Neural Correlates of Language Models Are Specific to Human Language
Abstract: Previous work has shown correlations between the hidden states of LLMs and fMRI brain responses, on language tasks. These correlations have been taken as evidence of the representational similarity of these models and brain states. This study tests whether these previous results are robust to several possible concerns. Specifically this study shows: (i) that the previous results are still found after dimensionality reduction, and thus are not attributable to the curse of dimensionality; (ii) that previous results are confirmed when using new measures of similarity; (iii) that correlations between brain representations and those from models are specific to models trained on human language; and (iv) that the results are dependent on the presence of positional encoding in the models. These results confirm and strengthen the results of previous research and contribute to the debate on the biological plausibility and interpretability of state-of-the-art LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a big question: do today’s AI LLMs think about language in ways that are similar to the human brain? The authors compare activity inside AI models to brain activity from people reading sentences, and they find that the strongest similarities happen only when the AI was trained on real human language and when it uses word order. They also show these results hold up even when they compress the data and when they use different ways of measuring similarity.
What were the main questions?
The authors looked at four simple questions:
- Are the similarities between AI models and brain activity real, or just a side effect of dealing with huge amounts of data?
- Do the similarities show up even when we use new, stricter ways to compare model and brain activity?
- Do we only see these similarities in models trained on human language, or also in models trained on other kinds of data (like proteins)?
- Does the AI’s sense of word order (called positional encoding) matter for matching the brain?
How did they test this?
Think of the brain and an AI model as two different “machines” that both react to sentences. The researchers compared their reactions in a few careful steps:
- fMRI brain scans: Six adults read 243 simple sentences. An fMRI scanner recorded their brain activity, which you can imagine like a big “heat map” showing which parts of the brain light up for each sentence.
- AI LLMs: They tested 19 transformer models (the kind used in many modern AI systems). There were two types:
- Bidirectional models (like BERT): They see the whole sentence at once.
- Causal models (like GPT): They read left-to-right, predicting the next word, more like how humans read.
- Word order “on” vs “off”: They ran each model twice—once with positional encoding (word order signals turned on), and once after removing it, like shuffling word positions so the model can’t rely on order cues.
- Matching model to brain: They trained simple formulas to predict brain activity from the AI’s internal signals and checked how well the predictions matched real brain data (this is what “correlation” means here—how close the model comes to the brain’s response).
- Data compression test (PCA): They compressed the brain data down to fewer numbers (like shrinking a huge photo to a smaller version that still keeps most of the important details) to see if matching was just a “big-data trick” or truly meaningful.
- Extra similarity checks (CKA and GW): They used two more advanced tools:
- CKA: Think of it as comparing how two systems organize relationships among sentences.
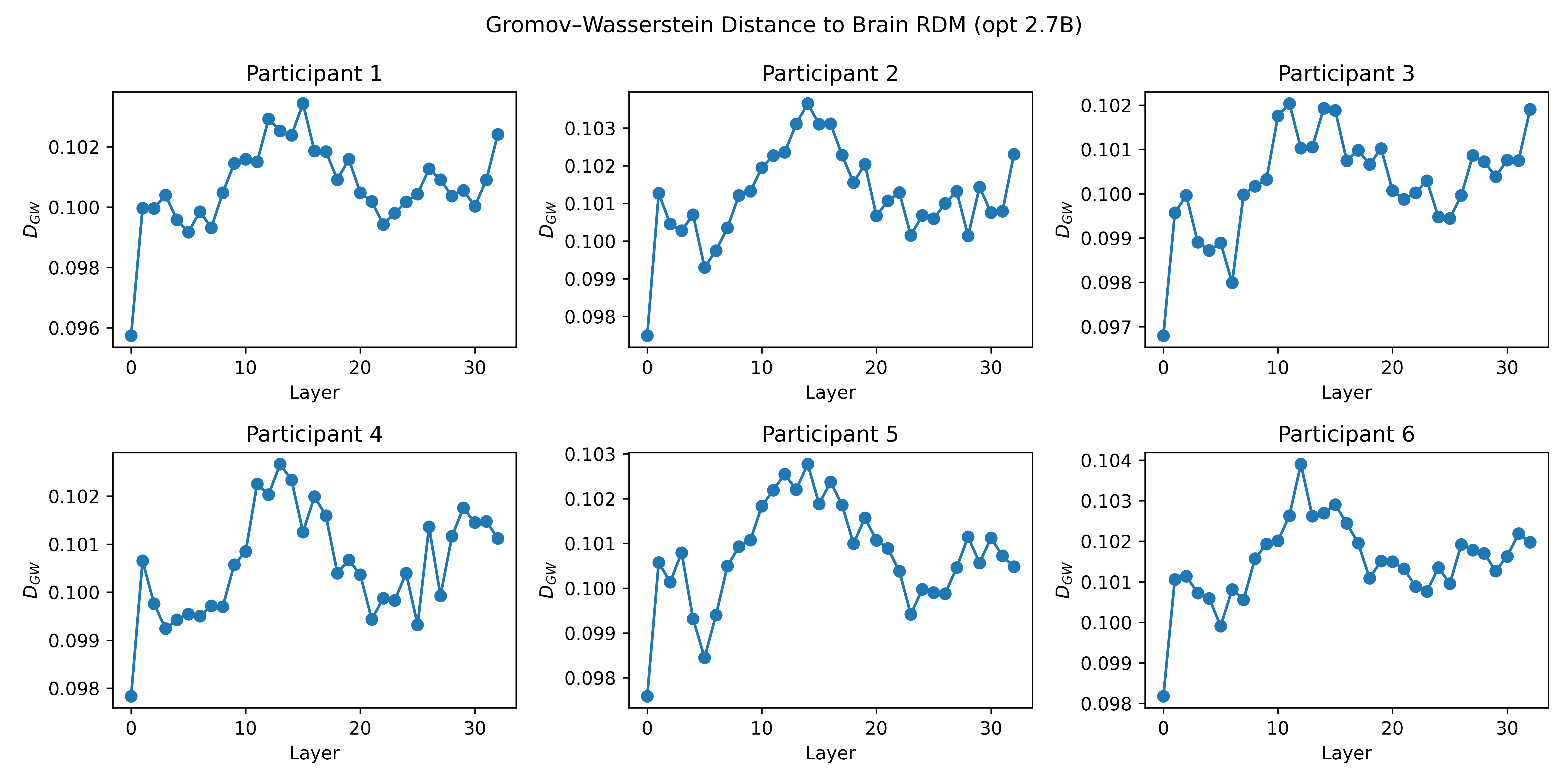
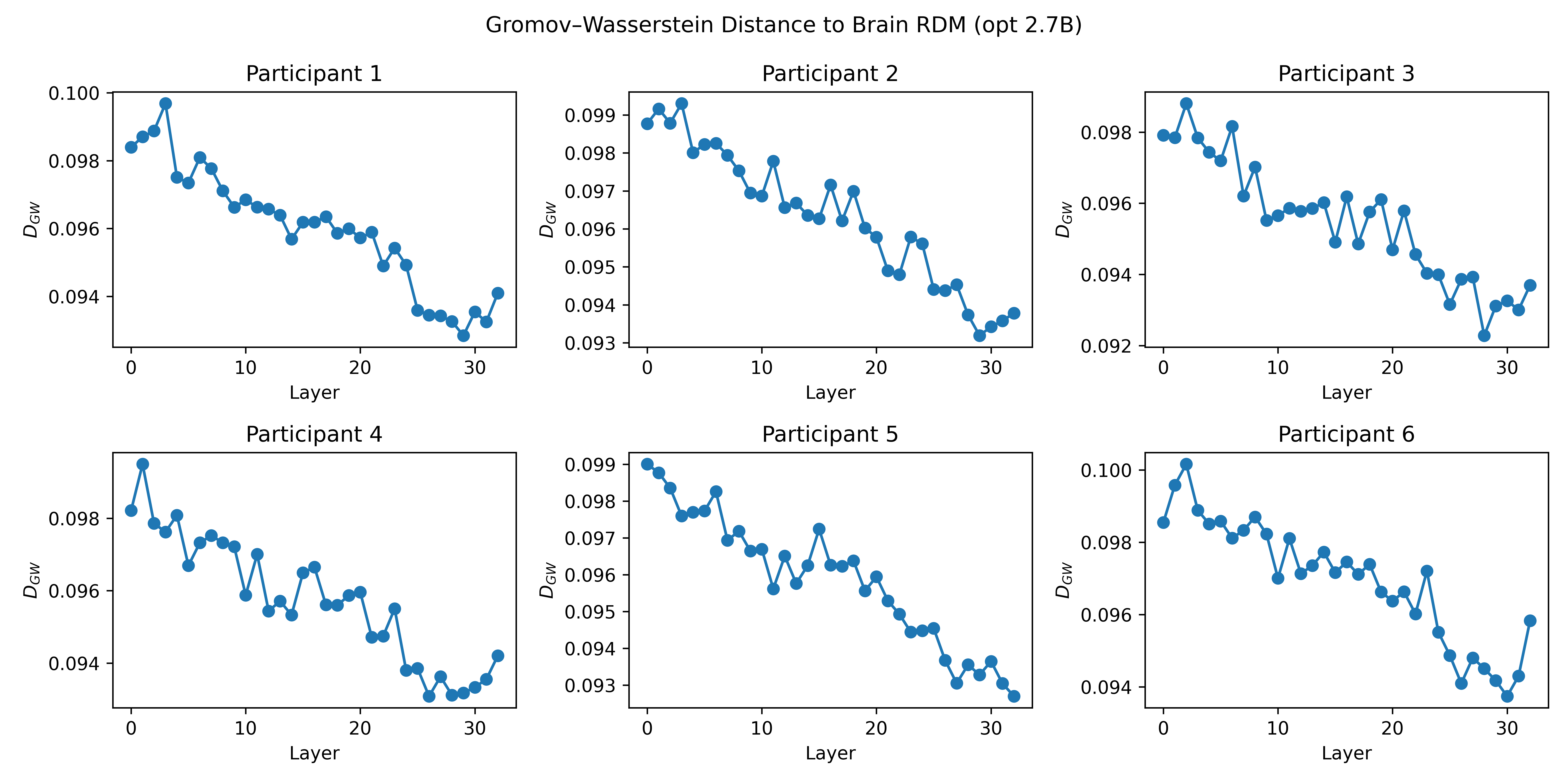
- Gromov–Wasserstein distance (GW): Think of comparing the “shape” of two maps—if the pattern of distances among sentences in the model is similar to the pattern among sentences in the brain, the shapes align.
- Language-specific test: They tried models trained on protein sequences (not human language) but with the same architecture, to see if training data matters.
What did they find, and why does it matter?
Here are the key results, explained simply:
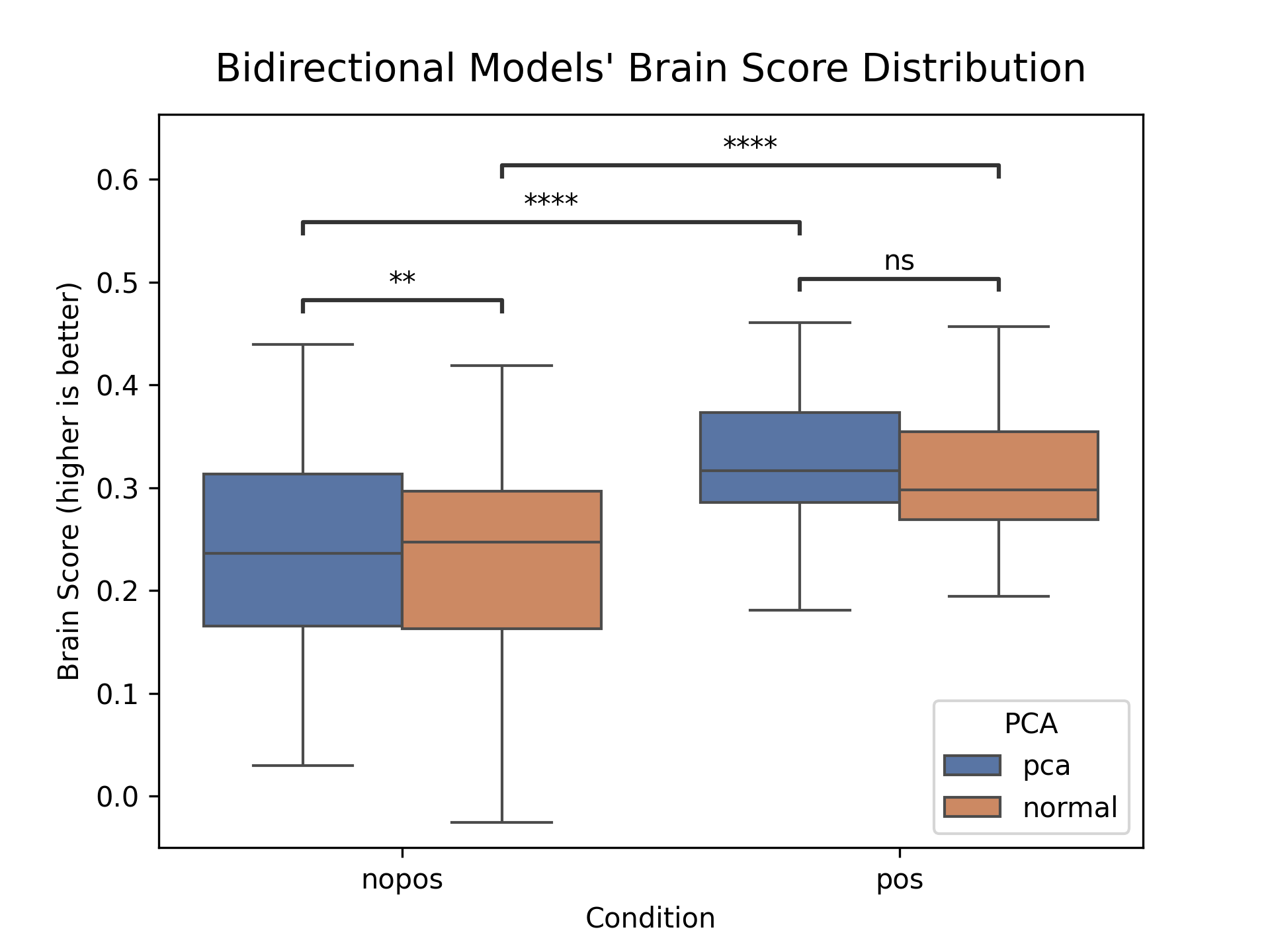
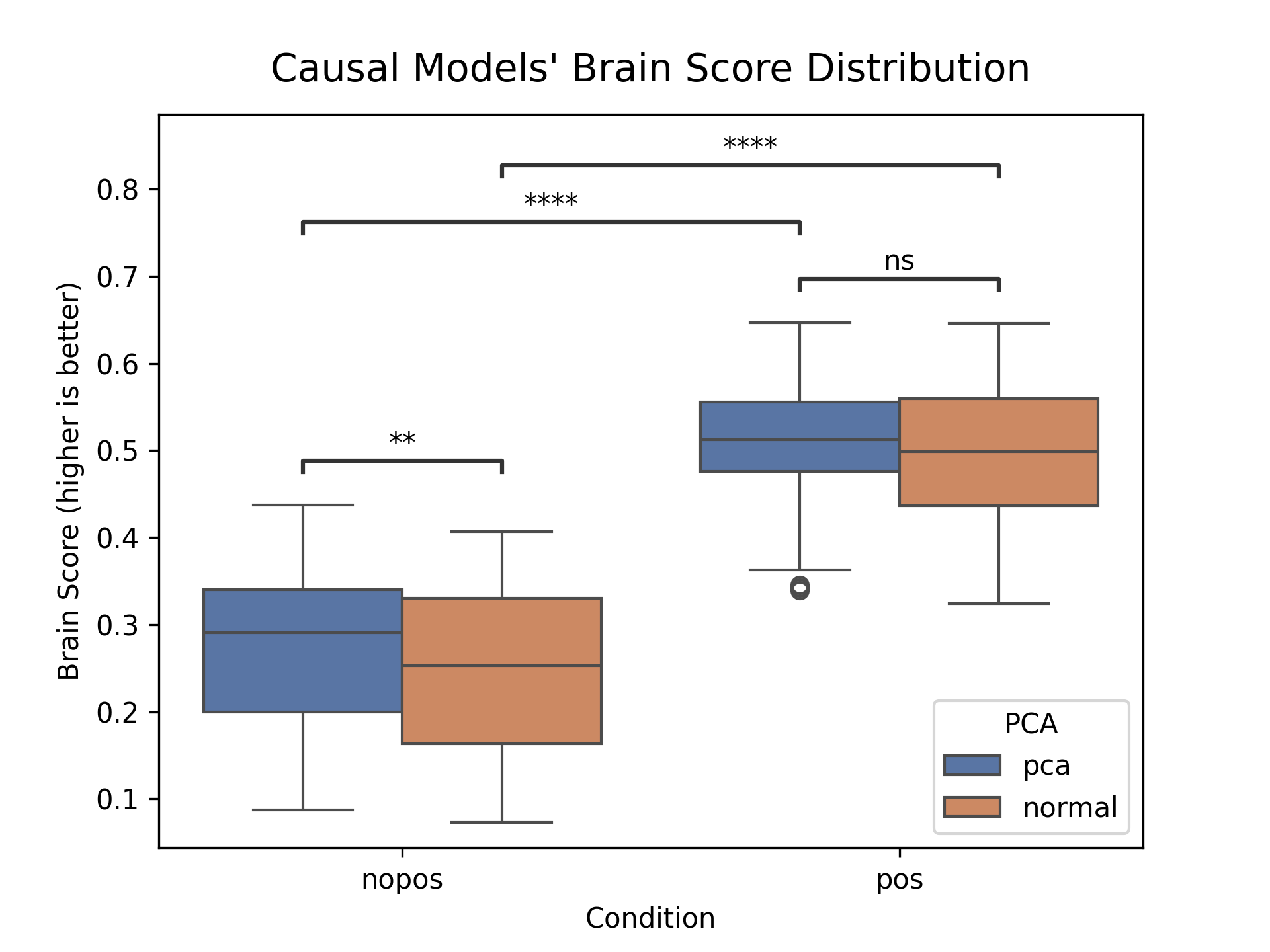
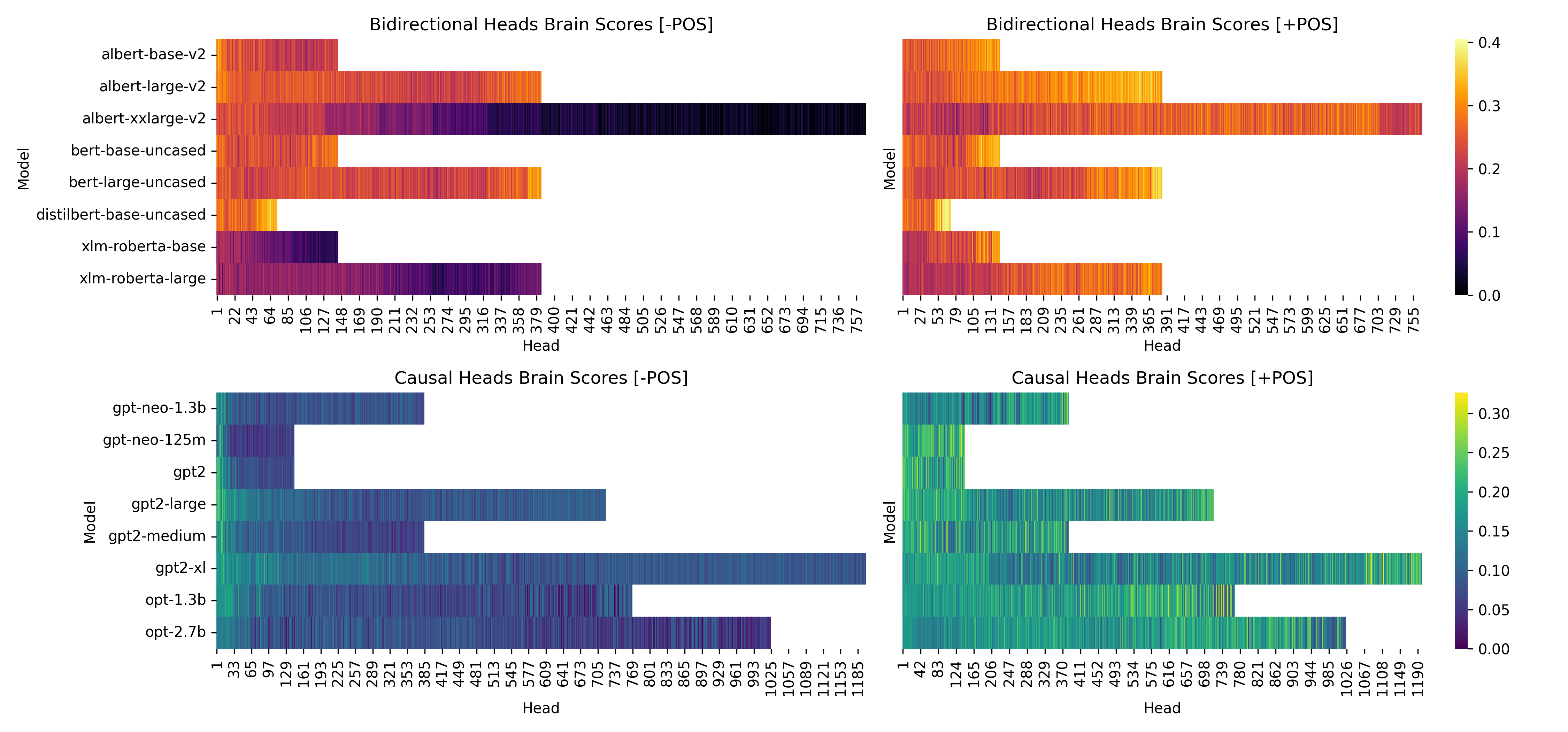
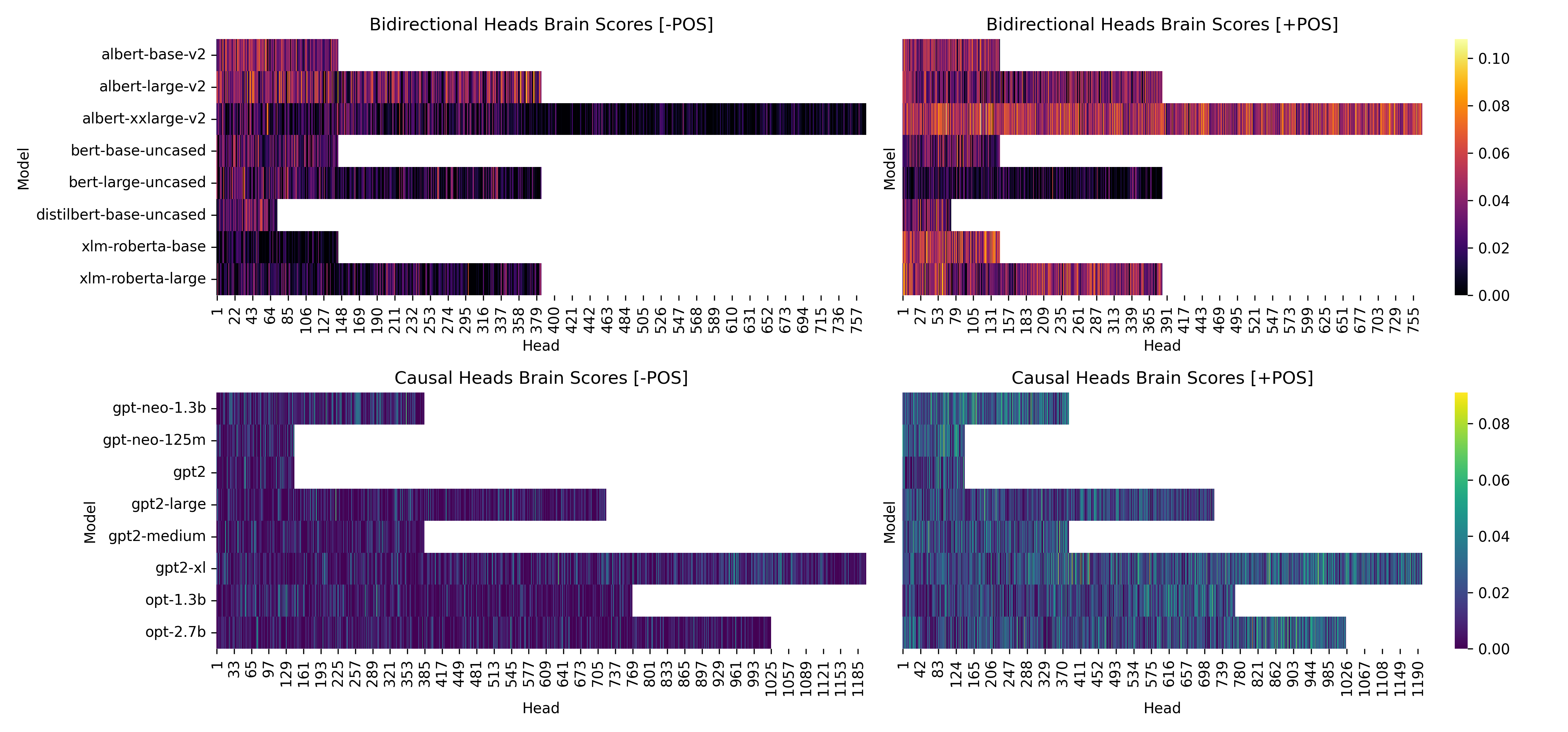
- Word order is crucial: When they removed positional encoding (the model’s sense of word order), the match between AI and brain dropped a lot—by as much as 0.4 in correlation strength. With word order turned on, matches were much stronger. This tells us human-like language understanding depends on knowing the sequence of words, not just which words are present.
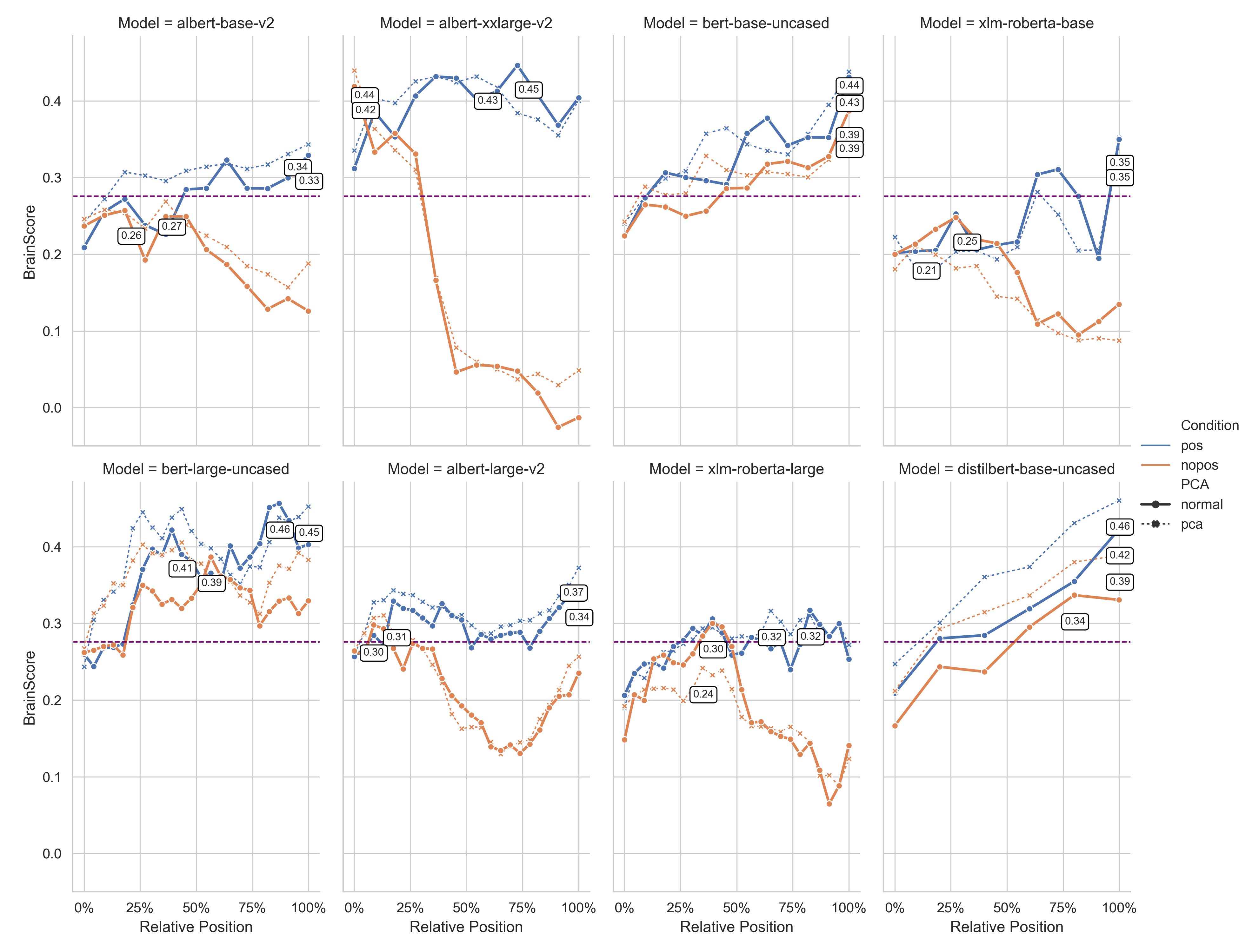
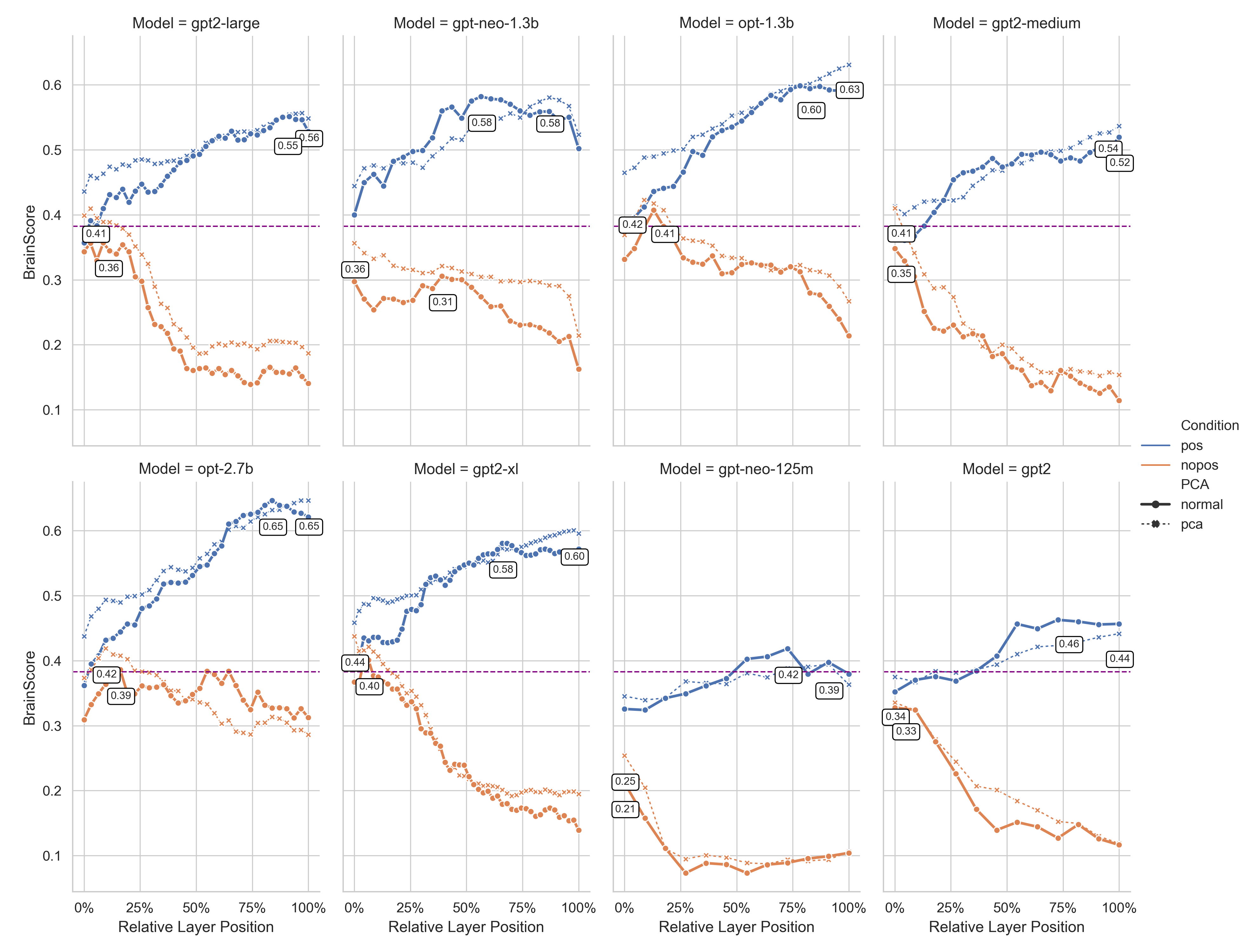
- Causal models match better: Models that read left-to-right (like GPT) matched brain activity best, especially in deeper layers. That makes sense: humans process sentences in order, so models trained this way seem more brain-like.
- Not a big-data trick: Even after compressing brain data massively using PCA, the core patterns stayed. So the similarities aren’t just happening because both datasets are huge.
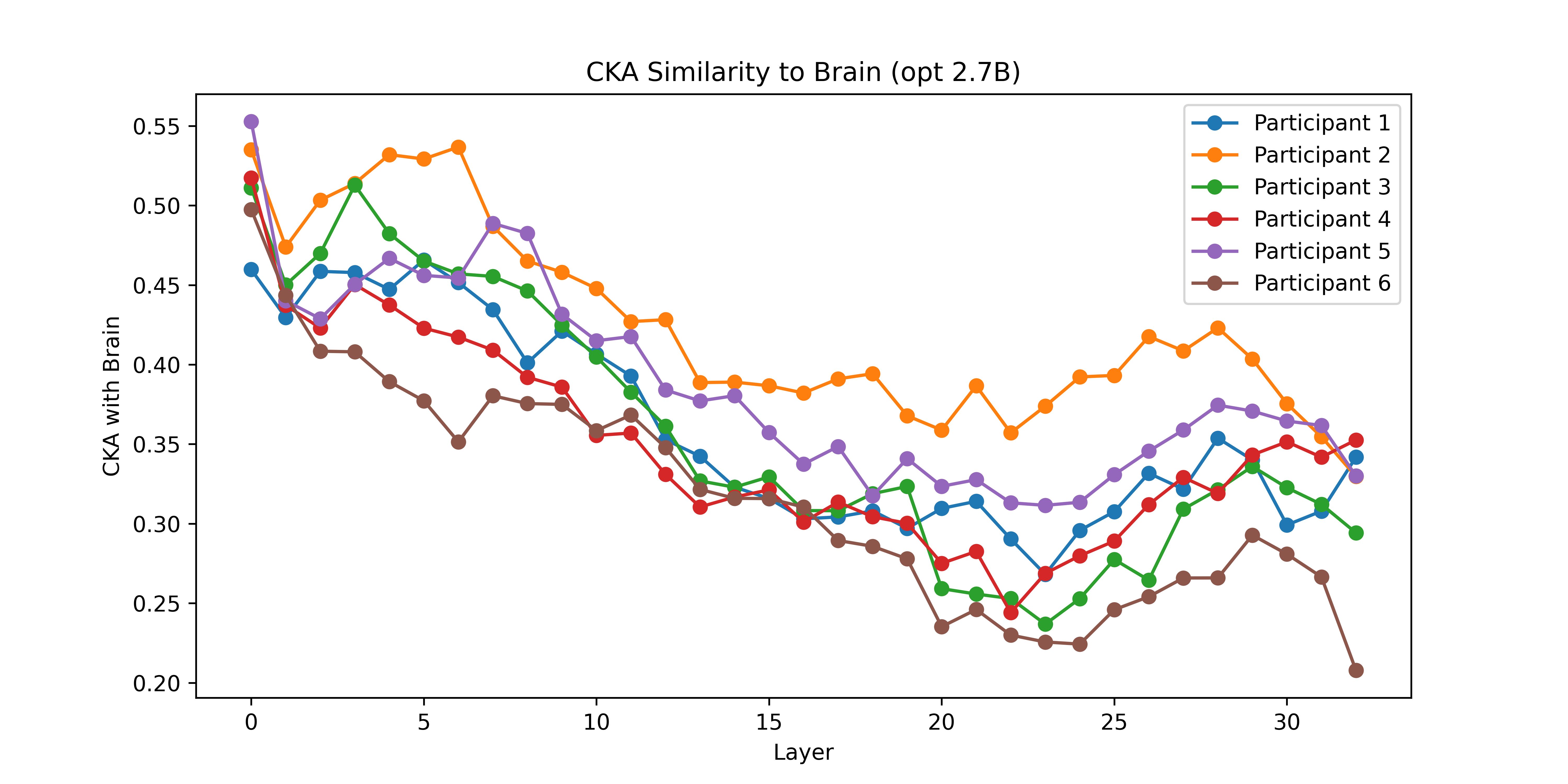
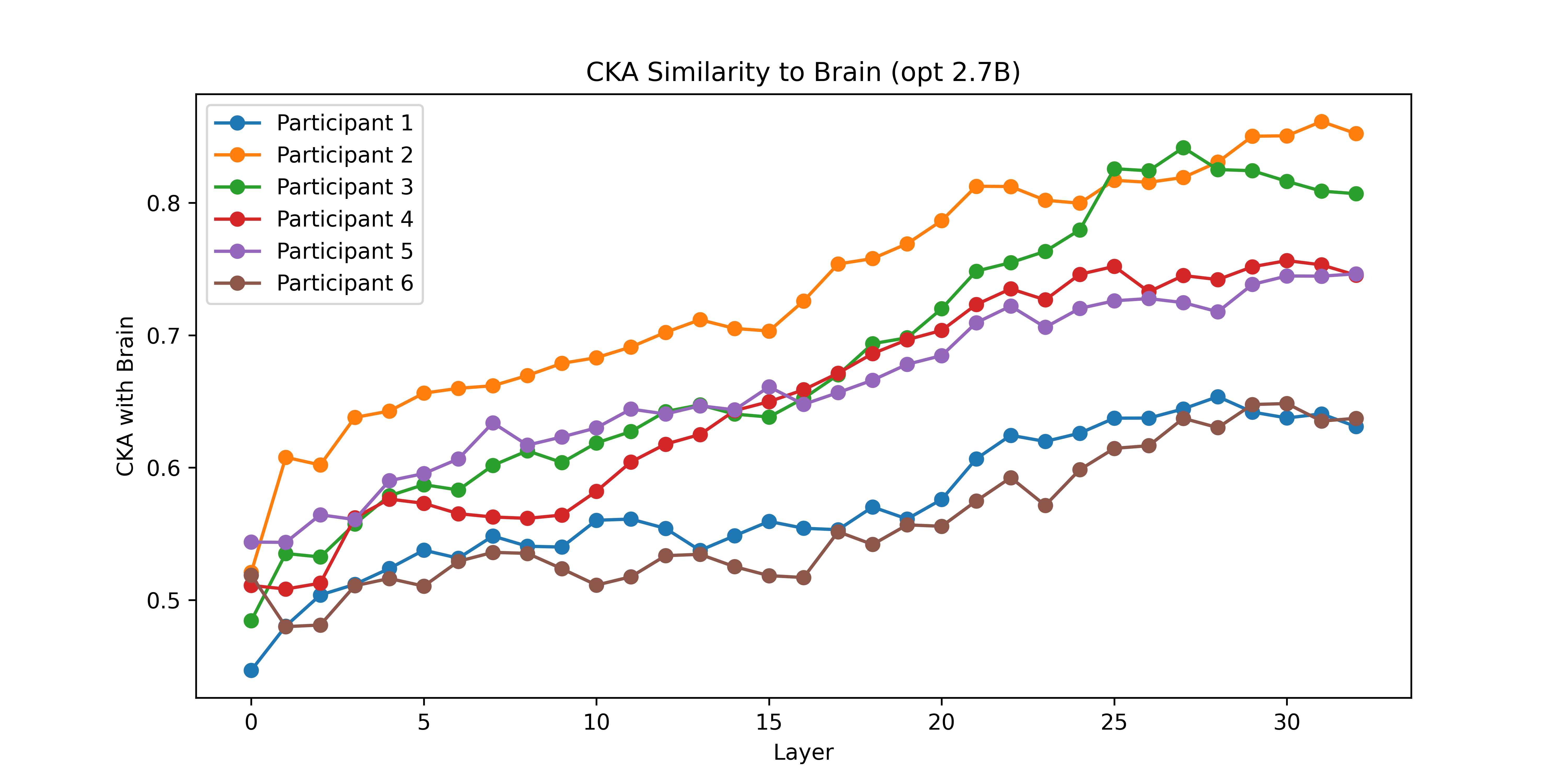
- Stronger with better layers: In most models, deeper layers (later steps in processing) matched brain activity more closely. This suggests that as language gets processed into richer meaning, the patterns become more similar to the brain’s.
- Attention details: Certain internal parts of the models—called attention heads—showed some alignment with brain activity, especially when word order was available. Raw attention weights alone were only weakly helpful; the actual processed signals mattered more.
- Only language training works: Models trained on protein data (not human sentences) didn’t match the brain at all. Their scores were tiny compared to language-trained models. This strongly suggests that seeing real human language during training is necessary to pick up brain-like patterns.
What’s the impact?
This research supports the idea that modern AI LLMs aren’t just good at language tasks—they build internal representations that echo how human brains process sentences, especially when:
- They read left-to-right, like humans.
- They use word order information.
- They’re trained on real human language, not just any sequence data.
Why this matters:
- Better brain-inspired AI: Understanding which model features make AI more brain-like can help us design smarter, more natural language systems.
- Insights into the brain: If certain AI layers align well with specific brain regions, scientists can use models to form new hypotheses about how the brain organizes language.
- Reliable comparisons: By ruling out “big data” artifacts and confirming results with multiple similarity measures (CKA and GW), the study strengthens confidence in the AI–brain connection.
- Clear boundary: The language-specific finding sets an important limit—just having the right architecture isn’t enough; the model must learn from human language to mirror human brain patterns.
In short, this paper shows that the brain-like behavior of AI LLMs is real, depends on word order and training on human language, and becomes stronger in deeper processing—bringing us a step closer to understanding both artificial and biological language systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and questions unresolved, which future research could address:
- Sample size and dataset breadth: Only 6 participants and one fMRI dataset (reading sentences) were used; it remains unclear whether findings generalize across larger, more diverse cohorts, tasks (listening, production), and datasets with different acquisition parameters.
- ROI definition choices: Language ROIs were selected via AAL anatomical parcellation rather than individual functional localizers; the impact of ROI selection strategy on alignment and the benefits of subject-specific fROIs or whole-brain analyses are not quantified.
- Lateralization and region specificity: No systematic analysis of hemispheric asymmetries or region-specific effects (e.g., IFG vs STG vs TP vs MFG), leaving open whether alignment varies in expected ways across the language network.
- Voxel selection sensitivity: Using the top 10% most reliable voxels may bias results; robustness to varying reliability thresholds and alternative voxel/parcel selection methods has not been tested.
- Temporal resolution and alignment: fMRI’s slow hemodynamics and sentence-level presentation obscure token-level dynamics; whether alignment persists with high-temporal-resolution modalities (MEG/ECoG) and careful HRF modeling remains unknown.
- Sentence-level aggregation choices: Bidirectional models used [CLS] embeddings; causal models used mean-pooled token embeddings. The sensitivity of brain scores to alternative sentence summarization strategies (e.g., final-token, attention pooling, learned pooling) is untested.
- Model-side dimensionality reduction: PCA was applied only to fMRI data; whether reducing LM activations (e.g., PCA/CCA/PLS on model states) changes alignment or mitigates curse-of-dimensionality effects is unexplored.
- PCA hyperparameters: The choice of 50 components (≈75–80% variance) is arbitrary; systematic sweeps of component counts and variance retention thresholds are needed to characterize dimensionality effects.
- Mapping function expressivity: Ridge regression was the sole mapping; it is unknown if nonlinear mappings (kernel ridge, Gaussian processes, shallow neural nets), regularization variants, or multi-voxel/ROI multivariate models improve or alter alignment patterns.
- Noise ceiling estimation: A single global ceiling (0.32) was used; per-subject, per-ROI, and per-voxel ceilings—and their uncertainty—should be estimated to better contextualize reported brain scores.
- Positional encoding ablation method: “Zeroing positional encodings” at inference likely induces distribution shift; the causal role of positional information should be tested with models retrained without positions, with different positional schemes (absolute, relative, RoPE), and matched ablations across architectures.
- Positional encoding diversity: The type of positional encoding in each model (learned absolute, sinusoidal, rotary, relative) is not analyzed; whether alignment depends differentially on encoding type and implementation remains unclear.
- Attention interpretability: Head-wise analyses are correlational; causal tests (head ablations, reweighting, pruning, value-vector vs weight isolation, attention steering) are needed to identify which heads/mechanisms drive brain alignment.
- Attention weight proxies: Raw attention weights are known to be imperfect indicators of information flow; testing alternative proxies (e.g., attention rollout, integrated gradients, attribution to value vectors) could clarify the marginal relevance result.
- Layer-to-region correspondences: Layer-wise trajectories were reported but not mapped onto specific cortical regions; a fine-grained layer–ROI mapping could reveal hierarchical correspondences and processing gradients.
- Alignment metrics generality: CKA and GW were computed primarily for a single “best” causal model (opt-2.7b); whether geometric/topological findings generalize across architectures, sizes, and training regimes remains untested.
- Metric parameter sensitivity: CKA and GW depend on kernel choices, cost functions, and preprocessing (PCA, z-scoring); sensitivity analyses and statistical significance tests for these metric traces are missing.
- Control corpora breadth: Language specificity was tested only with protein-trained models (MLM objective); controls using other non-linguistic sequential corpora (music, code, synthetic/shuffled text, Zipf-matched noise) and causal objectives are needed to strengthen specificity claims.
- Task matching across modalities: The paper recommends modality-matched datasets but does not implement them; controlled comparisons (e.g., spoken language with audio models, visual captioning with VLMs) are necessary to disentangle task vs representational effects.
- Stimulus design: Sentences were simple and short; effects of syntactic complexity, ambiguity, discourse context, working-memory load, and prosody are not tested, limiting conclusions about which linguistic features drive alignment.
- Tokenization and preprocessing confounds: The mapping from stimuli to LM tokens (subword segmentation, casing, punctuation) and low-level visual confounds (word length, orthographic features) were not controlled; additive controls or nuisance regressors could clarify semantic vs form contributions.
- Training regime comparisons: The study contrasts MLM vs NWP but does not test instruction tuning, multilingual training, curriculum learning, or alignment-specific objectives, leaving open how training regimes modulate neural predictivity.
- Model breadth and scale: Only 19 models are included; alignment scaling with parameters, depth, and data size across broader families (e.g., LLaMA, GPT-3/4-class, Transformer-XL/T5/UL2) is not systematically characterized.
- Reproducibility and code transparency: Implementation details (exact ablations, preprocessing pipelines, hyperparameter grids, random seeds) and code availability are not provided; without them, replication and sensitivity checks are difficult.
- Statistical testing details: Multiple-comparison corrections are mentioned (Bonferroni), but the exact family of tests, number of comparisons, and permutation-based validations are not reported; more rigorous statistical auditing would bolster confidence.
- Cross-subject variability: While individual traces are shown, structured analyses of inter-individual variability, alignment clustering across subjects, and the role of anatomical differences are not pursued.
- Beyond correlations: The study focuses on encoding/representational alignment; causal tests (e.g., representational causal modeling, lesion/pipeline perturbations) and predictive generalization across unseen tasks/conditions are needed to move beyond correlational evidence.
Practical Applications
Overview
This paper demonstrates that internal representations of transformer LLMs align with human brain activity during language processing, and that this alignment is (a) robust to dimensionality reduction, (b) confirmed by complementary similarity measures (unbiased CKA and Gromov–Wasserstein distance), (c) specific to models trained on human language, and (d) critically dependent on positional encodings—especially in causal, next-word-prediction models. Below are practical applications that follow from these findings.
Immediate Applications
- NeuroAI evaluation and diagnostics for model developers
- Sector: software/AI research
- What: A “Neuroalignment Evaluation Suite” that adds brain-alignment checks to model evaluation pipelines, including noise-ceiling–normalized brain scores (via ridge encoding), unbiased CKA curves, GW distance profiles, and a positional-encoding ablation test.
- Tools/workflows: Python library or MLOps plugin for PyTorch/TF; standard reports of layer-wise alignment; automated PCA robustness checks; head-level diagnostics focusing on scaled dot-product outputs rather than raw attention weights.
- Assumptions/dependencies: Access to normative fMRI datasets; licensing for neuroimaging data; compute to run multi-model, multi-layer analyses; current evidence is for reading tasks and may not generalize to all modalities or populations.
- Experimental design optimization in cognitive neuroscience labs
- Sector: academia/neuroscience
- What: Use causal LMs with positional encodings and deeper layers for stronger brain predictivity; adopt PCA to reduce dimensionality without losing core effects; standardize ROI selection (e.g., AAL parcellation) and reliability-based voxel selection; prefer scaled dot-product head outputs over attention weights when probing interpretability.
- Tools/workflows: Turnkey pipeline mirroring the paper (5-fold ridge, noise ceiling normalization, PCA, CKA, GW); layer/head selection strategies informed by alignment curves.
- Assumptions/dependencies: Dataset scale (243 sentences) and fMRI temporal limits; requires replication with larger, diverse cohorts and tasks (e.g., listening).
- Attention-mechanism–aware interpretability dashboards
- Sector: software/AI interpretability
- What: Dashboards that surface which heads/layers (via scaled dot-product activations) best align with brain data, avoiding overreliance on attention weights that showed marginal relevance.
- Tools/products: Developer-facing visualization of layer/head trajectories, highlighting positional-encoding dependencies and depth-wise alignment trends.
- Assumptions/dependencies: Brain alignment is correlational, not causal; interpretability value depends on task/context.
- Readability and comprehension scoring informed by neuroalignment proxies
- Sector: education/edtech; UX/content design
- What: Content evaluation tools that approximate cognitive load and comprehension by leveraging LM layer-wise features that align with brain activity (e.g., depth-wise trajectories, positional sensitivity).
- Tools/products: LMS plugin or editorial QA tool indicating predicted processing difficulty; recommendations to adjust sentence structure and sequence clarity.
- Assumptions/dependencies: Generalization from lab reading stimuli to broader content; requires calibration and validation against behavioral metrics; privacy-friendly deployment.
- Methodological standards and reviewer checklists
- Sector: policy/academic governance
- What: Immediate guidance for journals and conferences to require reporting of positional encoding status, PCA controls, and complementary similarity metrics (CKA/GW) when claiming brain–model alignment; discourage extrapolation from non-linguistic training data (e.g., protein models).
- Tools/workflows: Review checklists; standardized reporting templates.
- Assumptions/dependencies: Community adoption; coordination among editors, reviewers, and funders.
- Rapid prototyping of language decoders in BCI research settings
- Sector: healthcare research/BCI
- What: Use causal LMs with positional encodings as encoding/decoding backbones for MEG/ECoG studies, guided by CKA/GW to select layers with stronger alignment.
- Tools/workflows: Integration with neuroimaging toolkits (e.g., MNE); layer selection by alignment curves; PCA preprocessing for robustness.
- Assumptions/dependencies: Transfer from fMRI findings to higher-temporal-resolution modalities; non-clinical research stage; ethical approvals and data security.
Long-Term Applications
- Clinical neuromarkers of language network integrity
- Sector: healthcare
- What: Brain–LM alignment profiles as biomarkers for diagnosing and tracking aphasia, dyslexia, TBI, and neurodegenerative language disorders; alignment changes as therapy response indicators.
- Tools/products: Clinical software that compares patient-specific fMRI/MEG/ECoG to LM layers and positional sensitivity; longitudinal monitoring dashboards.
- Assumptions/dependencies: Large-scale clinical validation; modality-specific protocols; standardized stimuli; regulatory approval; equitable access.
- Personalized neuroadaptive education
- Sector: education/edtech
- What: Adaptive reading platforms that tailor text complexity and sequence structure using LM features predictive of brain processing; potential real-time adjustments via EEG or eye-tracking.
- Tools/products: Neuroadaptive e-readers and language learning apps; teacher dashboards for individualized scaffolding.
- Assumptions/dependencies: Reliable, privacy-preserving sensing; validated mapping from LM features to comprehension for diverse learners; robust fairness controls.
- Bio-aligned LLM design and training objectives
- Sector: software/AI
- What: Use neuroalignment metrics (brain score, CKA, GW) as auxiliary training targets or evaluation gates; iterate positional encoding schemes and depth to improve human-like processing and interpretability.
- Tools/products: “Neuroaligned” pretraining recipes; layer/head pruning based on alignment; bio-plausibility badges for models.
- Assumptions/dependencies: Avoid overfitting to specific datasets; verify benefits for downstream tasks and human–AI interaction; compute demands and reproducibility.
- Regulatory frameworks for NeuroAI claims
- Sector: policy/regulation
- What: Standards for substantiating “human-like” processing claims (require language-trained models, positional encoding disclosure, multi-metric alignment evidence); privacy and data governance rules for neurodata use in AI.
- Tools/workflows: Certification schemes; audit guidelines; compliance checklists.
- Assumptions/dependencies: Interagency coordination; international harmonization; public trust and ethical safeguards.
- Language rehabilitation tools with LM-guided neurofeedback
- Sector: healthcare
- What: Therapy systems that set LM-derived targets for sequence processing (positional cues, depth-wise structure) and provide neurofeedback as patients practice comprehension and production.
- Tools/products: Clinic-grade rehabilitation software; BCI-assisted protocols.
- Assumptions/dependencies: Clinical efficacy trials; device integration; accessibility; therapist training.
- Real-time neuroadaptive UIs and content moderation
- Sector: UX/software; media platforms
- What: Interfaces that adjust presentation order, pacing, and structure based on predicted cognitive load from LM features; content moderation tools that flag likely miscomprehension zones (e.g., complex sequencing).
- Tools/products: UI SDKs; editor assist tools; accessibility enhancements.
- Assumptions/dependencies: Reliable proxies for brain responses; user consent and privacy; bias/fairness controls.
- Cross-modal and multilingual neuroalignment expansion
- Sector: academia; industry
- What: Extend alignment studies to spoken language (audio LMs), sign language, and diverse languages to build modality-matched NeuroAI tools and global benchmarks.
- Tools/workflows: Multimodal datasets; audio- and sign-specific positional schemes; cross-cultural validation.
- Assumptions/dependencies: New datasets and stimuli; standardized evaluation; funding and collaboration.
- Efficiency and distillation guided by neuroalignment
- Sector: software/AI
- What: Prune or distill models by retaining layers/heads with highest brain alignment, targeting efficient models that preserve human-like processing signatures.
- Tools/products: Distillation toolchains; inference-efficient “neuro-preserving” models.
- Assumptions/dependencies: Task performance trade-offs; alignment–utility relationship; robust validation across tasks.
Each application depends on the core findings: alignment is language-specific, robust to dimensionality reduction, strengthened by positional encoding (especially in causal LMs), and supported by complementary similarity measures (CKA, GW). Feasibility varies with access to neurodata, validation across modalities and populations, ethical considerations, and the maturity of cross-disciplinary standards.
Glossary
- Ablation: removal of a component to test its impact on performance or behavior. "a significant drop in performance would be expected from the ablation of positional (structural) information."
- AAL parcellation atlas: an anatomical brain atlas used to label regions in neuroimaging analyses. "we first selected the language regions-of-interest (ROIs) using the AAL parcellation atlas \cite{tzourio-mazoyer}."
- Angular gyrus (AG): a cortical region implicated in language and semantic processing. "Additionally, We included the right hemisphere counterparts of the IFG, STG, and angular gyrus (AG)."
- Attention weights: the coefficients from the attention mechanism indicating how much each token attends to others. "Head-wise (attention weights only) brain scores for bidirectional (top) and causal (bottom) models."
- Bidirectional models: transformer encoders that attend to both left and right context. "Bidirectional models are optimized for masked-language modeling (MLM): roughly 25\% of the input tokens are replaced with a [MASK] token and the model learns to predict the masked items from full left- and right-context."
- Bonferroni correction: a statistical method to adjust significance thresholds for multiple comparisons. "Multiple comparisons corrected with Bonferroni correction."
- BOLD signals: fMRI measurements reflecting blood-oxygen-level dependent changes in brain activity. "For each subject, the dataset provides 243 BOLD signals represented as 200,000-dimensional vectors."
- Brain score: a normalized correlation metric quantifying model-brain alignment. "The brain score was obtained by normalizing the correlation metric by the estimated noise ceiling (0.32)\footnote{The ceiling was validated through a leave-one-out noise estimation.}."
- Causal mask: a constraint in self-attention limiting tokens to attend only to earlier positions. "A causal mask in the self-attention mechanism restricts each token to attend only to earlier positions in the sequence, enforcing left-to-right processing \cite{vaswani2017attention}."
- Causal models: decoder-only transformers trained for next-token prediction using left-to-right context. "Causal models are trained for next-word prediction (NWP)."
- Centered Kernel Alignment (CKA): a similarity measure comparing representational structures across datasets or layers. "Beyond standard correlationâbased scores, we compute unbiased centeredâkernel alignment (CKA) and Gromov-Wasserstein (GW) distances, providing complementary geometric views of representational similarity."
- CLS token: a special token in bidirectional models representing aggregate sequence information. "During inference on the fMRI text stimuli, We recorded layer-wise activations of the special [CLS] token and retained attention matrices and head-wise outputs for further analysis."
- Curse of dimensionality (CoD): phenomena where high-dimensional spaces hinder statistical learning and similarity measures. "To analyze the potential impact of the curse of dimensionality (CoD) on the correlation-based brain scores, we recomputed the brain scores for [+pos] and [-pos] conditions with PCA-reduced fMRI data."
- Decoder-only models: transformer architectures composed solely of decoder blocks, typically used for generation. "Decoder-only models, lacking future context, remained strongly dependent on explicit positional cues, which resulted into a wider performance gap."
- Electrocorticography (ECoG): invasive brain recording technique using electrodes placed on the cortical surface. "Integrative predictiveâprocessing models have shown that nextâword prediction objectives yield representations that align closely with ECoG and fMRI data in languageâselective regions \citep{schrimpfNeuralArchitectureLanguage2021a, goldsteinSharedComputationalPrinciples2022a}."
- Fisher’s method: a technique to combine independent p-values into a single test statistic. "and combined voxel -values within each fold via Fisherâs method."
- fMRI (functional Magnetic Resonance Imaging): a neuroimaging method measuring brain activity via blood flow changes. "Prior work has demonstrated voxelâwise correlations (``brain scores'') between LM hidden states and fMRI responses during reading comprehension \citep{schrimpfNeuralArchitectureLanguage2021a, goldsteinSharedComputationalPrinciples2022a}."
- Gromov-Wasserstein (GW) distance: an optimal transport-based metric comparing relational structures across spaces. "we compute unbiased centeredâkernel alignment (CKA) and Gromov-Wasserstein (GW) distances, providing complementary geometric views of representational similarity."
- Independent localizer task: a separate scanning protocol used to identify functional regions in neuroimaging. "which used an ``independent localizer task'' \cite[p. 3]{schrimpfNeuralArchitectureLanguage2021a}."
- Masked-language modeling (MLM): a pretraining objective where masked tokens are predicted from context. "Bidirectional models are optimized for masked-language modeling (MLM): roughly 25\% of the input tokens are replaced with a [MASK] token and the model learns to predict the masked items from full left- and right-context."
- Mean-pooling: aggregation by averaging embeddings across tokens to form a sequence representation. "Since causal models lack a [CLS] token, We derived sentence-level representations by mean-pooling the token embeddings at each layer."
- Noise ceiling: the estimated upper bound on achievable prediction accuracy given data noise. "The brain score was obtained by normalizing the correlation metric by the estimated noise ceiling (0.32)\footnote{The ceiling was validated through a leave-one-out noise estimation.}."
- Next-word prediction (NWP): a training objective to predict the subsequent token given prior context. "Causal models are trained for next-word prediction (NWP)."
- Optimal Transport (OT): a mathematical framework for matching probability distributions with minimal cost. "GW distance generalizes the optimal transport (OT) by seeking a soft-matching between two sets of points and that minimizes the discrepancy between the within-space pairwise distances (Equation \ref{eq:gw-loss})."
- PCA (Principal Component Analysis): a dimensionality reduction technique projecting data onto principal variance directions. "To analyze the potential impact of the curse of dimensionality (CoD) on the correlation-based brain scores, we recomputed the brain scores for [+pos] and [-pos] conditions with PCA-reduced fMRI data."
- Positional encodings: vectors injected into token representations to encode order information in transformers. "For both model classes we repeated the extraction procedure after zeroing the positional encodings."
- Regions of Interest (ROIs): selected brain areas for focused analysis in neuroimaging. "During preprocessing, we first selected the language regions-of-interest (ROIs) using the AAL parcellation atlas \cite{tzourio-mazoyer}."
- Representational Dissimilarity Matrix (RDMs): a matrix capturing pairwise dissimilarities among stimuli representations. "RDMs are matrices representing the correlational cost between each pair of stimuli ."
- Representational Stability Analysis (ReStA): a method assessing robustness and consistency of model representations across layers. "\cite{abnarBlackboxMeetsBlackbox2019} introduced Representational Stability Analysis (ReStA) to probe layerâwise robustness in transformer LMs and compared those representations to fMRI activations during story reading."
- Representational Similarity Analysis (RSA): a framework comparing representational structures across models and brain data via RDMs. "\citep{caucheteuxBrainsAlgorithmsPartially2022} and \citep{gauthierLinkingArtificialHuman2019} applied RSA and decoding frameworks to fMRI and MEG measurements, revealing where and when sentenceâlevel representations emerge in the brain."
- Ridge regression: a linear regression with L2 regularization used to predict neural responses from model features. "Using 5-fold (i.e., five 80/20 splits) cross-validation, we fit a Ridge regression (; best across folds obtained via grid search) on the training fold and predicted the held-out fold."
- Scaled dot-product attention: the core attention mechanism computing weighted similarity between queries and keys. "we analyzed the scaled dot-product attention heads' brain scores."
- Split-half reliability selection: a procedure selecting voxels based on consistency across split halves of data. "For voxel selection, we performed split-half reliability selection \cite{tarhanReliabilitybasedVoxelSelection2020} and considered the top 10\% most reliable voxels for analysis."
- Superior Temporal Gyrus (STG): an auditory-language cortical region involved in speech perception. "We studied the inferior frontal gyrus (IFG), superior temporal gyrus (STG), temporal pole (TP), and middle frontal gyrus (MFG)."
- Temporal Pole (TP): a anterior temporal lobe region implicated in semantic processing. "We studied the inferior frontal gyrus (IFG), superior temporal gyrus (STG), temporal pole (TP), and middle frontal gyrus (MFG)."
- Voxel-wise: per-voxel analysis of brain imaging data. "Prior work has demonstrated voxelâwise correlations (``brain scores'') between LM hidden states and fMRI responses during reading comprehension \citep{schrimpfNeuralArchitectureLanguage2021a, goldsteinSharedComputationalPrinciples2022a}."
- Wilcoxon test: a non-parametric statistical test for comparing paired samples. "PCA increased brain alignment for [âpos] inputs (paired Wilcoxon, )\footnote{Multiple comparisons corrected with Bonferroni correction. Same criterion applies to all experiments.}"
Collections
Sign up for free to add this paper to one or more collections.