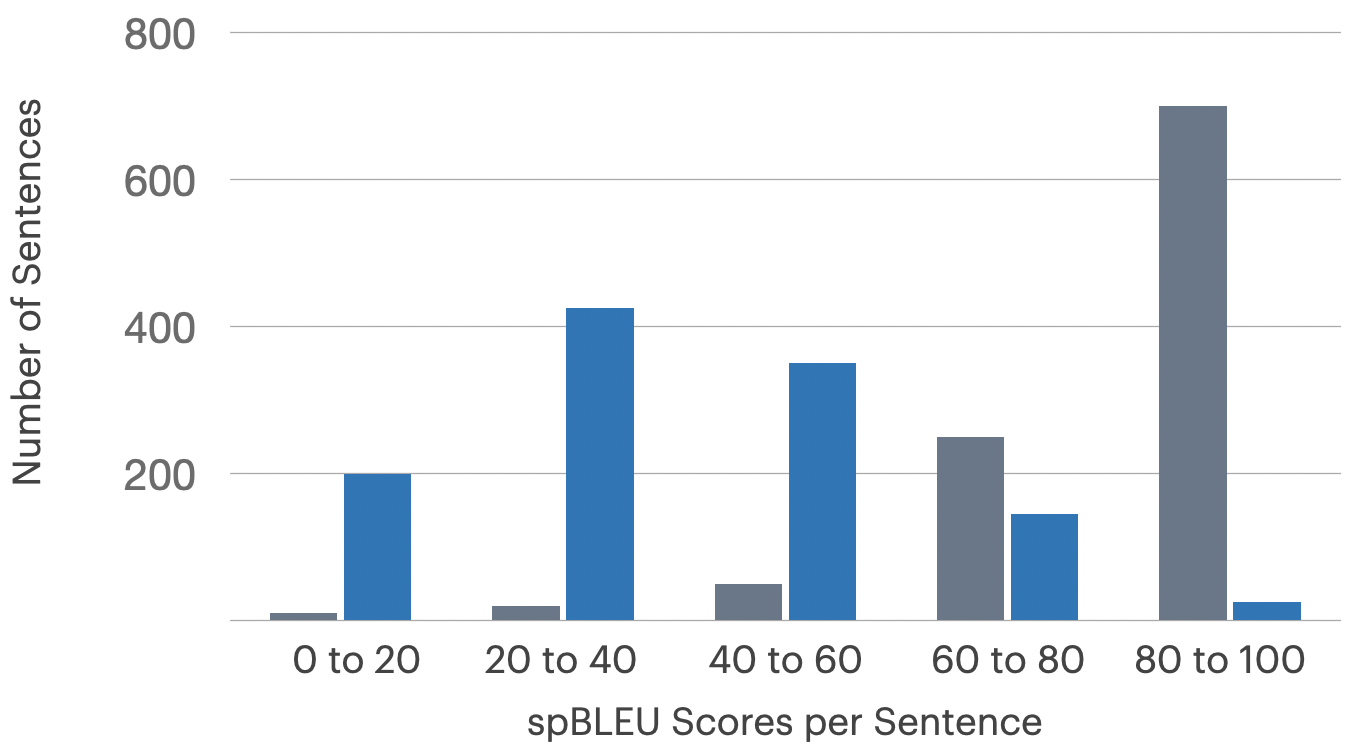
Figure 3: Translation performance (spBLEU) by direction and data availability; translations into English outperform those out of English for equivalent bitext resources.
Performance is highly sensitive to bitext quantity—directions with >100M sentences routinely reach spBLEU ∼20, whereas most African and Dravidian directions with <100k bitext languish near spBLEU ∼2-4. Translation into English is universally easier than out of English given identical data.

Figure 4: OPUS-100 versus M2M-124 on diverse one-many/many-one language groups demonstrate consistent rank ordering; larger models achieve modest gains, but all systems show substantial room for improvement outside English-centric pairs.
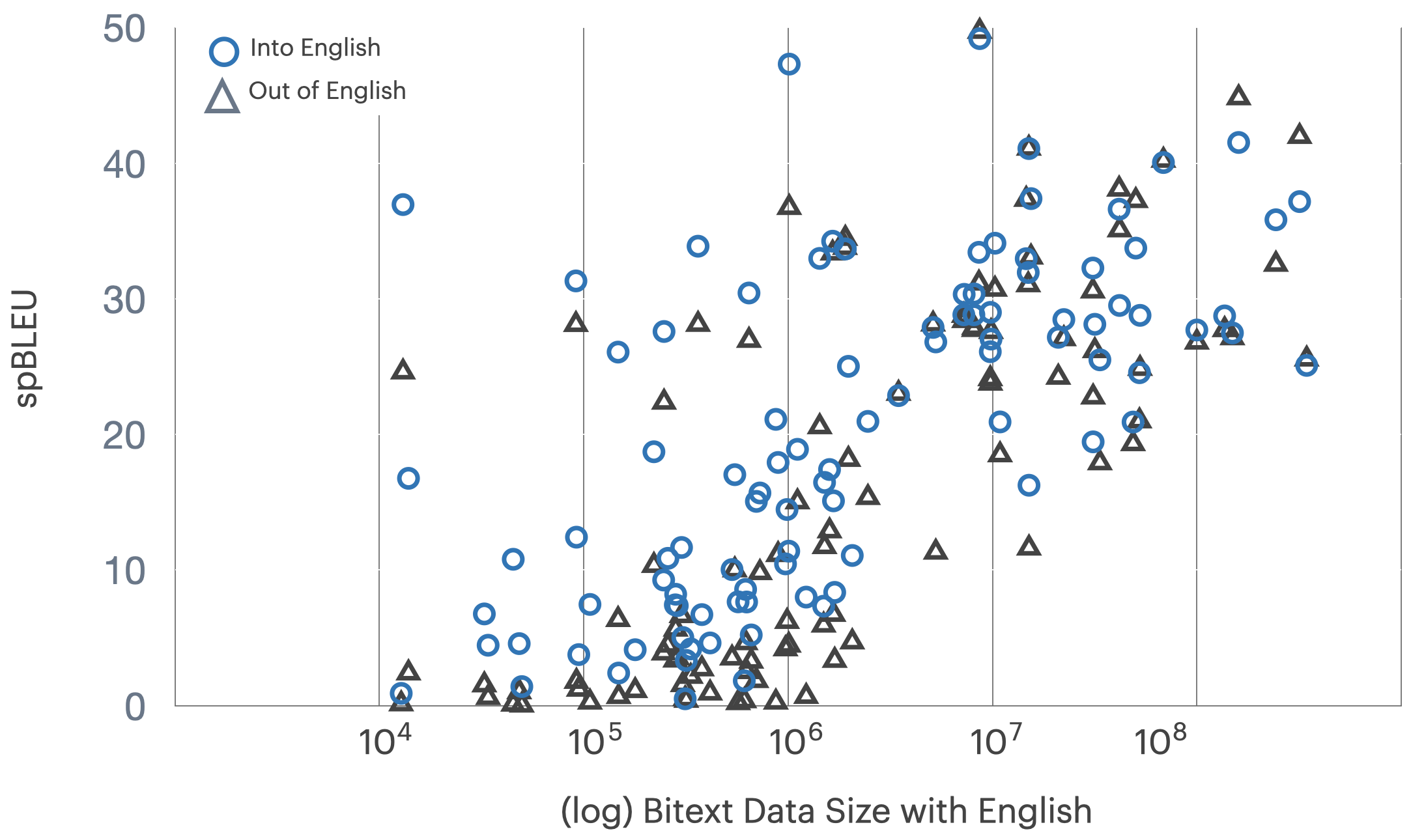
Figure 5: M2M-124 results on all directions reflect substantial performance degradation when evaluated on more challenging language pairs in FLORES-101.
Comparison with specialized models (e.g., Masakhane-mt for African languages) yields mixed findings; in certain cases specialist models outperform multilingual baselines (Zulu, Luo), but overall both categories display spBLEU scores indicative of challenging, unsolved directions.
Many-to-Many Versus English Centric Pivoting
FLORES-101 enables direct assessment of many-to-many models versus English-pivoted translation pipelines. Analysis on Indic languages reveals direct translation is advantageous in ∼80% of tested directions, often yielding spBLEU gains of up to 3 points over pivoting, though some losses are observed.
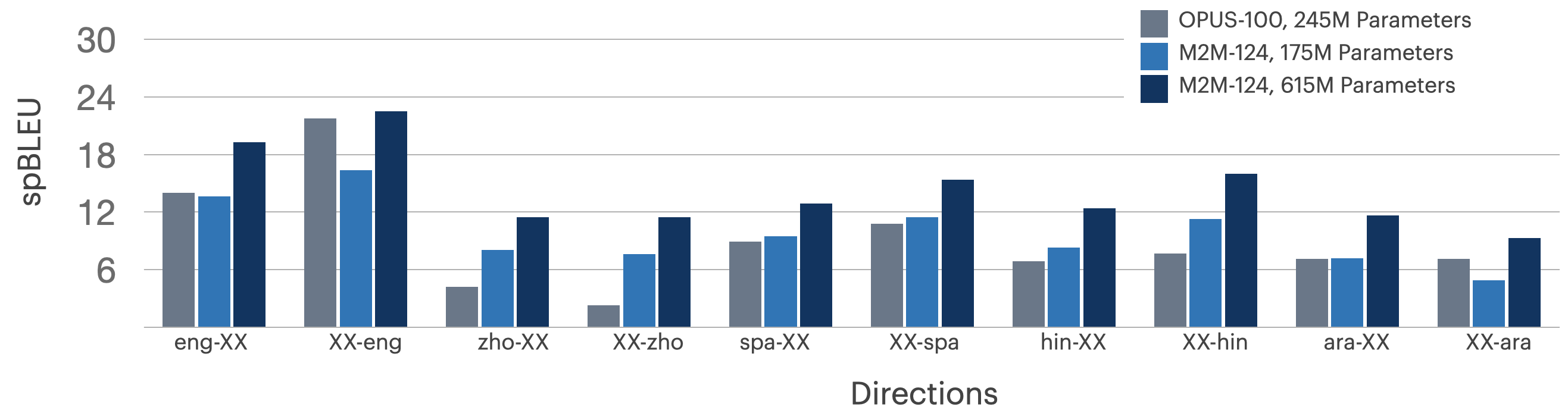
Figure 6: Comparison of direct many-to-many versus English-centric pivot translation for 10 Indic languages; direct models are beneficial for the majority of paired directions.
Broader Implications and Future Directions
By releasing FLORES-101, the authors establish a new baseline for fair, comprehensive MT system evaluation in the global context. The dataset's multi-way alignment supports arbitrary pairwise and many-to-many evaluation—enabling development and assessment of non-English-centric systems and regionally relevant language pairs hitherto ignored. High-quality human references, rigorous QC, and extensibility to multimodal/document-level tasks (via rich metadata) further broaden applicability.
Practically, advances in multilingual modeling, transfer learning, and low-resource adaptation can be measured robustly. Theoretical implications include the ability to probe MT models for cross-lingual generalization and linguistic transfer. The spBLEU metric provides a foundation for further innovation in universal MT evaluation, especially with scaling to truly hundreds or thousands of languages.
Conclusion
FLORES-101 is a pivotal resource for scaling MT research and deployment to the world's linguistic diversity. The benchmark establishes a robust, human-evaluated, multi-way parallel test set, coupled with a unified evaluation metric, enabling systematic assessment. Results from current models underscore significant challenges ahead—especially in low-resource and typologically diverse settings. FLORES-101 will facilitate creation, tuning, and fair evaluation of the next generation of multilingual MT systems and related cross-lingual NLP tasks.