- The paper shows that superposition—where multiple features share dimensions—increases adversarial vulnerability in neural networks.
- It employs toy models and ResNet18 experiments to quantify how feature interference is reduced by adversarial training.
- The findings indicate that techniques like sparse autoencoders can lower reconstruction error and improve robustness by managing superposition.
Adversarial Examples Are Not Bugs, They Are Superposition
Introduction
The paper "Adversarial Examples Are Not Bugs, They Are Superposition" explores the relationship between superposition and adversarial examples in neural networks. Despite extensive research, adversarial examples—inputs with minor perturbations that deceive neural networks—remain a puzzle. The authors investigate the hypothesis that superposition, a concept from mechanistic interpretability, is a causal factor in producing adversarial examples. Superposition allows networks to represent more features than neurons through interference in high-dimensional spaces. The paper presents experiments with toy models and ResNet18 to support their hypothesis.
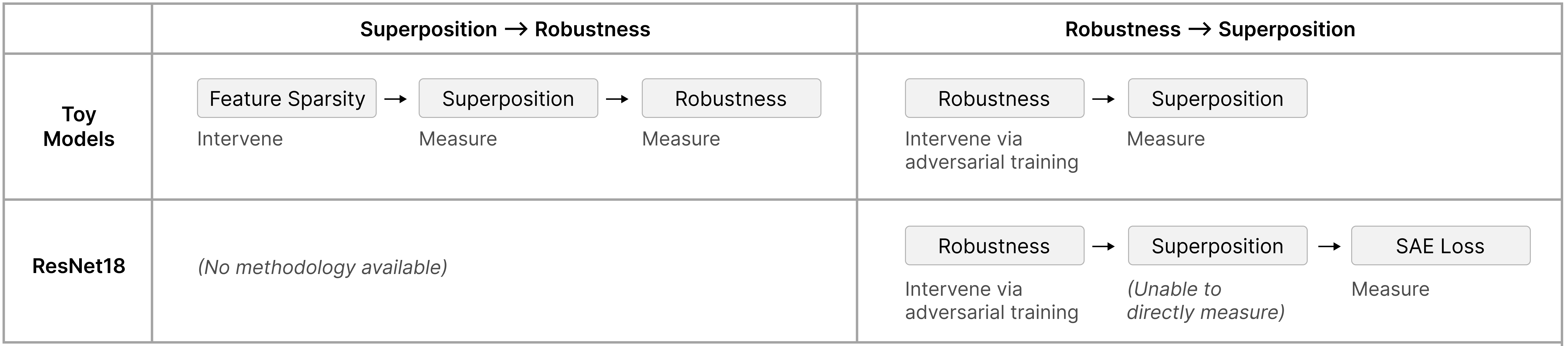
Figure 1: Overview of experiments. The three primary experiments test the relationship between superposition and robustness in different ways.
Superposition and Adversarial Vulnerability
Superposition enables models to encode more features than there are neurons, potentially leading to interference when features share dimensions. This interference can be exploited by adversarial attacks, which target multiple features in superposition. The authors demonstrate that superposition can cause adversarial vulnerability, as models become susceptible when superposed features interfere excessively.
Causal Evidence from Toy Models
Experiment Setup
In toy models, the authors vary feature sparsity and measure resulting superposition and robustness. The setup involves projecting features into fewer hidden dimensions and measuring adversarial vulnerability using L2-bounded attacks. Feature sparsity serves as a control variable to manipulate superposition levels.
Results
Adversarial vulnerability increases with superposition, as confirmed by the rise in features per dimension when sparsity is high (Figure 2). Adversarial training—training on both clean and adversarial examples—demonstrates a reduction in superposition, indicating bi-directional causality between robustness and superposition.
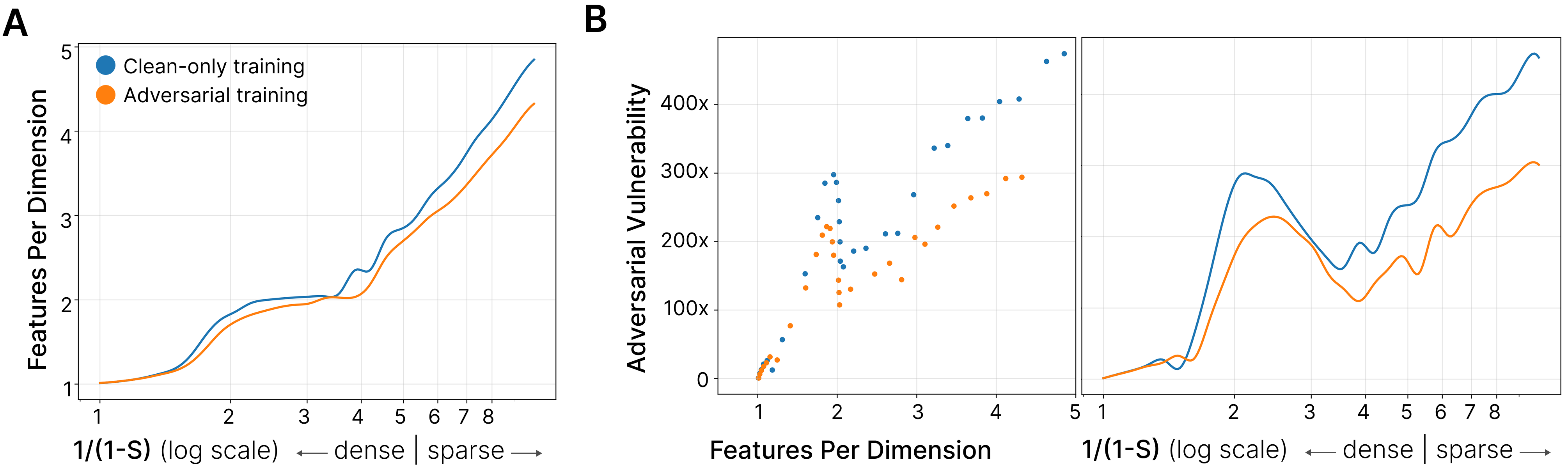
Figure 2: Adversarial training reduces superposition. Comparison of models before (blue) and after (orange) adversarial training. A: Features per dimension decreases for a given sparsity level. B: Models become more vulnerable to adversarial examples as superposition increases.
Superposition Impact in Real Models
Adversarial Training and Sparse Autoencoders
The authors analyze ResNet18 models with adversarial training, using sparse autoencoders (SAEs) to estimate superposition. SAEs model superposition, as more densely superposed features lead to higher reconstruction errors. Enhanced reconstruction abilities in robust models suggest a relation between reduced superposition and increased adversarial robustness (Figure 3).
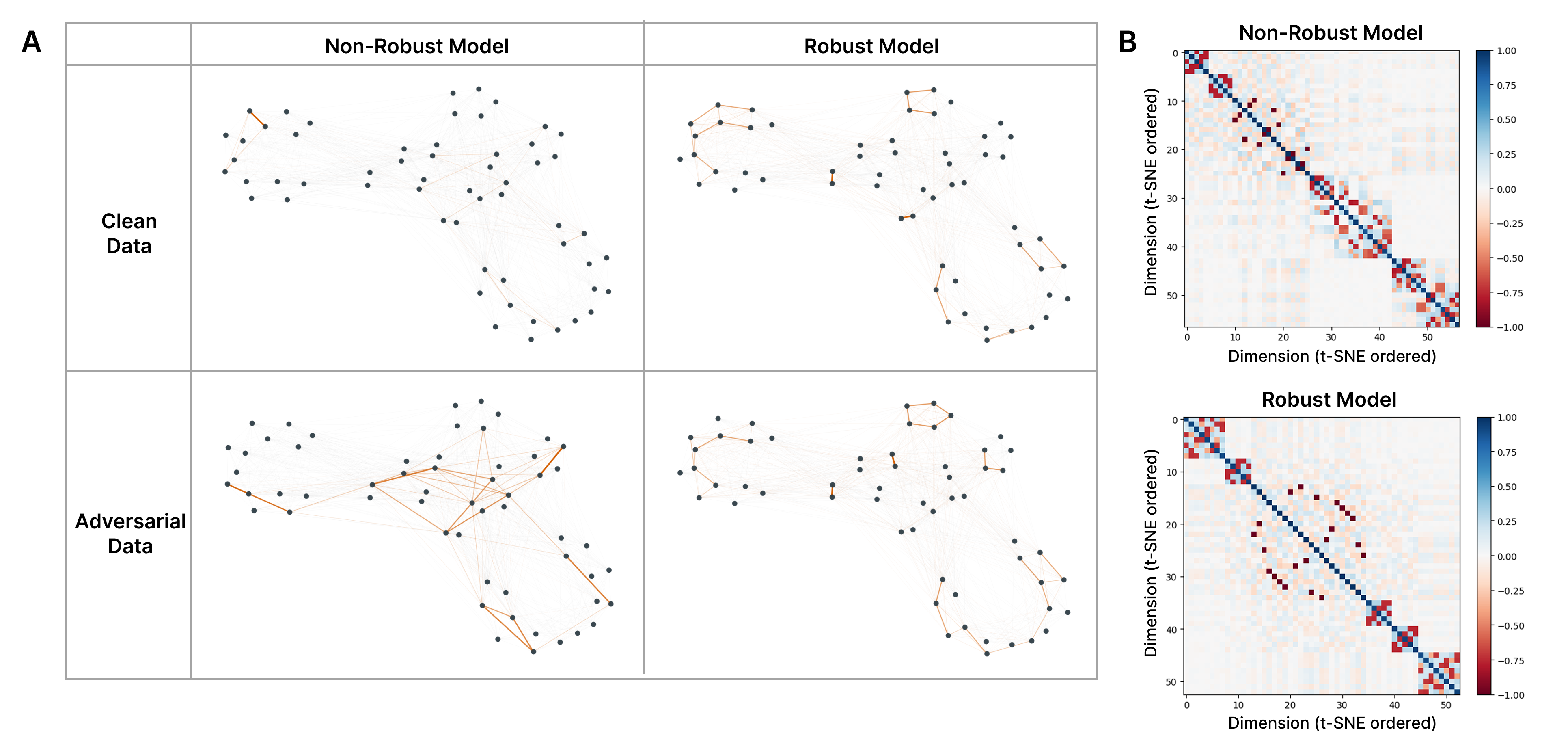
Figure 3: Robust models achieve better reconstruction at a given sparsity level. Lower MSE at fixed sparsity indicates less interference and thus less superposition.
Observations
Adversarial examples activate more features than clean inputs, indicating exploitation of superposition for interference-driven attacks. Graph models show that robust and non-robust configurations (Figure 4) present distinct feature interference patterns, reinforcing the notion of adversarial training reducing superposition.
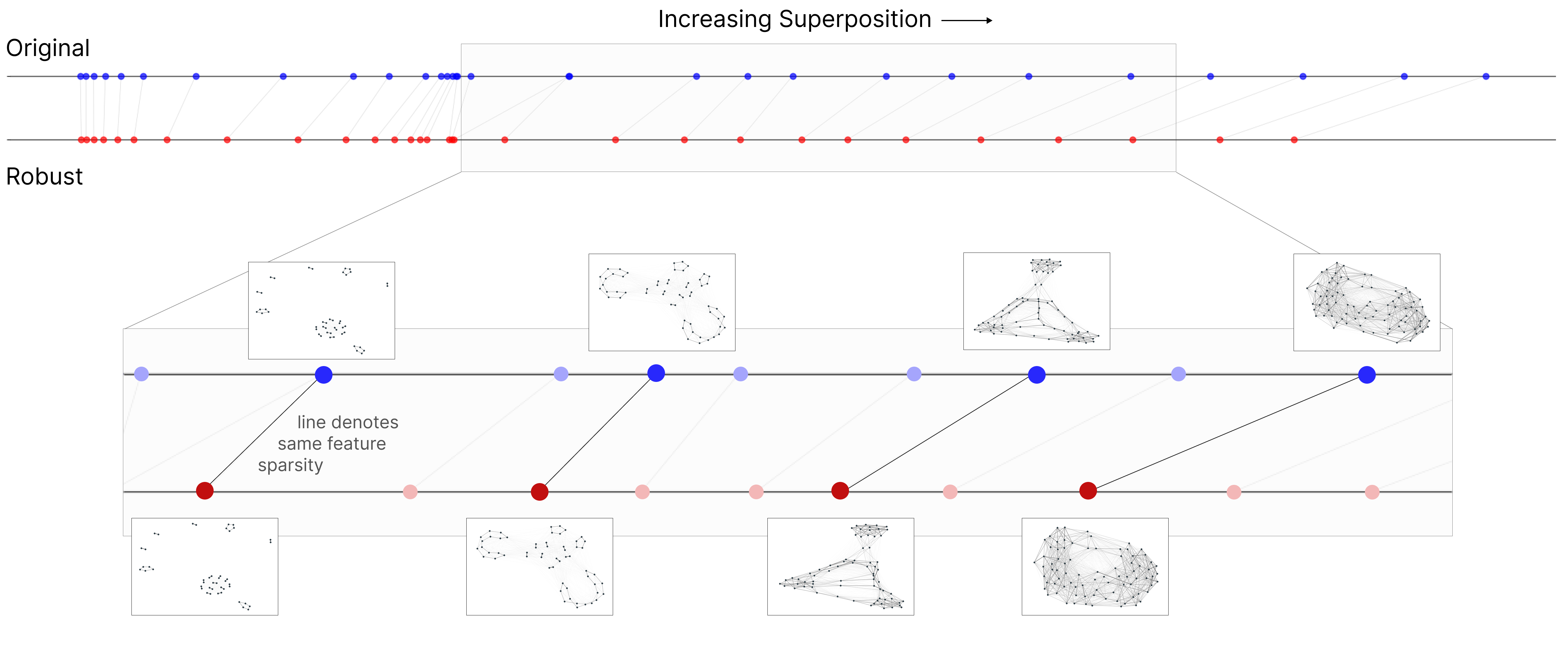
Figure 4: Adversarial attacks activate interfering features in superposition, showing patterns in model geometry.
Discussion
The paper posits superposition as a significant factor in adversarial vulnerability. While the evidence from toy models and ResNet18 is compelling, it hinges on proxy measurements for real models due to the inability to directly manipulate superposition. The paper invites further investigation into the interplay of superposition structures and robustness, alongside individual model geometries.
Potential advancements in measuring superposition and experimental techniques will bolster understanding of adversarial robustness mechanisms. Diminishing superposition may serve as a strategic avenue for improving model robustness while respecting computational constraints, with implications for interpretability and efficient model calculations.
Conclusion
The research highlights superposition's critical role in adversarial vulnerability, backed by evidence from controlled experiments in both simplified and realistic settings. Demonstrating causal links between superposition and resilience to adversarial attacks, the study invites further exploration. Superposition, while expanding model capacity, introduces vulnerabilities that adversarial training mitigates, forging a link between robustness and interpretability efforts in AI.

