- The paper presents the DeCE framework which decomposes evaluation into precision and recall for assessing LLM outputs.
- It shows that generalist models achieve higher recall while specialized models demonstrate greater precision accuracy.
- The framework correlates at 0.78 with expert evaluations, significantly outperforming metrics like BLEU and ROUGE.
"Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses"
Introduction to DeCE Framework
"Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses" addresses fundamental challenges in evaluating LLM-generated content within high-stakes domains such as law and medicine. Traditional metrics like BLEU and ROUGE often fail to capture the semantic accuracy required for these tasks. The paper introduces the DeCE framework, which evaluates LLM responses using decomposed criteria for precision and recall, derived from instance-specific gold answer requirements. This approach is model-agnostic and does not require predefined taxonomies.
This framework provides a refined correlation with expert judgments (r=0.78) compared to existing evaluation methods, which achieve much lower correlation results. The paper demonstrates that while generalist models show higher recall, specialized models exhibit increased precision.
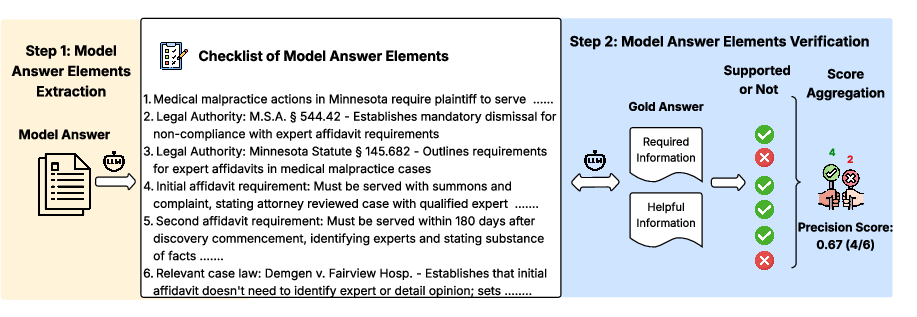

Figure 1: Precision Workflow
Framework Architecture and Implementation
Pipeline Overview
DeCE consists of two primary workflows: precision and recall. Each workflow utilizes model-generated answers and gold-standard answers to provide interpretable evaluations.
- Precision Workflow: This process decomposes the model-generated answer into factual elements. Each element is verified for factual accuracy and relevance against the gold answer. Unsupported elements result in penalization in the final score.
- Recall Workflow: This component extracts evaluation criteria from the gold answer and evaluates the completeness of the model responses based on Required Information. This dimension explicitly checks coverage of necessary concepts.
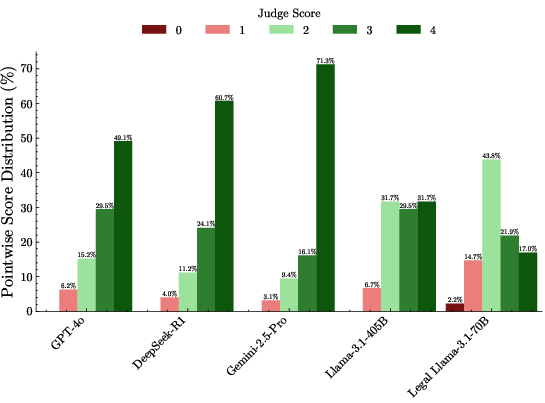
Figure 2: Distribution of pointwise scores (0–4) for each model
DeCE Score Implementation
The decomposition into precision and recall offers an interpretable signal, allowing evaluators to identify specific shortcomings in the model outputs. The precision score is calculated as the proportion of correctly grounded elements, while the recall score measures the completeness of essential concept coverage.
Experimental Evaluation and Results
Evaluation of Model Alignment
In a comprehensive comparative analysis, DeCE showed substantial improvement in alignment with expert evaluations over standard metrics such as ROUGE and BLEU.
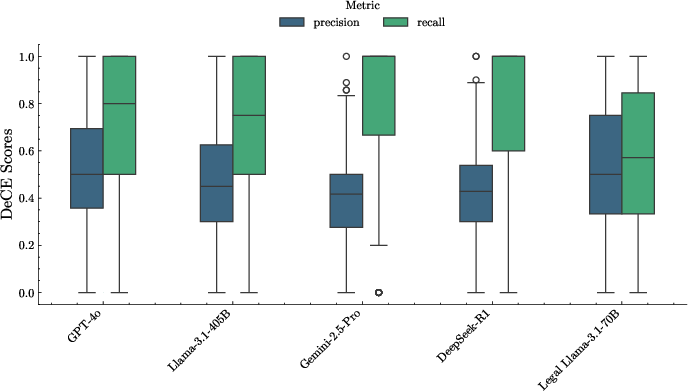
Figure 3: DeCE scores (precision and recall) for each evaluated model
The precision and recall decomposition revealed that larger, general-purpose models tend to favor recall with comprehensive answers, while smaller, domain-specific models focus on precision.
The effectiveness of DeCE extends to diagnosing model outputs across different jurisdictions and query types, highlighting challenges in certain legal reasoning problems and jurisdictions such as Minnesota and New York.
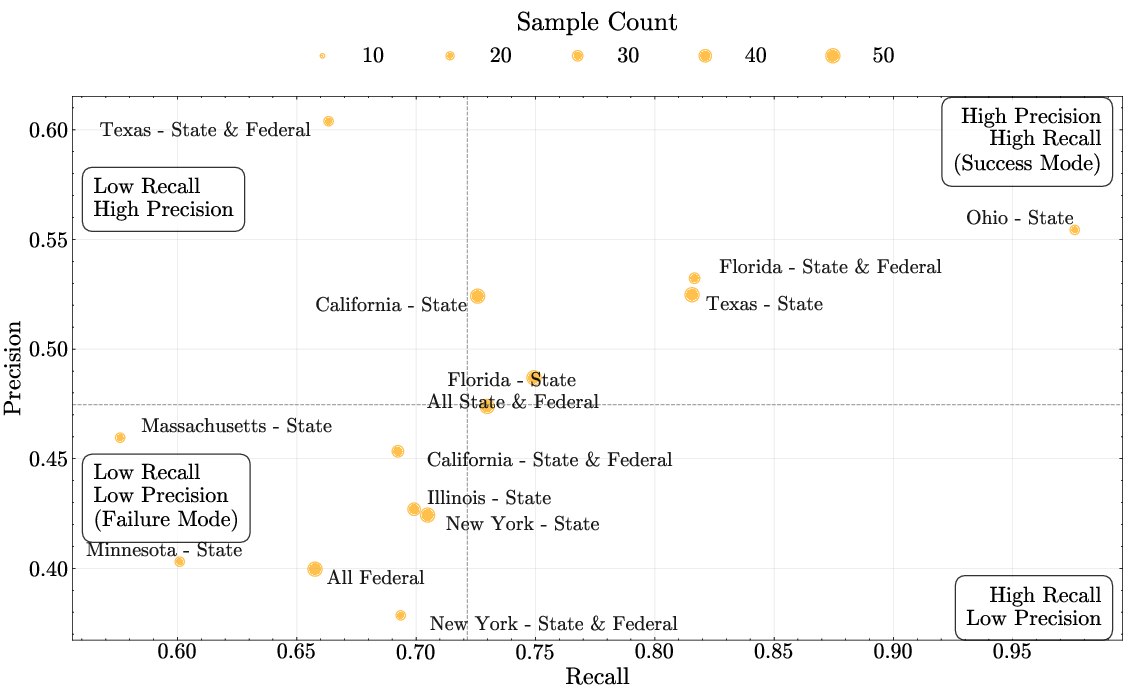
Figure 4: Model performance across jurisdictions insights (precision vs. recall)
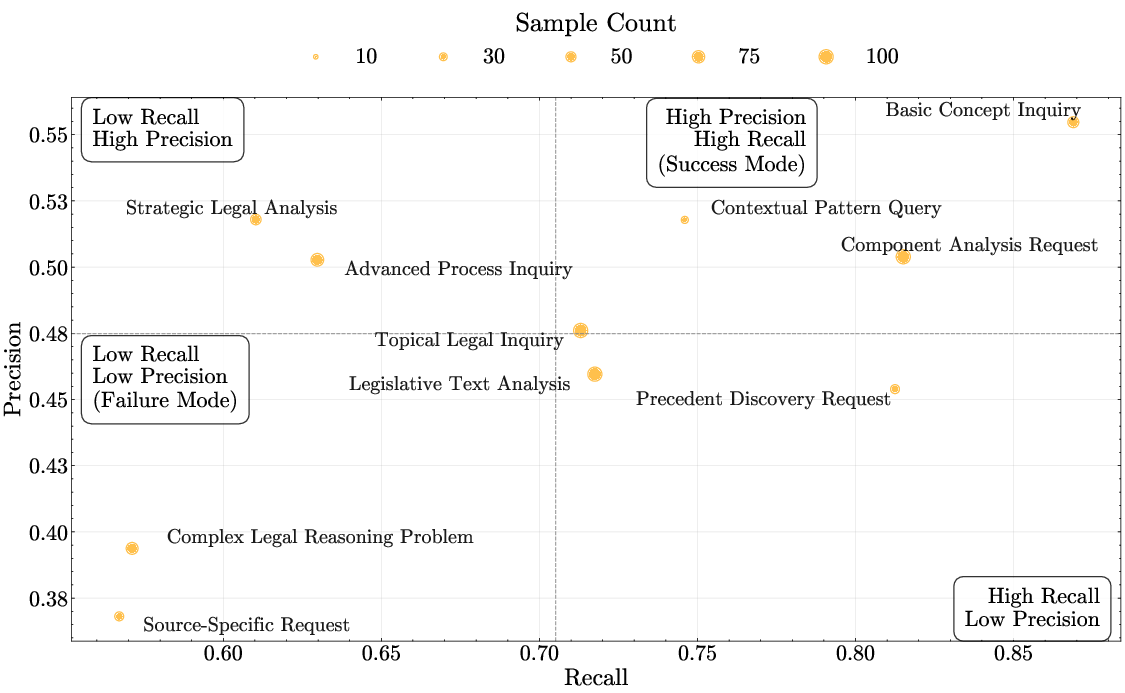
Figure 5: Model performance across query types (precision vs. recall)
Implications and Future Work
This research proposes significant advancements in how LLM outputs can be evaluated beyond holistic scores, specifically in complex domains requiring nuanced understanding. While DeCE significantly outperforms existing methodologies, it also paves the way for further research into domain-specific evaluation criteria and enhances the alignment with human expert evaluations.
Future directions could involve integrating human-in-the-loop methods for more challenging jurisdictions and query types, as well as adapting DeCE to other high-stakes domains like healthcare and finance.
Conclusion
The DeCE framework provides a robust, scalable, and interpretable approach to evaluating LLM outputs in expert domains. By distinguishing between precision and recall, it highlights the strengths of general and specialized models and provides actionable insights for improving model deployment strategies in high-stakes environments. This paper establishes a foundation for more nuanced AI evaluation frameworks, crucial for the advancement of trustworthy AI systems in expert settings.