Populism Meets AI: Advancing Populism Research with LLMs
Abstract: Measuring the ideational content of populism remains a challenge. Traditional strategies based on textual analysis have been critical for building the field's foundations and providing a valid, objective indicator of populist framing. Yet these approaches are costly, time consuming, and difficult to scale across languages, contexts, and large corpora. Here we present the results from a rubric and anchor guided chain of thought (CoT) prompting approach that mirrors human coder training. By leveraging the Global Populism Database (GPD), a comprehensive dataset of global leaders' speeches annotated for degrees of populism, we replicate the process used to train human coders by prompting the LLM with an adapted version of the same documentation to guide the model's reasoning. We then test multiple proprietary and open weight models by replicating scores in the GPD. Our findings reveal that this domain specific prompting strategy enables the LLM to achieve classification accuracy on par with expert human coders, demonstrating its ability to navigate the nuanced, context sensitive aspects of populism.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to measure “populism” in political speeches using AI. Populism is when politicians talk about politics as a moral fight between “the pure people” and “a corrupt elite.” The authors show that LLMs—advanced AIs that understand text—can be taught to spot this kind of talk almost as well as trained human experts.
What questions were the researchers trying to answer?
They wanted to know:
- Can AI grade how populist a speech is in a careful, human-like way?
- If we teach an AI using the same training materials we give human coders, will it make similar judgments?
- Which kinds of AI models do this best, and how close do they get to expert-level accuracy?
How did they do it? (Methods explained simply)
To understand the method, picture how a teacher trains students to grade essays:
- The teacher uses a rubric (a scoring guide) and shows sample essays with example scores. Students learn what a “0,” “1,” or “2” looks like and why.
The researchers used that same idea for AI:
- They used Holistic Grading (HG): Instead of counting certain words, you read the whole speech and give one overall score:
- 0 = little or no populism,
- 1 = some populism, but not strong or consistent,
- 2 = strong populism throughout.
- They trained the AI with “anchor” speeches: real speeches already scored by experts at different levels (like sample essays showing what each score means).
- They gave the AI a clear rubric: what counts as people-centered language, anti-elite talk, “good vs. evil” framing, calls for big systemic change, and so on.
- They used Chain-of-Thought prompting: This tells the AI to “show its work,” step by step, before giving a final score—just like a math teacher asking you to write out how you solved a problem.
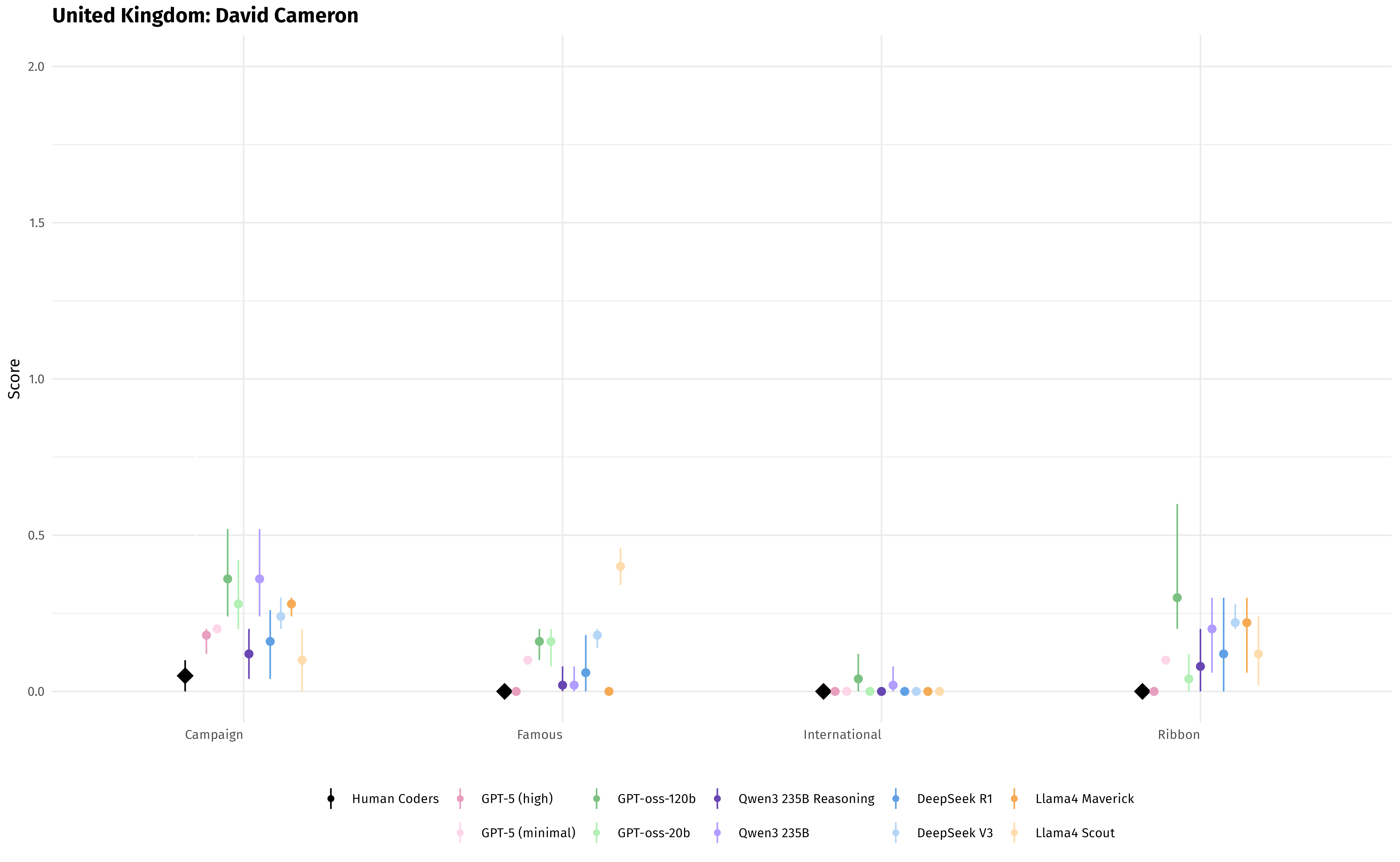
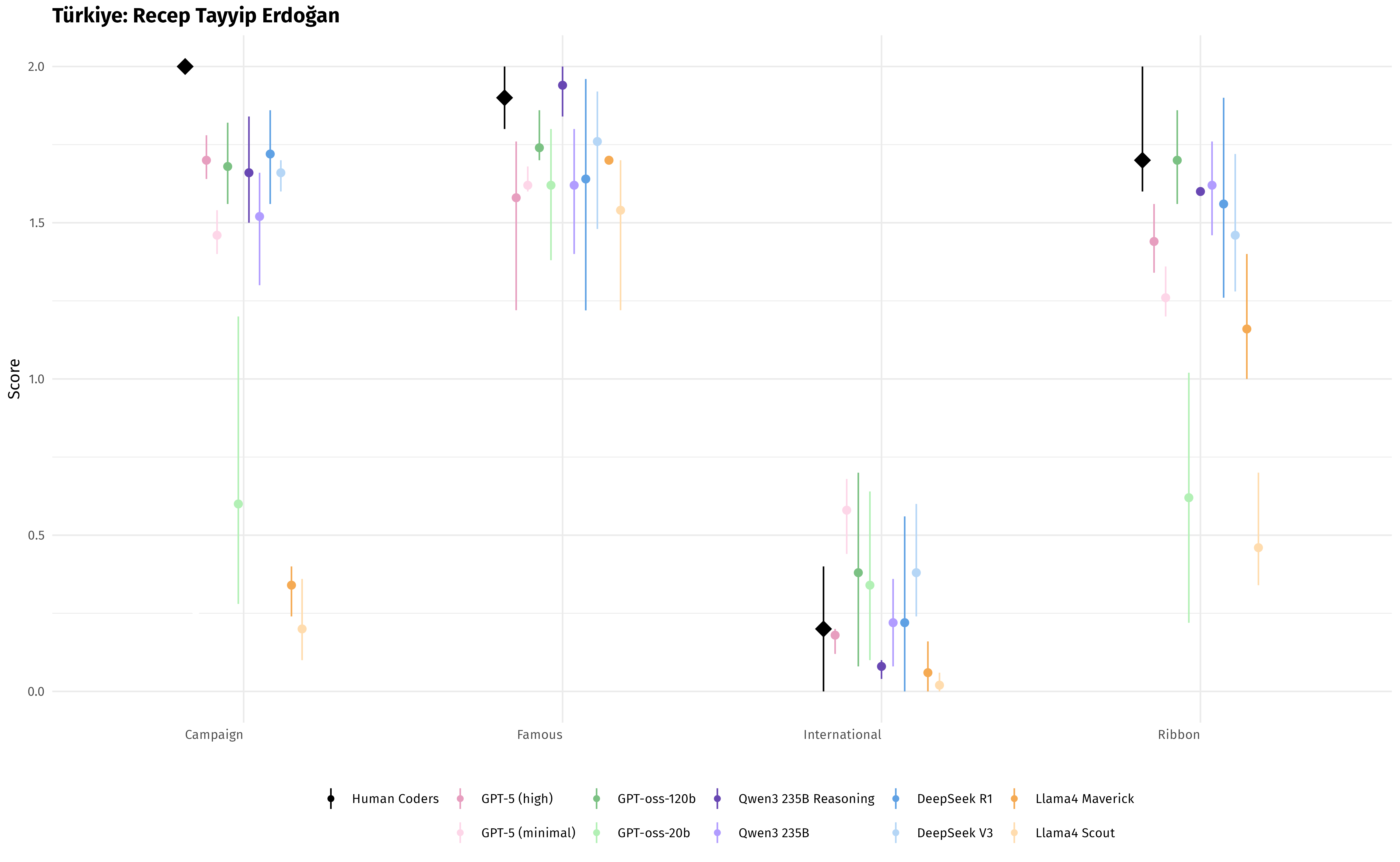
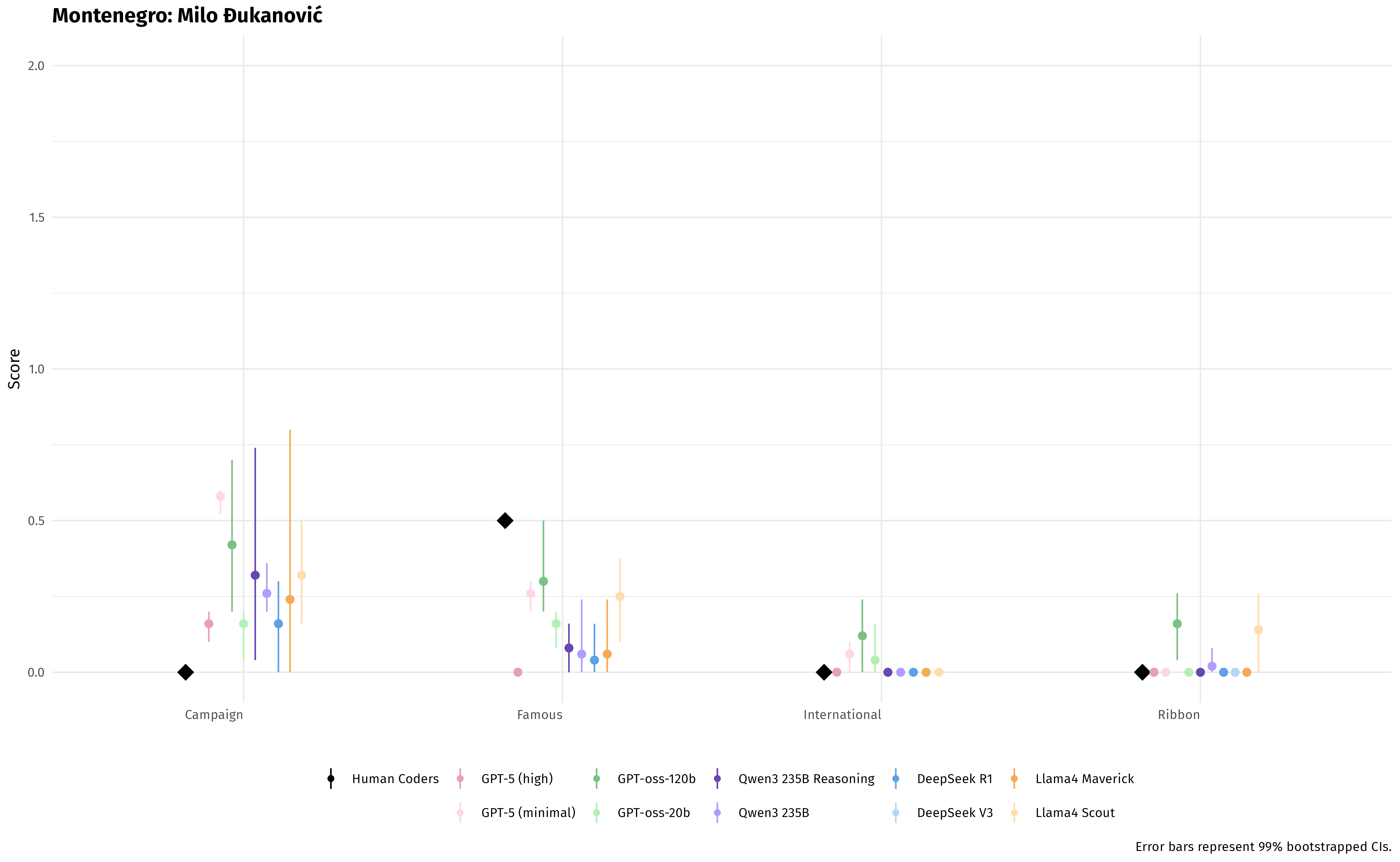
They then tested several AI models on 12 political speeches from the UK, Türkiye, and Montenegro, covering four types of speeches (campaign, famous, international, and ribbon-cutting). They compared the AI’s scores to human experts’ scores, running each model five times to check consistency.
What did they find, and why does it matter?
Here are the main takeaways:
- Teaching the AI with a rubric and anchor speeches worked. The best models scored speeches very similarly to human experts.
- The top performers were models designed for “reasoning” (AI that is better at thinking step-by-step). In particular, GPT-5 (in high reasoning mode) and Qwen3 (reasoning mode) matched humans most closely.
- The AI kept the rank order right: it could tell which speeches were more or less populist in the correct order.
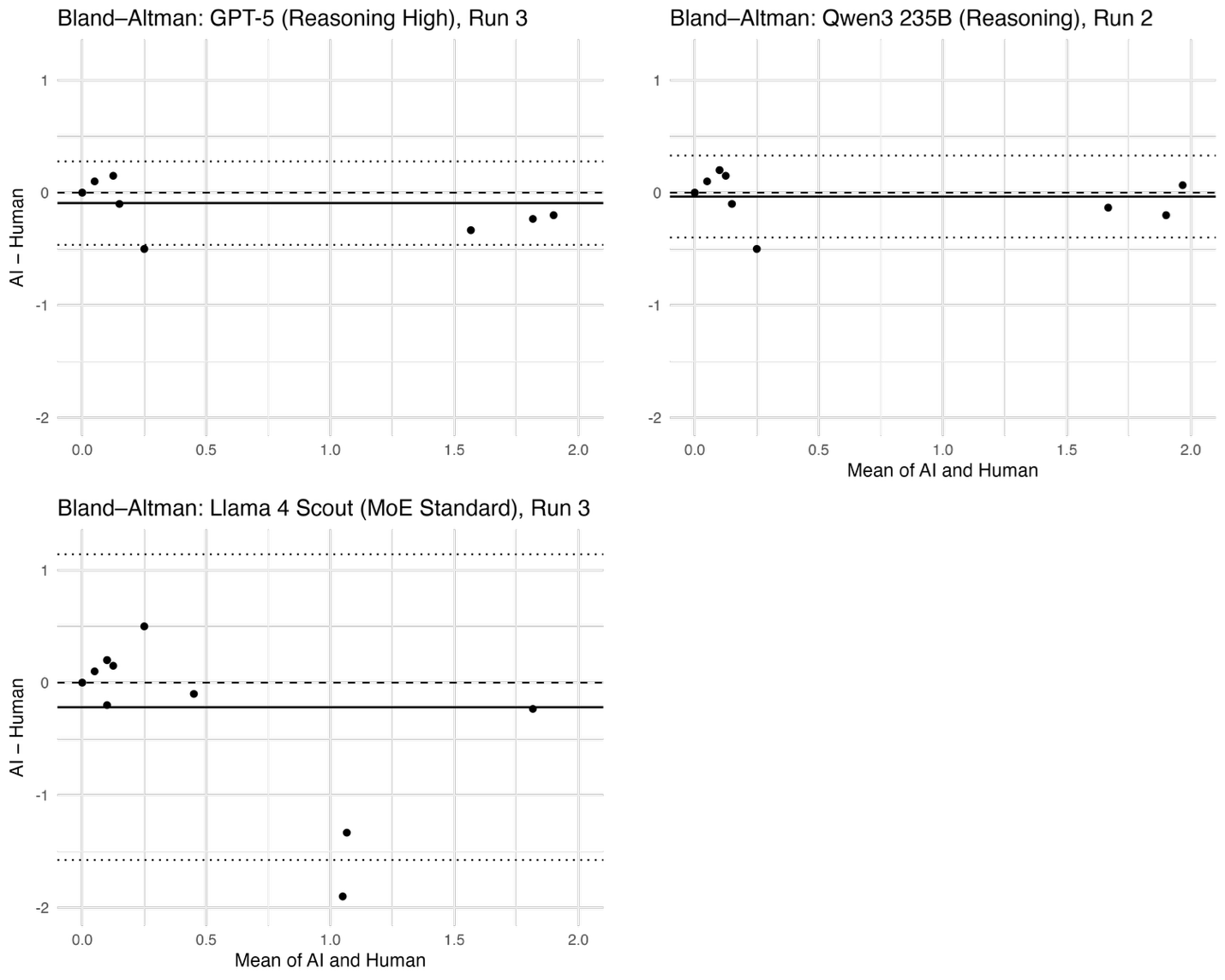
- One quirk: the AI “squeezed” the scale a bit. It tended to give slightly higher scores to very low-populism speeches and slightly lower scores to very high-populism speeches. In short, it pulled extreme scores toward the middle.
- Models without strong reasoning features did worse. Bigger, reasoning-focused models did better.
Why this matters:
- Human coding is slow, expensive, and hard to do across many countries and languages. AI can help scale this work quickly and more cheaply.
- Because the AI explains its reasoning (Chain-of-Thought), researchers can check whether it’s using the rubric correctly, which adds transparency.
What could this change in the future? (Implications)
This research suggests several important impacts:
- Scaling up research: AI could help measure populism across many countries, languages, and time periods much faster than before.
- Studying more complex ideas: The same approach could be adapted to analyze other hard-to-measure political styles, like nationalist or pluralist framing, not just populism.
- Building public tools: This lays the groundwork for creating easy-to-use AI tools that classify political speeches for researchers, journalists, and the public.
A simple caution:
- AI is very good but not perfect. It can gently compress extreme scores and perform differently depending on the model. Humans should still check results, calibrate scores, and watch for errors—especially when stakes are high.
In short
The authors showed that if you train an AI like you would a human grader—using a clear rubric, sample speeches with known scores, and step-by-step reasoning—the AI can judge how “populist” a speech is almost as well as experts. This could make studying political language around the world faster, cheaper, and more consistent, while still keeping the careful, big-picture reading that holistic grading requires.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- External validity: performance is assessed on only 12 speeches from 3 countries and 4 speech types; broader cross-national, cross-linguistic, and cross-genre validation (e.g., party manifestos, interviews, social media, debates) is not tested.
- Language handling: it is unclear whether speeches in Turkey and Montenegro were coded in original languages or translations; the impact of translation choices on LLM scoring accuracy and bias remains unmeasured.
- Temporal generalization: no assessment of model robustness across time (e.g., evolving rhetoric from different decades or political cycles) or under domain drift in populist framing.
- Data contamination risk: models may have seen anchor or target speeches during pretraining; the study does not control for memorization or evaluate performance on truly unseen, post–knowledge-cutoff texts.
- Anchor representativeness: the anchor set remains left-skewed and largely Anglophone; systematic validation of anchor coverage across languages, regions, regimes, and ideological strands of populism is missing.
- Sub-dimension fidelity: holistic scores are reproduced, but there is no evaluation of whether models accurately and consistently identify each rubric component (people-centrism, anti-elitism, Manichaean framing) or provide reliable sub-scores.
- Rationale faithfulness: CoT explanations are not audited—do model rationales align with rubric criteria and human reasoning, or are they confabulations? Expert evaluation of rationale faithfulness is needed.
- Calibration and scale compression: known upward bias near zero and downward bias near the maximum are documented but not corrected; no evaluation of post-hoc calibration methods (e.g., isotonic regression, Platt scaling, monotonic transforms) or their effects on agreement metrics.
- Rank-order reliability: relatively lower Spearman correlations suggest ranking instability; the paper does not probe rank errors (e.g., which speech types or contexts drive mis-ordering) or propose methods to stabilize rankings.
- Model governance and reproducibility: heavy reliance on proprietary models without full visibility into training and CoT generation; reproducibility across providers, releases, or API versions is not assessed.
- Prompt robustness: no ablation of prompt design (anchor order, rubric phrasing, length), temperature, or decoding parameters; sensitivity analyses to prompt variations and reasoning-effort settings are missing.
- CoT vs. instruction baselines: the paper argues conceptually for CoT benefits but does not empirically compare against zero-shot, instruction-only, or standard few-shot baselines to isolate the unique contribution of CoT.
- Fine-tuning vs. prompting: only prompt-based SHG is tested; whether small or mid-size open-weight models can match performance via supervised fine-tuning or PEFT on HG-labeled data remains unexamined.
- Cost and scalability: compute, latency, and token costs (especially under high reasoning effort with long training materials) are not reported; practical feasibility for scaling to millions of speeches is unclear.
- Robustness to rhetorical complexity: performance on sarcasm, irony, coded language, metaphors, dog-whistles, and code-switching is not tested; adversarial robustness (e.g., deliberate obfuscation of populist cues) remains an open question.
- Cross-cultural construct validity: no analysis of whether models apply an implicit, Western-centric frame; systematic cross-cultural validity checks (e.g., in non-Indo-European languages or culturally specific rhetorical forms) are lacking.
- Ideological and demographic bias: the study does not assess whether models systematically over/under-score populism for particular ideologies, regions, genders, ethnicities, regime types, or religious references.
- Human benchmark quality: human means are based on small coder counts, with Krippendorff’s α = 0 in two countries due to low variance; the adequacy of these labels as a “gold standard” in low-variation settings needs reconsideration (e.g., expanding items to increase variance).
- Speech-type effects: the claim that rank-order is preserved across categories is not deeply analyzed; model-specific errors by speech type (campaign vs. international vs. ribbon-cutting) and their causes are unexplored.
- Context-window constraints: the effect of very long training prompts (anchors + rubric) and potential truncation of long speeches is not measured; chunking strategies and their impact on HG fidelity are not evaluated.
- Uncertainty quantification: five independent runs provide SDs, but per-item uncertainty estimates (e.g., Bayesian or bootstrap CIs per speech) and guidance on how many runs are needed for stable scores are not provided.
- Decision-use thresholds: if end-users need categorical labels (e.g., non-populist vs. mild vs. strong), optimal operating points, threshold stability, and error trade-offs are not studied.
- Comparison to traditional ML: there is no head-to-head benchmarking against dictionary-based or supervised ML classifiers trained on the same data to quantify relative gains in accuracy, calibration, and cost.
- Multimodal signals: HG relies on discourse and context; paralinguistic cues (tone, prosody, audience interaction, visuals) are ignored—whether multimodal LLMs improve measurement is an open question.
- Release and reproducibility: full prompts, anchor texts and scores, code, seeds, decoding parameters, and raw outputs are not made available; without these, independent replication is difficult.
- Ethics and governance: the paper treats LLMs as “co-analysts” but does not address accountability, transparency obligations, or mitigation protocols when model judgments carry political implications (e.g., labeling parties/leaders).
- Downstream impact: how SHG-based scores affect substantive political science inferences (e.g., mapping party systems, policy outcomes) and whether small calibration errors meaningfully bias conclusions is not assessed.
Practical Applications
Practical, real-world applications of the paper’s findings, methods, and innovations
The paper demonstrates that rubric- and anchor-guided chain-of-thought (CoT) prompting can enable LLMs to replicate Holistic Grading (HG) for measuring populist rhetoric with human-level fidelity. Below are actionable applications that leverage this methodology across sectors, along with their deployment horizon, potential tools or workflows, and assumptions or dependencies.
Immediate Applications
- Populism Scoring API and newsroom dashboard — sectors: media, software, journalism
- Tools/workflows: “Populism Meter” API that ingests speeches/transcripts and returns 0–2 populism intensity scores with transparent CoT reasoning; CMS plugin for newsroom editors to annotate political coverage; batch processing for debate nights.
- Assumptions/dependencies: Access to high-performing models (e.g., GPT-5 reasoning or Qwen3 reasoning); curated anchor pack and rubric; high-quality transcripts; human-in-the-loop review to address scale compression and edge cases.
- Election monitoring for watchdogs and civic tech — sectors: NGOs, policy, civic tech
- Tools/workflows: Automated pipelines to code campaign speeches, party manifestos, and political ads across languages; dashboards flagging spikes by leader, party, region, or event type; exportable CoT justifications for transparency.
- Assumptions/dependencies: Reliable multilingual transcription; governance over model bias; ethical oversight for use during active campaigns; calibration to local rhetorical norms.
- Rapid expansion of the Global Populism Database (GPD) — sectors: academia, research infrastructure
- Tools/workflows: Batch AI coding with CoT logs, followed by adjudication panels; standardized calibration runs on new countries/languages using anchor speeches; reproducible notebooks and model cards.
- Assumptions/dependencies: Institutional IRB/data-use approvals; consistent anchor updates; compute budget; cross-language validation protocols.
- Human coder training and calibration assistant — sectors: education, research methods
- Tools/workflows: Interactive tutor that walks trainees through rubric, anchors, and reasoning; dynamic practice sets with immediate feedback; consensus workshops using AI-generated CoT as scaffolding.
- Assumptions/dependencies: Access to training materials; clear pedagogical scripts; careful prompt design to avoid over-fitting to exemplars.
- Cross-lingual populism analysis pipeline — sectors: think tanks, comparative politics, international organizations
- Tools/workflows: Multilingual LLM scoring that obviates separate native coder teams; uniform rubric application across languages; reports comparing speech types (campaign, famous, international, ribbon-cutting).
- Assumptions/dependencies: Model robustness across languages; domain-specific calibration for rhetorical conventions; monitoring for language-specific errors.
- Platform policy triage for political advertising — sectors: social media, regtech, trust and safety
- Tools/workflows: Pre-review of political ads to quantify populist framing; routing thresholds for human policy review; CoT traces for auditability.
- Assumptions/dependencies: Transparent thresholds; clear scope (non-punitive, triage only); fairness audits to minimize viewpoint discrimination; governance for model drift.
- Political consulting and campaign self-audits — sectors: professional services, political campaigns
- Tools/workflows: Rhetorical analytics for candidates to understand and calibrate populist intensity; A/B testing of messaging with populism scores and qualitative rationales.
- Assumptions/dependencies: Confidential data handling; guardrails against manipulative optimization; joint interpretation with communications experts.
- Journalism annotation and explainer features — sectors: media, public communication
- Tools/workflows: Article-sidebars that annotate speeches with identified people-versus-elite frames and Manichaean cues; visualizations of score evolution across events.
- Assumptions/dependencies: Editorial standards for transparency; careful presentation to avoid overclaiming causality; corrections process when model errors are detected.
- Civics and classroom modules — sectors: education, curriculum development
- Tools/workflows: Lesson plans with interactive examples showing populism vs. pluralism; student exercises comparing speeches using AI-assisted HG reasoning.
- Assumptions/dependencies: Age-appropriate materials; balanced political representation; teacher training on limitations and interpretation.
- Open science assets and benchmarks — sectors: academic tooling, open-source
- Tools/workflows: Public rubric-and-anchor CoT templates, evaluation scripts, and calibration datasets; replication packages for future studies on related ideational constructs.
- Assumptions/dependencies: Licensing for anchor materials; documentation of model and prompt versions; community governance for updates.
Long-Term Applications
- Real-time, cross-platform populism surveillance and early-warning dashboards — sectors: public policy, trust and safety, social platforms
- Tools/workflows: Streaming ingestion of speeches, posts, and video transcripts; geospatial and temporal heatmaps of populist intensity; alerting for rapid escalations (e.g., crisis events).
- Assumptions/dependencies: API access to platforms; privacy and consent frameworks; robust governance to prevent misuse; thorough fairness and impact assessments.
- Publicly accessible, fine-tuned open-weight models specializing in populism and related rhetoric — sectors: software/open-source, research infrastructure
- Tools/workflows: Domain-tuned models (Populism-LLM) with anchor-guided CoT training; evaluation suites with ICC/CCC/Krippendorff’s alpha; versioned model cards.
- Assumptions/dependencies: High-quality multilingual training data; compute resources; licensing clarity; continuous evaluation to maintain alignment and reduce bias.
- Multi-construct rhetoric meter (nationalism, pluralism, conspiracy rhetoric, authoritarian style) — sectors: academia, policy analysis, media
- Tools/workflows: Expanded rubrics and anchor packs; unified dashboard scoring multiple latent constructs; comparative profiles across leaders and parties.
- Assumptions/dependencies: Conceptual clarity and validated rubrics per construct; cross-cultural anchors; careful calibration to avoid construct conflation.
- Regulatory auditing for election commissions and public broadcasters — sectors: government, regtech, public media
- Tools/workflows: Periodic audits of political content for populist framing; disclosure requirements with CoT explanations; oversight reports informing guidelines.
- Assumptions/dependencies: Legal authority; standardized measurement protocols; mechanisms for appeal; stakeholder consultation.
- Market and policy risk analytics for finance and corporate strategy — sectors: finance, ESG, strategic advisory
- Tools/workflows: Linking populism intensity trends to regulatory uncertainty, policy volatility, and sovereign risk dashboards; scenario analysis for investment committees.
- Assumptions/dependencies: Empirically established linkages (populism → policy outcomes); country-specific calibration; caution against overfitting signals to market movements.
- Content moderation and recommender system safeguards — sectors: software/platforms, AI safety
- Tools/workflows: Using construct-level scores to tune exposure diversity and mitigate polarization; transparency reports with model-driven rationales.
- Assumptions/dependencies: Normative decisions about acceptable thresholds; avoidance of viewpoint-based suppression; auditing for unintended disparate impacts.
- Century-scale, longitudinal corpora analyses — sectors: academia, digital humanities
- Tools/workflows: Digitization and AI coding of historical archives; time-series studies of rhetorical evolution across regimes and media formats.
- Assumptions/dependencies: Archive availability and OCR quality; historical language variance; stable calibration across shifts in rhetorical style.
- Citizen-facing tools (browser extensions/apps) — sectors: consumer tech, education
- Tools/workflows: Real-time rating of populism in speeches, videos, or posts; interactive explanations and media literacy prompts.
- Assumptions/dependencies: Clear disclaimers; opt-in consent; safety features to prevent harassment or misuse; localization for languages and contexts.
- Translation and summarization enriched by rhetoric detection — sectors: localization, software
- Tools/workflows: Cross-lingual summarizers that retain rhetorical framing cues; flags when translation risks distorting people-versus-elite constructs.
- Assumptions/dependencies: Multilingual model stability; evaluation on parallel corpora; oversight to prevent amplification of misinterpretations.
- International organization monitoring and diplomatic risk indicators — sectors: multilateral institutions, foreign policy
- Tools/workflows: Country-level panels tracking shifts in populist discourse; inputs to engagement strategies, development programming, or conflict prevention.
- Assumptions/dependencies: Acceptance by member states; careful contextualization to avoid stigmatization; triangulation with qualitative fieldwork.
Notes on feasibility across applications:
- The paper documents high agreement with expert coders but also consistent scale compression and model-specific variance; immediate deployments should include calibration layers and human oversight.
- Dependencies include access to strong reasoning models, reproducible prompts, validated anchor packs, and multilingual transcripts; closed models may offer higher performance but reduce transparency and local adaptation.
- Ethical, legal, and governance considerations are central: ensure non-discriminatory use, audit for bias, disclose limitations, and align with jurisdictional policy frameworks.
Glossary
- Absolute agreement: A strict form of agreement in reliability metrics requiring identical numerical scores from different raters. "intraclass correlation (ICC(2,1), two-way, single, absolute agreement – aa)"
- Anchor fidelity: The degree to which model evaluations adhere to and align with predefined anchor examples used for training. "we assess error patterns, calibration, and anchor fidelity"
- Anchor speeches: Exemplary texts used to train coders and calibrate scale points for measurement. "which consisted of seven anchor speeches originally designed to train human coders"
- Anti-elitism: A core element of populist discourse that frames elites as corrupt or conspiratorial. "assign an integrated score based on the presence and intensity of people-centrism, anti-elitism, and Manichaean framing"
- Anything-goes attitude: A rubric category indicating permissive or unconstrained rhetorical style associated with populism. "alongside six corresponding pluralist categories; anchor speech training, which present the ten training speeches... (Manichaean vision, cosmic proportions, populist notion of people, elite as conspiring evil, systemic change, and anything-goes attitude)"
- Bootstrapped confidence intervals: Statistical intervals derived from resampling to quantify uncertainty around estimates. "with 99% bootstrapped confidence intervals (n = 1000)"
- Chain-of-Thought (CoT) prompting: A technique that elicits step-by-step reasoning before final answers to improve interpretive accuracy. "a rubric- and anchor-guided chain-of-thought (CoT) prompting approach that mirrors human-coder training"
- Concordance Correlation (CCC): A metric assessing agreement that combines correlation with checks for level and scale calibration. "Lin’s Concordance Correlation (CCC; Lin, 1989)"
- Conditional computation: An MoE mechanism where only a subset of expert modules is activated per token to improve efficiency. "Mixture-of-Experts (MoE) models use conditional computation – routing each token to a small subset of experts"
- Content analysis: Systematic coding and interpretation of text to extract meaningful patterns or constructs. "and, most importantly for this study, automate content analysis"
- Cosmic proportions: A rubric category capturing grand, apocalyptic or morally absolute rhetoric in populist discourse. "rubric training, which details the 0-2 scoring scale with anchor points and outlines six populist categories (Manichaean vision, cosmic proportions, populist notion of people, elite as conspiring evil, systemic change, and anything-goes attitude)"
- Dictionary-based approaches: Methods using predefined word lists to detect concepts in text data. "Often, these were dictionary-based approaches relying on hybrid forms of automated and human-based coding"
- Discourse-level coherence: The consistency and logical flow of meaning across an entire text beyond sentence-level features. "identifying intent and discourse-level coherence"
- Discourse-theoretic tradition: A scholarly approach focusing on how political identities and conflicts are constructed through discourse. "The discourse-theoretic tradition, associated with the Essex school"
- Essex school: A school of discourse theory emphasizing antagonism and identity construction in populist politics. "The discourse-theoretic tradition, associated with the Essex school"
- Expert surveys: Measurement strategy that aggregates judgments from domain experts instead of direct text coding. "rely on expert surveys"
- Face-valid: Evidence or measures that appear valid on their surface because they directly reflect the phenomenon. "providing face-valid and context-sensitive indicators of populist framing"
- Few-shot prompting: Prompt design that provides a limited number of examples to guide model outputs. "Standard few-shot prompting offers scoring examples"
- Global Populism Database (GPD): A dataset of leaders’ speeches annotated for degrees of populism across languages and regions. "By leveraging the Global Populism Database (GPD), a comprehensive dataset of global leaders' speeches annotated for degrees of populism"
- Holistic Grading (HG): An integrated scoring approach that evaluates entire texts for overall intensity of populist elements. "Holistic Grading has emerged as a particularly refined approach to these challenges"
- Holistic integration: The synthesis of multiple evaluative criteria into a single, overall judgment. "implementation instructions, providing detailed guidance on holistic integration and score assignment procedures"
- Ideational approach: A theoretical perspective defining populism by its core ideas rather than organizational features. "The ideational approach defines populism minimally in terms of this people-versus-elite frame"
- Instruction-only prompting: Prompts that state criteria without modeling the reasoning process, risking inconsistent application. "instruction-only prompting provides evaluation criteria but leaves the reasoning process implicit"
- Intraclass correlation (ICC(2,1)): A reliability metric assessing absolute agreement between raters across items and rater effects. "We then calculate intraclass correlation (ICC(2,1), two-way, single, absolute agreement – aa)"
- Krippendorff’s α: A reliability index for content analysis that accounts for chance agreement and multiple raters. "Finally, we turn to Krippendorff's α, which provides a more stringent test of reliability"
- Latent construct: An underlying concept not directly observable and inferred from indicators in data. "latent constructs like populism"
- Manichaean binaries: Rhetorical oppositions framing politics as a moral struggle between good and evil. "systematically evaluate people-centric language, anti-elite framing, and Manichaean binaries"
- Manichaean framing: Moral dualism in discourse contrasting a virtuous people against a corrupt elite. "assign an integrated score based on the presence and intensity of people-centrism, anti-elitism, and Manichaean framing"
- Manichaean vision: A rubric category denoting explicit moral dualism as a defining feature of populist rhetoric. "rubric training, which details the 0-2 scoring scale with anchor points and outlines six populist categories (Manichaean vision, cosmic proportions, populist notion of people, elite as conspiring evil, systemic change, and anything-goes attitude)"
- Master frame: A broad interpretive schema through which political conflict and sovereignty are understood. "but functions as a master frame through which the sovereign is identified and political conflict is interpreted"
- Mixture-of-Experts (MoE) architecture: Model design that routes inputs to specialized expert modules for scalability and efficiency. "the Mixture-of-Experts architecture improves scalability and computational efficiency by selectively activating specialized expert modules"
- Open-weight models: Models with publicly available parameters that enable inspection, fine-tuning, and local control. "multiple proprietary and open-weight models"
- Parallel corpora: Multilingual datasets with aligned texts across languages used to learn cross-lingual semantics. "By training on parallel corpora across hundreds of languages"
- Pearson’s r: A statistic measuring linear correlation between two variables. "We start by assessing the agreement between AI and human scores... Pearson’s (linear association)"
- People-centrism: Emphasis on the virtuous, homogeneous “people” as the central political subject. "assign an integrated score based on the presence and intensity of people-centrism, anti-elitism, and Manichaean framing"
- Pluralism: A contrasting framework recognizing legitimate diversity of interests and identities. "we provide the ideational definition of populism, contrast it with pluralism"
- Pooled reliability: Aggregate reliability assessment across multiple raters or runs. "Turning to pooled reliability using Krippendorff's α (interval) with six raters"
- Populist notion of people: A rubric category specifying how “the people” are constructed in populist discourse. "rubric training, which details the 0-2 scoring scale with anchor points and outlines six populist categories (Manichaean vision, cosmic proportions, populist notion of people, elite as conspiring evil, systemic change, and anything-goes attitude)"
- Populist rhetoric: Language and framing strategies characteristic of populism. "\keywords{populism \and LLMs \and populist rhetoric}"
- Reasoning-tuned models: Systems trained post hoc to produce explicit, step-by-step reasoning in complex tasks. "By contrast, reasoning-tuned models emphasize post-training methods (e.g., reinforced learning-style “deliberate reasoning”)"
- Rubric: A structured set of criteria guiding consistent evaluation and scoring. "rubric training, which details the 0-2 scoring scale with anchor points"
- Spearman’s ρ: A statistic measuring rank-order association between variables. "Spearman’s (rank association)"
- Systemic change: A rubric category capturing calls for fundamental transformation of political or institutional systems. "rubric training, which details the 0-2 scoring scale with anchor points and outlines six populist categories (Manichaean vision, cosmic proportions, populist notion of people, elite as conspiring evil, systemic change, and anything-goes attitude)"
- Test-retest framework: A reliability design that repeats measurements to assess consistency over runs. "using five independent runs per model (a test-retest framework)"
- Transformer architecture: A neural network design using attention mechanisms, foundational for modern LLMs. "Since the introduction of the Transformer architecture (Vaswani et al., 2017)"
- Zero-shot prompting: Prompting without examples, relying on generalization from pretraining to perform tasks. "Zero-shot prompting risks superficial analysis based on irrelevant textual cues"
Collections
Sign up for free to add this paper to one or more collections.