h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning
Abstract: LLMs excel at short-horizon reasoning tasks, but performance drops as reasoning horizon lengths increase. Existing approaches to combat this rely on inference-time scaffolding or costly step-level supervision, neither of which scales easily. In this work, we introduce a scalable method to bootstrap long-horizon reasoning capabilities using only existing, abundant short-horizon data. Our approach synthetically composes simple problems into complex, multi-step dependency chains of arbitrary length. We train models on this data using outcome-only rewards under a curriculum that automatically increases in complexity, allowing RL training to be scaled much further without saturating. Empirically, our method generalizes remarkably well: curriculum training on composed 6th-grade level math problems (GSM8K) boosts accuracy on longer, competition-level benchmarks (GSM-Symbolic, MATH-500, AIME) by up to 2.06x. Importantly, our long-horizon improvements are significantly higher than baselines even at high pass@k, showing that models can learn new reasoning paths under RL. Theoretically, we show that curriculum RL with outcome rewards achieves an exponential improvement in sample complexity over full-horizon training, providing training signal comparable to dense supervision. h1 therefore introduces an efficient path towards scaling RL for long-horizon problems using only existing data.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs to “think for longer” without making them super expensive to train. Today, LLMs are good at short problems (like solving one math question), but they struggle when a problem has many linked steps where each step depends on the previous one. The authors introduce a method they call “h1” that turns lots of simple questions into longer chains, and then trains the model to handle those chains using reinforcement learning. The big idea: use the easy, abundant data we already have to build tougher practice problems that help the model learn how to keep track of information and reason over many steps.
What questions did the researchers ask?
They focused on three simple questions:
- Can we make LLMs better at long, multi-step reasoning using only short, easy problems that are already available?
- Can we train them using rewards on just the final answer (not step-by-step labels) and still get strong learning?
- Will this training generalize, meaning the model will also perform better on much harder, real-world problems?
How did they do it? (Methods explained simply)
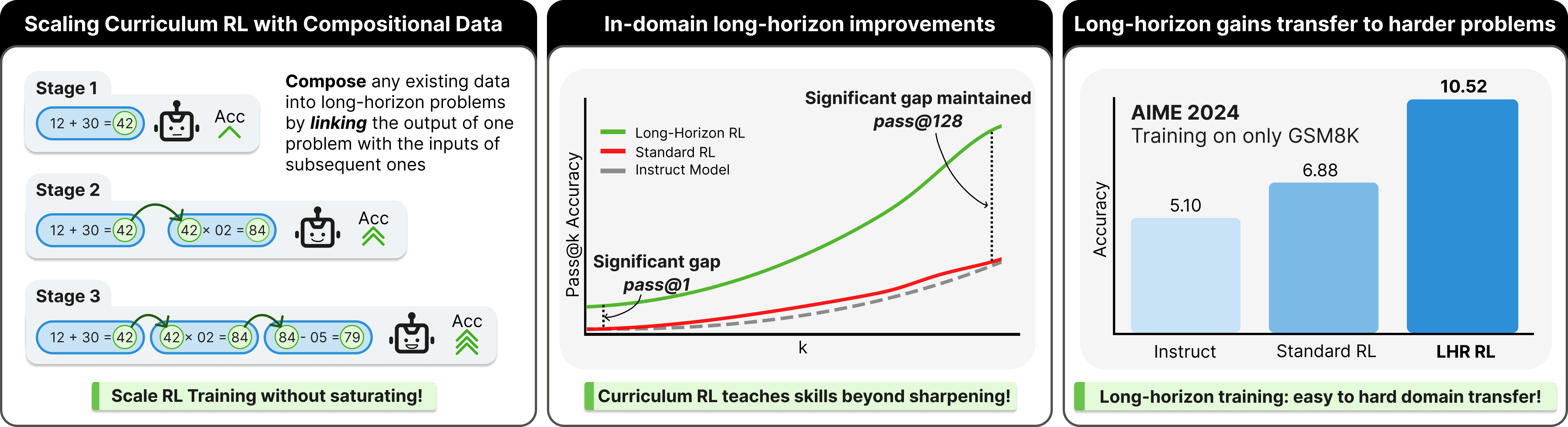
Think of solving problems like running a relay race: each runner passes the baton to the next. A “long-horizon” problem is like a relay with many runners. Each step has to be done correctly, and the baton (the information) must be passed along carefully. The authors:
- Built chains of short problems: They took typical math questions (like the ones in GSM8K, which are about 6th-grade math) and stitched them together so the answer from one question becomes part of the next question’s input. They used simple “adapters” like scaling numbers, adding/subtracting, or unit conversions to link steps. This creates longer sequences where the model must keep track of intermediate results.
- Trained with outcome-only rewards: They used reinforcement learning (RL) where the model gets a reward only if the final answer of the whole chain is correct—no step-by-step supervision needed. Think of a teacher who only grades the final result, not each intermediate step.
- Used a curriculum: Like learning to play piano with easier songs first, they trained in stages—starting with short chains (1–2 steps) and gradually moving to longer ones (3–5 steps). This helps the model learn the basics before tackling harder sequences, so the training doesn’t stall.
In technical terms, they used a modern RL training style similar to GRPO, but you can think of it as “try many solutions, reward the good ones, and nudge the model to do more of that,” increasing chain length over time.
What did they find, and why is it important?
They found several big improvements:
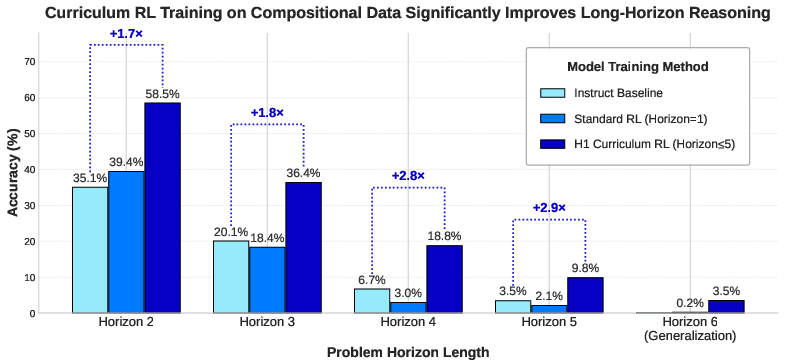
- In-domain gains on the constructed chain problems: Accuracy rose a lot as they trained on longer chains. For example, on 4-step chains, accuracy roughly tripled compared to the base model. On 5-step chains, it nearly tripled too. These gains show the model learned to carry and reuse intermediate results correctly, not just to guess single answers.
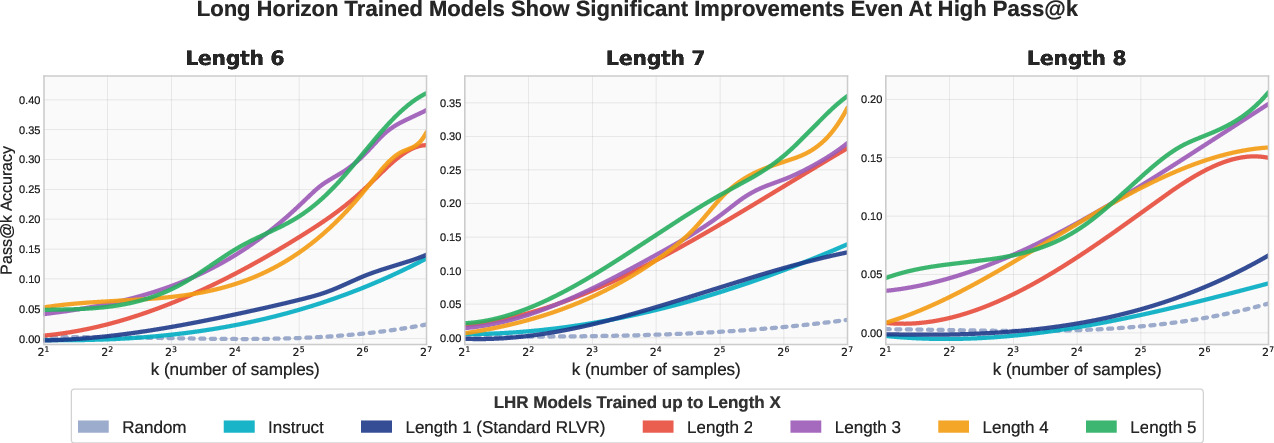
- New skills, not just better sampling: Even when they allowed the model to try many samples per question (pass@128), the curriculum-trained model beat the base model by a lot. That suggests it really learned new reasoning paths, not just “finding” good answers by trying more times.
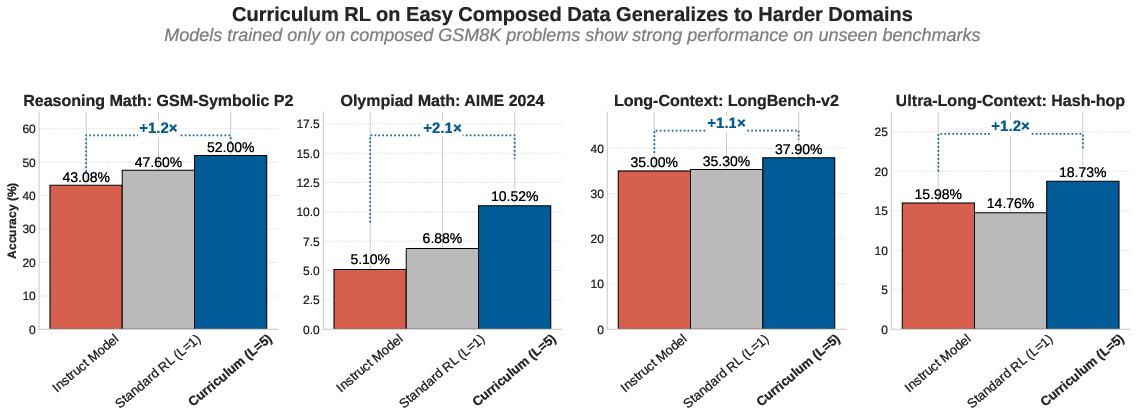
- Transfer to harder benchmarks: Training only on chained 6th-grade problems led to big jumps on tougher tests:
- AIME 2024 (an American math contest with hard problems): about 2.06× improvement.
- MATH-500 and GSM-Symbolic: noticeable gains.
- Long-context tests (LongBench-v2, Hash-hop): better performance at following very long chains of information and retrieving the right pieces.
- Theory backing the method: They explain why training directly on very long chains with a final-only reward is inefficient: the model rarely gets a correct final answer at first, so there’s little learning signal. A curriculum fixes this by starting where the model can succeed, then stretching its abilities. Mathematically, this shifts training from needing an “exploding” number of examples for long tasks to a manageable amount, similar to having detailed feedback at every step—but without needing step-by-step labels.
Why this matters: It shows you can teach LLMs to handle deeper reasoning using only existing simple data, a final-answer reward, and a smart training schedule—making it much more scalable and cost-effective.
What does this mean for the future?
- Better long reasoning with cheaper data: Instead of collecting expensive, step-by-step annotated problems, we can synthesize longer chains from easy problems and still train powerful reasoning skills.
- Stronger skills for real tasks: This can help with complex math, programming, research, and any job where many steps must be done in the right order and important intermediate results must be tracked.
- Practical training trade-offs: If you have more short data than long data (which is common), you can still reach high performance by training longer (more compute). The paper shows how to balance data costs and training time.
- A path to long-horizon agents: As models learn to manage state over many steps, they become more reliable at multi-stage tasks, not just responding to short questions.
In short, the paper presents a simple but powerful recipe: build longer practice problems from short ones, use final-answer rewards, and increase difficulty gradually. This helps LLMs learn to think further ahead—like training a sprinter to run a marathon, one mile at a time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to strengthen, generalize, and validate the paper’s claims.
- Data construction realism and breadth
- The composition adapters are simple (identity, scaling, unit conversion); it is unclear whether gains persist with richer dependencies (variable binding, symbolic transformations, branching, loops, distractors, or noisy transforms). Test non-linear/DAG compositions and stochastic adapters.
- The semantic coherence of chained sub-problems is not evaluated. Do models rely on formatting cues rather than true state tracking? Probe with paraphrases, reordered or interleaved steps, and noisy references.
- Compositional data are exclusively math-centric (GSM8K-like). It is unknown if the approach transfers to non-math domains (code synthesis, planning, multi-hop QA, scientific reasoning). Evaluate on HumanEval/MBPP, SWE-bench, HotpotQA, StrategyQA, scientific QA.
- Verification dependency
- The method relies on outcome-only verifiable answers. How can it extend to domains with weak/subjective or unverifiable outcomes (e.g., open-ended reasoning, research assistance)? Explore learned verifiers, probabilistic checks, or weak supervision.
- Explicit vs implicit horizon
- There is no method to estimate latent horizon on implicit-horizon tasks. Develop horizon estimators (e.g., via value-tracking probes) and adaptive curricula that schedule by estimated hardness rather than fixed length.
- No analysis of how curriculum progress should be triggered for implicit-horizon tasks (automatic promotion criteria, confidence thresholds, or success-rate targets).
- Curriculum design and stability
- Sensitivity to curriculum schedule (stage lengths, sampling per stage, horizon increments) is not explored. Provide ablations and adaptive curriculum policies (e.g., bandit or RL-based difficulty schedulers).
- Catastrophic forgetting across stages is unmeasured. Track retention of earlier horizons and consider interleaving/rehearsal or regularizers to mitigate forgetting.
- The maximum trained horizon is small (H=5); gains beyond that are limited on L-6–L-8. Can the method scale to H≫5 (e.g., 10–20+) without saturation? Characterize compute needed and when returns diminish.
- RL algorithmic choices
- Only Dr.GRPO is used. Compare with PPO, DAPO, KL-regularized policy gradients, Q/A-learning variants, outcome-based exploration methods, and PRM-based dense rewards under equalized compute.
- Theoretical “dense-reward equivalence” is not empirically validated. Test intermediate reward shaping (PRMs, step verifiers) to assess sample efficiency and stability in practice.
- No direct measurement of exploration/diversity during RL (policy entropy, solution diversity). Quantify whether curriculum mitigates diversity collapse and mode dropping.
- Measuring “new capabilities”
- The p–σ_j decomposition is hypothesized but not directly measured. Design diagnostics to estimate per-depth state-tracking reliability (σ_j), e.g., controlled probes that isolate carrying/transforming intermediate values.
- The “new capability” claim based on pass@k could be confounded by sampling or formatting artifacts. Add controls: match temperatures/top-k, analyze novelty of successful traces, and constrain inference-time compute to test capability vs sampling effects.
- Evaluation scope and rigor
- Generalization results focus on math and two long-context benchmarks; improvements on LongBench-v2 and Hash-hop are modest. Disentangle retrieval vs reasoning gains and test adversarially long contexts with distractors.
- Lack of step-level error analysis: Which failure modes persist (carry errors, unit drift, mis-binding)? Provide a taxonomy and targeted stress tests.
- Baselines are incomplete. Include: SFT on composed data, rejection-sampling finetuning, self-consistency distillation, PRM-based RL, and inference-time scaffolding methods, all under matched compute.
- Prompt-format dependence is untested. Evaluate robustness to altered chain formatting, absence of color tags, noisy references, or interleaved irrelevant text.
- Data hygiene and leakage
- Composed test chains may reuse or semantically overlap training atoms. Provide a rigorous split protocol (hashing, semantic dedup), release scripts, and report overlap statistics.
- Quantify distribution shift introduced by composition (e.g., length, lexical patterns). Ensure improvements are not artifacts of repeated templates or shallow heuristics.
- Compute and cost reporting
- Compute budgets (tokens/FLOPs/wall-time), sampling temperatures, batch sizes, and seeds are insufficiently specified. Provide detailed reproducibility artifacts and ablate compute vs data contributions to gains.
- The data–compute tradeoff study is preliminary. Characterize scaling laws across horizon distributions, compute budgets, and adapter diversity, including confidence intervals and convergence diagnostics.
- Theoretical assumptions and validation
- The theory assumes parameter separability across depths, boundedness, and L-smoothness; these may not hold in LLMs. Empirically validate assumptions or provide robustness analyses under parameter sharing/interference.
- The exponential-to-polynomial sample complexity improvement is not empirically demonstrated with SNR/variance measurements. Measure success rate, gradient norms, variance, and SNR vs horizon across training to confirm theoretical predictions.
- Robustness, alignment, and safety
- Potential reward hacking or shortcut behaviors are not analyzed (e.g., exploiting formatting, brittle cues). Audit reasoning-faithfulness and add detectors for degenerate strategies.
- Effects on instruction-following, helpfulness/harmlessness, and toxicity are unreported. Test for alignment regressions after RL and add guardrails if needed.
- Robustness to noise, typos, multilingual inputs, and domain shifts is untested. Evaluate under controlled corruptions and cross-lingual settings.
- Integration with other capabilities
- Interaction with long-context architectures (RAG, memory modules, SSMs) is unexplored. Can curriculum RL complement external memory and retrieval?
- Synergy with inference-time scaffolding/search is not studied. Jointly optimize training-time curricula with test-time strategies to understand tradeoffs and additive gains.
- Internal state and interpretability
- No probing of internal representations for state maintenance (e.g., linear probes for intermediate values). Develop interpretability tools to assess whether models genuinely track and transform state.
- Confidence calibration for long chains is unmeasured. Investigate uncertainty estimates and selective prediction under increasing horizons.
- Task structure beyond linear chains
- Real tasks often branch and require hierarchical planning. Extend from linear chains to trees/DAGs, optional subgoals, and loops; evaluate effects on planning and credit assignment.
- Adapter correctness and noise tolerance
- The method assumes deterministic, error-free adapters. Study robustness to imperfect adapters (unit ambiguities, rounding, symbolic noise) and quantify how adapter errors propagate across horizons.
- Practical deployment
- How to choose curriculum targets in production when horizon distributions are unknown? Develop online estimation of task difficulty and dynamic scheduling.
- Evaluate latency/throughput tradeoffs when scaling pass@k at inference versus training-time curriculum; quantify cost-effectiveness across deployment regimes.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s method of composing short-horizon tasks into chains and training with outcome-only RL under a horizon curriculum. Each item includes sector mapping, potential tools or workflows, and feasibility notes.
- Software engineering: multi-step code generation and debugging (software)
- Tools/workflows: compose atomic coding tasks (functions, tests) into dependency chains; reward via unit test pass/fail; integrate Dr.GRPO-style outcome-only RL into existing copilot training; add adapters for variable/state passing across files.
- Dependencies/assumptions: rich unit-test coverage and deterministic evaluation; sufficient short tasks (e.g., LeetCode-style) to synthesize longer chains; training compute budget for RL curricula.
- Data engineering and ETL pipelines: reliable multi-step transformations (software/data)
- Tools/workflows: chain atomic transforms (schema enforcement, normalization, joins) with validators (invariants, checksums); train LLMs to maintain state across steps; use outcome reward when end-to-end dataset property is satisfied.
- Dependencies/assumptions: definable end-state validators; access to short, verifiable ETL tasks; synthetic adapters (format conversions, scaling) that reflect real pipelines.
- Finance and accounting ops: invoice reconciliation and report preparation (finance)
- Tools/workflows: build compositional numeric workflows (currency conversion, tax application, aggregation); verify end totals against ground truth; deploy an “LedgerReasoner” assistant trained on composed short problems.
- Dependencies/assumptions: deterministic numeric outcomes; privacy-safe synthetic tasks derived from standard accounting steps; domain alignment between training chains and target procedures.
- Customer support triage: long multi-turn troubleshooting flows (software/enterprise)
- Tools/workflows: chain atomic steps (diagnostics → configuration → resolution) where final outcome is “issue resolved”; use outcome-only rewards from resolution logs (closed tickets); implement curriculum across increasing numbers of steps.
- Dependencies/assumptions: labeled resolution outcomes and reproducible troubleshooting scripts; consistent logging to verify success; risk of non-determinism in real-world support environments.
- Legal and compliance clause tracking: long-document reasoning (policy/legal)
- Tools/workflows: train on synthetic clause chains (extraction → normalization → policy matching) with checklists/verifiable end decisions; integrate into compliance review workflows; evaluate improvements on long-context benchmarks (e.g., LongBench-like internal suites).
- Dependencies/assumptions: availability of labeled compliance decisions as outcome rewards; adapters for document references and units (dates, monetary terms); domain shift risk from math-to-legal requires domain-specific atomic tasks.
- Education: adaptive curriculum generation and tutoring for math (education)
- Tools/workflows: compose 6th–10th grade math tasks into progressive chains; train tutoring models to maintain state and carry intermediate results; deploy “LHR curriculum generator” for teachers and edtech platforms.
- Dependencies/assumptions: large supply of short math problems with verifiable answers; alignment between synthetic chain difficulty and student proficiency; careful guardrails to avoid hallucinations in open-ended explanations.
- Retrieval-augmented generation (RAG): multi-hop retrieval with state tracking (software)
- Tools/workflows: evaluate and train on Hash-hop-like tasks; add explicit variable binding adapters; integrate a “Stateful RAG orchestrator” that preserves and validates multi-hop chains; monitor pass@k improvement to confirm learned capabilities.
- Dependencies/assumptions: strong document stores and verifiable question-answer tasks; instrumented pipelines to check end correctness; domain-specific adapters for IDs, hashes, and references.
- ML training operations: LHR outcome-only RL pipeline (software/ML)
- Tools/workflows: deploy a “Horizon Scheduler” to stage training lengths; “Adapter libraries” to compose domain tasks; reward verifiers for outcome-only signals; SNR monitoring to set batch sizes; compute–data tradeoff planner (skewed short data with more compute).
- Dependencies/assumptions: access to short-horizon verifiable data; RL infrastructure (Dr.GRPO-like); sufficient compute tokens to compensate for low long-horizon data.
- Scientific literature QA: long-context question answering (academia)
- Tools/workflows: chain atomic tasks (extract → normalize → compare → conclude) over papers; validate final answers against known facts/datasets; use LongBench-style internal benchmarks to track gains in distant reference tracking.
- Dependencies/assumptions: curated QA datasets with known answers; domain adapters (units, citations) to preserve state; careful evaluation to avoid shortcut learning.
- Benchmarking and audits: stress-testing LHR for procurement or model governance (policy/enterprise)
- Tools/workflows: build explicit-horizon synthetic suites to test model LHR; report pass@k curves to detect new capability acquisition beyond base models; certify models for long-horizon tasks.
- Dependencies/assumptions: standardized atomic tasks per domain; evaluation harness with outcome verifiers; governance buy-in on synthetic-to-real transfer.
Long-Term Applications
The following applications require further research, domain adaptation, scaling, and/or safety validation. They leverage the method’s theoretical sample-complexity benefits and demonstrated generalization to longer, harder tasks.
- Robotic planning and manipulation: multi-step task execution (robotics)
- Tools/products/workflows: use simulation to compose short manipulation primitives into longer plans (pick → place → tool use → verification); outcome-only reward via simulator success; stagewise curricula across horizon lengths to stabilize training.
- Dependencies/assumptions: high-fidelity simulators and accurate success signals; safe sim-to-real transfer; adapters mapping intermediate physical states; integration with control stacks.
- Clinical decision support: longitudinal diagnostic reasoning (healthcare)
- Tools/products/workflows: chain atomic clinical reasoning tasks (lab interpretation → risk scoring → guideline application) with outcome-only rewards from simulated cases; use curricula to teach long-horizon state tracking across visits.
- Dependencies/assumptions: high-quality labeled patient case simulators; rigorous validation and regulatory approvals; safeguards against spurious correlations; privacy constraints.
- Autonomous software agents for complex projects (software)
- Tools/products/workflows: “AutoDev with LHR” coordinating multi-day tasks (requirements → design → coding → testing → deployment); adapters for artifacts and tickets; outcome-only rewards from integration/test success and user acceptance tests.
- Dependencies/assumptions: reliable multi-stage verifiers; orchestration over tools (CI/CD, issue trackers); robust memory/state mechanisms; extensive compute.
- Scientific discovery orchestrators (academia/industry R&D)
- Tools/products/workflows: experiment planning assistants that chain hypothesis → design → analysis → replication; verify outcomes via lab automation; train curricula to extend planning horizons and reduce compounding errors.
- Dependencies/assumptions: closed-loop labs or simulators; well-defined success criteria per domain; mechanism to avoid reward hacking; significant domain-specific adapters.
- Grid and energy operations: multi-step scheduling and optimization (energy)
- Tools/products/workflows: chain short tasks (forecasting → dispatch → contingency analysis) with simulators; outcome-only reward via stability/cost metrics; curriculum to scale to day/week horizons.
- Dependencies/assumptions: accurate digital twins; access to operational data; alignment with dispatch constraints; regulatory compliance.
- Supply chain and logistics planning: multi-echelon optimization (enterprise)
- Tools/products/workflows: composed tasks (demand planning → replenishment → routing → risk checks); outcome reward from KPI improvements in simulation; horizon curricula for seasonal planning.
- Dependencies/assumptions: validated simulators and KPIs; adapters for units, lead times, and constraints; integration with ERP systems.
- Legal research assistants for complex case synthesis (policy/legal)
- Tools/products/workflows: chain tasks (precedent retrieval → argument mapping → contra analysis → synthesis) with outcome reward via expert-validated decisions; curriculum to extend argument depth/horizon.
- Dependencies/assumptions: gold-standard labels are costly; partial verifiability may require PRMs or hybrid supervision; ethical and jurisdictional constraints.
- Education platforms for cross-subject long assignments (education)
- Tools/products/workflows: longitudinal tutoring systems that track state across weeks (projects, essays, lab work); outcome rewards via rubric-based automated grading; curriculum-based training to improve sustained reasoning and planning.
- Dependencies/assumptions: reliable rubrics and graders; guardrails against hallucination; student privacy and fairness audits.
- Quantitative research assistants: end-to-end modeling workflows (finance)
- Tools/products/workflows: chain tasks (data prep → feature engineering → modeling → backtesting → reporting); outcome reward via profit/risk metrics in simulation; train on longer horizons for strategy development.
- Dependencies/assumptions: robust backtesting frameworks; avoidance of overfitting/reward hacking; governance and compliance checks.
- Knowledge management for enterprises: stateful long-document assistants (software/enterprise)
- Tools/products/workflows: assistants that track variables/commitments across large corpora; validate end decisions (policy adherence, budget constraints); train with horizon curricula on domain-specific atomic tasks.
- Dependencies/assumptions: strong verification signals; domain-tailored adapters (IDs, units, cross-references); data governance.
Notes on Feasibility and Dependencies
- Outcome-only rewards require verifiable end states; tasks with ambiguous or subjective outcomes may need hybrid supervision (e.g., PRMs).
- Synthetic composition hinges on a large corpus of short, verifiable tasks and domain-specific adapters (unit conversion, scaling, reference binding).
- Transfer performance depends on domain similarity; cross-domain gains (e.g., math → legal) typically need domain-specific atomic tasks and evaluators.
- RL stability and compute: curricula mitigate vanishing signal and saturation, but teams need Dr.GRPO-like infrastructure, SNR monitoring, and budget planning (compute–data tradeoffs).
- Safety, privacy, and compliance: healthcare, finance, and legal applications demand rigorous validation, auditability, and regulatory alignment before deployment.
- Theoretical guarantees assume separated parameterization and non-degenerate success probabilities; real-world systems may need instrumentation to maintain signal at increasing horizons.
Glossary
- advantage estimator: A variance-reduction technique in policy gradient methods that subtracts a baseline from returns to stabilize updates. Example use: "an unbiased advantage estimator with constant baseline equal to the same-horizon mean"
- adapter: A simple deterministic mapping that transforms an intermediate answer into the next sub-problem’s input in a composed chain. Example use: "A lightweight adapter maps to the next input:"
- AIME: A challenging math competition benchmark (American Invitational Mathematics Examination) used to test advanced reasoning. Example use: "AIME 2024"
- atomic tasks: Short, self-contained problems that serve as building blocks for longer composed chains. Example use: "We begin with atomic tasks : short, self-contained problems"
- Chain-of-Thought (CoT): An explicit multi-step reasoning process expressed in natural language. Example use: "chain of thought (CoT)"
- curriculum learning: A training strategy that increases task difficulty in stages to improve learning efficiency and stability. Example use: "with curriculum learning and outcome-only rewards"
- dense rewards: Reward signals provided at intermediate steps rather than only at the terminal outcome, improving learning signal. Example use: "dense, per-step rewards"
- Dr. GRPO: A GRPO-based reinforcement learning algorithm variant used for optimizing LLMs during curriculum stages. Example use: "run Dr. GRPO \citep{liu2025understandingr1zeroliketrainingcritical} on "
- explicit-horizon: Tasks whose number of dependent sub-problems is known and controlled during training and evaluation. Example use: "Explicitâhorizon tasks have a known number of dependent subâproblems "
- GRPO: Group Relative Policy Optimization, a policy-gradient method for LLM RL that uses group-based baselines. Example use: "outcomeâonly GRPO following a curriclum learning approach"
- GSM-Symbolic: A symbolic reasoning extension of GSM-style math questions used to test compositional reasoning. Example use: "GSM-Symbolic P1"
- GSM8K: A dataset of grade-school math word problems commonly used to train and evaluate reasoning in LLMs. Example use: "composed 6th-grade level math problems (GSM8K)"
- Hash-hop: An ultra-long-context benchmark requiring multi-hop retrieval and traceable state updates over very long inputs. Example use: "Hash-hop tests ultra-long-context storage, retrieval, and multi-hop variable tracing"
- implicit-horizon: Tasks that require multiple dependent reasoning steps but lack an explicit labeled decomposition. Example use: "Implicitâhorizon tasks require multiple dependent reasoning steps"
- length generalization: The ability of a model to extrapolate to longer sequences than those seen during training. Example use: "Length generalization is concerned with extrapolating to longer sequence lengths than those seen during training"
- long-context benchmarks: Evaluations that measure model performance on very long inputs requiring distant dependency tracking. Example use: "We now evaluate our GSM8K LHR models on OOD long-context benchmarks"
- LongBench-v2: A benchmark suite testing understanding and reasoning over extremely long inputs, including documents and code. Example use: "LongBench-v2 measures understanding and reasoning over QA documents"
- long-horizon reasoning (LHR): The capability to carry out stateful, multi-step dependent reasoning over extended chains of sub-problems. Example use: "Long-horizon reasoning (LHR) refers to the capability of reliably carrying out a stateful reasoning process"
- MATH-500: A benchmark of challenging math problems used to evaluate advanced mathematical reasoning. Example use: "MATH-500"
- MMLU Pro Math: A subset of MMLU focusing on professional-level math knowledge and reasoning. Example use: "MMLU Pro Math"
- OOD: Out-of-distribution; refers to evaluating models on data that differs from their training distribution. Example use: "OOD improvements."
- outcome-only rewards: Terminal rewards given solely based on the final correctness of an entire reasoning chain. Example use: "using outcome-only rewards under a curriculum"
- pass@k: A metric indicating whether any of k sampled solutions is correct, used to assess sampling-based reasoning. Example use: "even at high pass@k"
- promotion rule: A criterion for advancing to the next horizon in the curriculum once a step’s reliability is high enough. Example use: "promotion rule "
- Qwen-2.5-3B Instruct: A specific instruction-tuned LLM used as the base model for experiments. Example use: "We use the Qwen-2.5-3B Instruct model"
- REINFORCE: A classic policy gradient algorithm used to estimate gradients from sampled returns. Example use: "We use REINFORCE \citep{williams1992reinforce}"
- reward shaping: The practice of modifying reward structures (e.g., adding intermediate rewards) to improve learning efficiency. Example use: "similar work on reward shaping"
- reward-to-go: The cumulative future reward from a given step, used in policy gradient estimators. Example use: "use the reward-to-go estimator at depth "
- RLVR: Reinforcement Learning with Verifiable Rewards; RL using tasks whose correctness can be automatically verified. Example use: "RL with verifiable rewards (RLVR)"
- sample complexity: The amount of data required to learn a target performance level; often analyzed as scaling with horizon length. Example use: "achieves an exponential improvement in sample complexity over full-horizon training"
- signal-to-noise ratio (SNR): A measure of gradient estimator quality comparing its expected signal to its variance. Example use: "signal-to-noise ratio (SNR)"
- SFT: Supervised Fine-Tuning; training a model directly on input-output pairs without reinforcement signals. Example use: "we simplify our experimental setup to a SFT setting"
- stagewise curriculum: A curriculum that trains at one horizon length per stage, progressively increasing the horizon. Example use: "Our curriculum is stagewise:"
- step-level supervision: Intermediate labels for each step in a reasoning chain, as opposed to only final outcomes. Example use: "costly step-level supervision"
- verifier: A procedure that checks final outputs and assigns rewards based on correctness in RL training. Example use: "the verifier pays terminal reward "
Collections
Sign up for free to add this paper to one or more collections.