- The paper introduces the Caco framework that automates scalable reasoning data synthesis by leveraging code-assisted chain-of-thoughts.
- The methodology unifies code-based reasoning with automated validation through reverse-engineered natural language instructions.
- Experimental results demonstrate that Caco-trained models outperform baselines on GSM8K and MATH benchmarks, enhancing algorithmic problem solving.
Scaling Code-Assisted Chain-of-Thoughts and Instructions for Model Reasoning
This essay provides an expert review of the paper titled "Scaling Code-Assisted Chain-of-Thoughts and Instructions for Model Reasoning" (2510.04081), which explores the automation of high-quality reasoning data synthesis in LLMs through a novel framework known as Caco.
Caco leverages code-driven augmentation to create scalable, verifiable reasoning data sets, addressing challenges in reasoning reliability, scalability, and diversity in current Chain-of-Thought (CoT) prompting methods. The framework demonstrates significant improvements over existing baselines in mathematical reasoning tasks and suggests broader applications across algorithmic domains.
Introduction and Background
The paper begins by discussing the limitations inherent to traditional CoT prompting, namely unverifiability, scalability issues, and limited diversity. Recent work in code-assisted reasoning attempts to mitigate these shortcomings by translating natural language logic into executable code snippets, providing a base for automatic validation. However, existing approaches remain restricted to predefined mathematical problems, limiting their scope.
Caco stands out by fine-tuning a base LLM on existing math and programming solutions in code format, automating the synthesis of diverse reasoning traces across various tasks. Through enforced verification via code execution and diversity filtering, Caco transforms logical codes into natural language instructions, enabling scalable synthesis of reasoning data.
Methodology
The paper presents the overall architecture of the Caco framework, comprising multiple phases of data generation and validation:
- Unifying Code CoT: This phase consolidates reasoning steps from diverse domains into a unified code format, ensuring consistent execution and interpretation across tasks.
- Scaling with CodeGen: A CodeGen model, trained on the unified Code CoT dataset, creates large-scale diverse Code CoTs, exploiting the LLM's generative capacity to explore novel reasoning patterns.
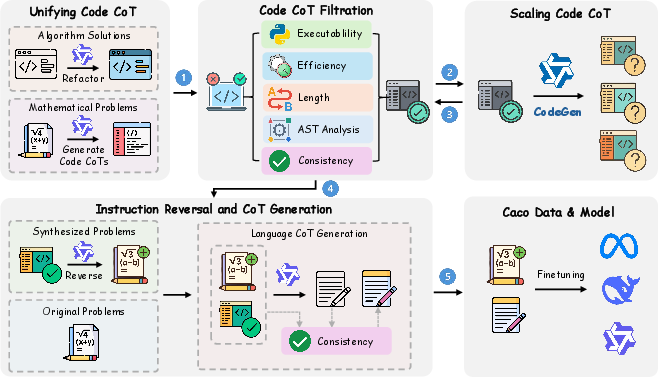
Figure 1: An overview framework of Caco data generation, including unifying Code CoT, scaling Code CoT with CodeGen, and instruction reversal and language CoT generation.
- Instruction Reversal and Language CoT Generation: The validated code solutions are reverse-engineered into natural language instructions, thereby enriching task adaptability and generalization.
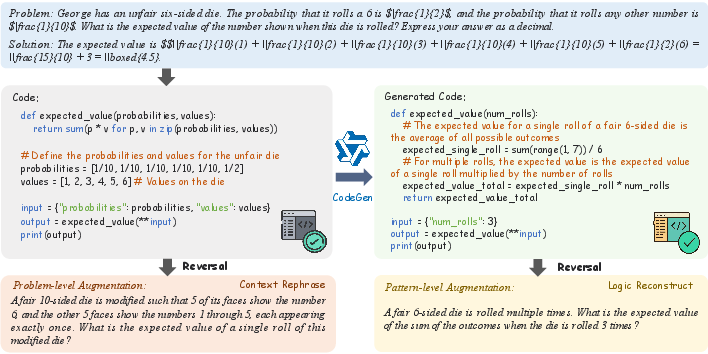
Figure 2: A case of one problem with its Code CoT. We demonstrate two augmentations, where problem-level augmentation refers to the original Code CoT can be back-translated into multiple question variants, and pattern-level augmentation means our CodeGen is capable of generating novel Code CoTs that generalize beyond the original seed patterns.
Experiments and Results
Extensive experiments conducted on the newly developed Caco-1.3M dataset showcase superior performance in mathematical reasoning benchmarks compared to strong baseline models. Caco-trained models not only demonstrate heightened accuracy on GSM8K and MATH datasets but also maintain strong generalization capability across unseen tasks.
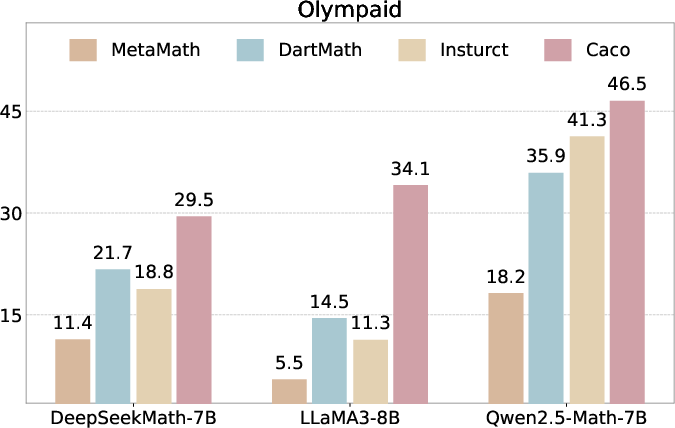
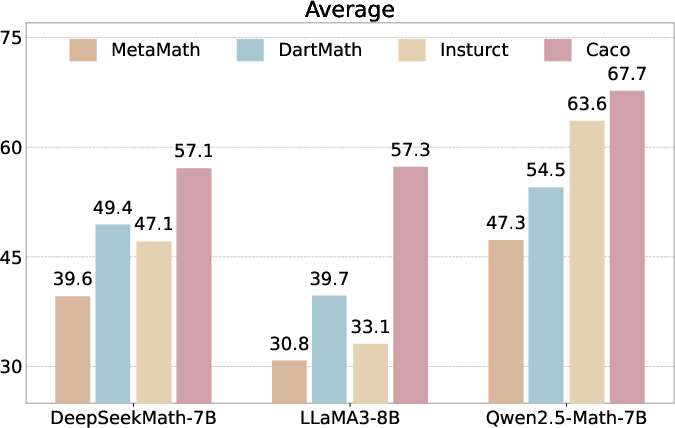
Figure 3: Overview of results, showing superior performance on Olympiad Bench and on average than baseline methods.
Analysis and Implications
The paper's detailed analysis of the Caco framework highlights several strengths: the systematic code-driven validation enhances data reliability, the diversity of instruction sets bolsters generalization, and the code-based augmentation allows scalability beyond traditional limits. Beyond solidifying performance in mathematical reasoning, the research points to broader applications in algorithmic reasoning and other structured data tasks.
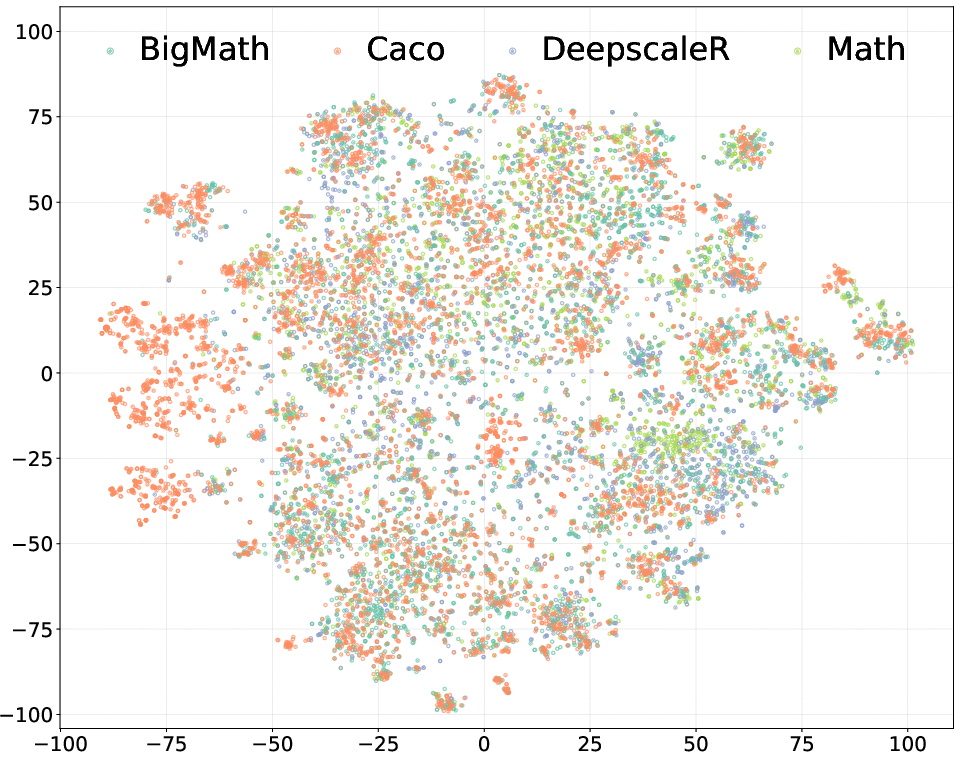
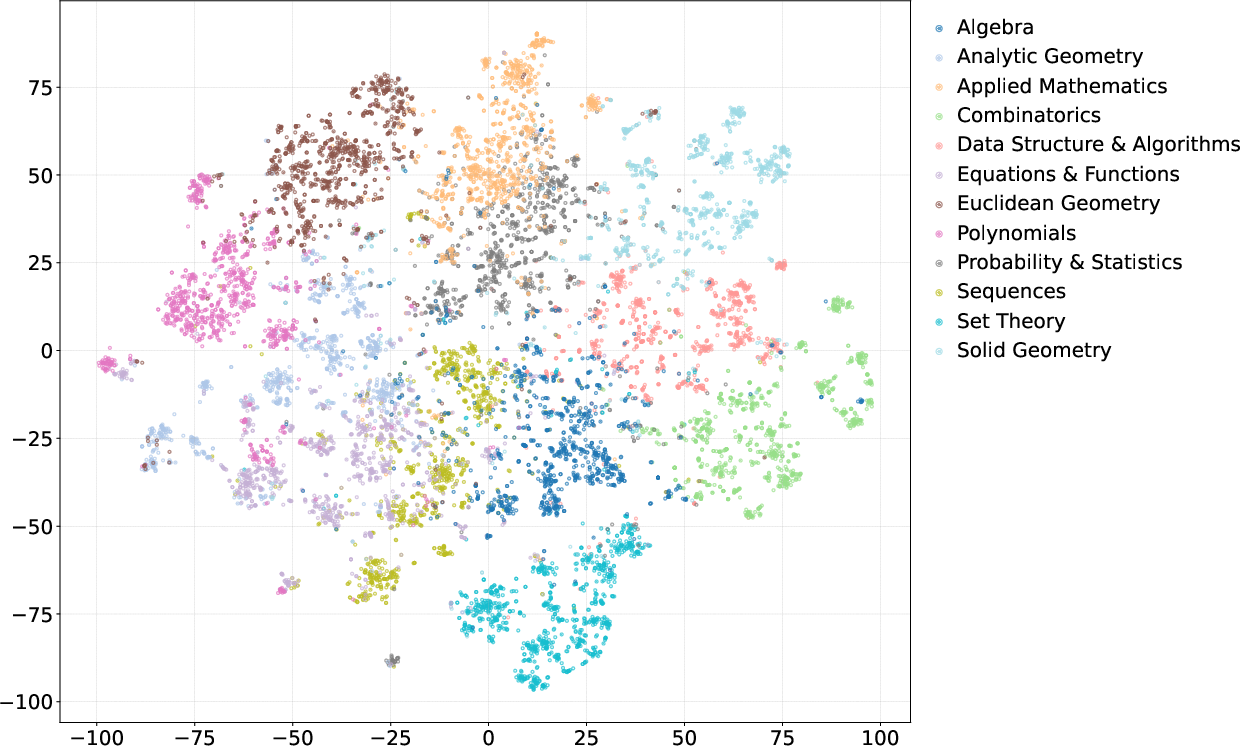
Figure 4: Left: Problem distribution of our Caco dataset and the original data sources. Right: KMeans clustering result of the problem types.
Future Directions
The framework's success in automating high-quality reasoning data synthesis without human intervention suggests potential extensions, including exploring application domains like logic puzzles and scientific reasoning. Further developments could integrate code verification mechanisms with RL strategies to create self-sustaining models.
Conclusion
The research articulated in "Scaling Code-Assisted Chain-of-Thoughts and Instructions for Model Reasoning" provides a robust model for automating reasoning data generation through code, highlighting significant improvements over existing methodologies in reasoning reliability and scalability. The insights shared pave the way for developing trustworthy reasoning systems capable of generalizing across diverse domains.