- The paper introduces Neural Jump ODEs to estimate drift and diffusion from irregular, discrete data, enabling generation of sample paths that match the true process.
- It employs a predictive, non-adversarial training framework with bias correction, ensuring convergence and robustness even under missing data and path-dependence.
- Empirical evaluations on GBM and OU processes demonstrate the method's ability to replicate both marginal and pathwise distributions accurately.
Neural Jump ODEs as Generative Models: Theory and Practice
Overview
"Neural Jump ODEs as Generative Models" (2510.02757) presents a framework for learning the law of Itô processes from discrete, potentially irregular and incomplete observations, using Neural Jump ODEs (NJODEs). The approach enables the estimation of drift and diffusion coefficients directly from data, facilitating the generation of new sample paths that match the true underlying process in law. The method is non-adversarial, prediction-based, and robust to missing data and path-dependent dynamics, with theoretical guarantees of convergence under standard regularity assumptions.
The central problem is to learn the law of a d-dimensional Itô process X governed by the SDE:
dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,
where μt and σt are unknown, possibly path-dependent drift and diffusion coefficients, and Wt is an m-dimensional Brownian motion. The only available data are discrete, possibly irregular and incomplete, observations of independent sample paths of X.
The objective is to generate new, independent trajectories of X by learning estimators μ^t and X0 for the coefficients, such that the generated process X1 matches the law of X2 as closely as possible.
NJODE Framework for Coefficient Estimation
NJODEs are continuous-time models designed to optimally predict stochastic processes from discrete, irregular, and incomplete observations. The key insight is that, by training NJODEs to approximate conditional expectations of X3 and X4 given the available information, one can construct estimators for the drift and diffusion coefficients.
Drift Estimation
Given observations up to time X5, the drift is estimated via:
X6
where X7 is the X8-algebra generated by the available information up to X9. The NJODE is trained to predict dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,0.
Diffusion Estimation
The diffusion is estimated using the conditional expectation of squared increments:
dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,1
To ensure positive semi-definiteness, the NJODE is trained to output a matrix dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,2 and the estimator is taken as dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,3.
Instantaneous Estimation
To reduce bias from finite dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,4, the paper introduces direct estimation of instantaneous coefficients by training NJODEs to predict the quotient of increments (for drift) and squared increments (for diffusion), divided by the time step, and using right-limits at observation times.
Generative Procedure
Once the NJODEs are trained, the generative procedure is as follows:
- Initialization: Start from an initial observation or a sequence of observations (possibly with missing values).
- Iterative Generation: At each step, use the current history to compute dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,5 and dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,6 via the NJODEs, then sample the next point using the Euler-Maruyama scheme:
dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,7
- Continuation: Repeat until the desired time horizon is reached.
This procedure can generate unconditional sample paths or paths conditioned on arbitrary observed histories.
Theoretical Guarantees
The paper provides rigorous convergence results:
- Consistency: Under standard regularity and identifiability assumptions, as the NJODEs are trained to optimality and dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,8, the estimators dXt=μt(X⋅∧t)dt+σt(X⋅∧t)dWt,9 and μt0 converge in μt1 to the true coefficients (or their μt2-optimal projections given the available information).
- Law Convergence: The law of the generated process μt3 converges to the law of the true process μt4 as the estimators improve and the discretization is refined.
- Robustness: The approach is robust to irregular sampling, missing data, and path-dependent coefficients.
Empirical Evaluation
The framework is validated on synthetic datasets, including geometric Brownian motion (GBM) and Ornstein-Uhlenbeck (OU) processes. Four estimation strategies are compared: baseline, joint baseline with bias reduction, instantaneous, and joint instantaneous with bias reduction.
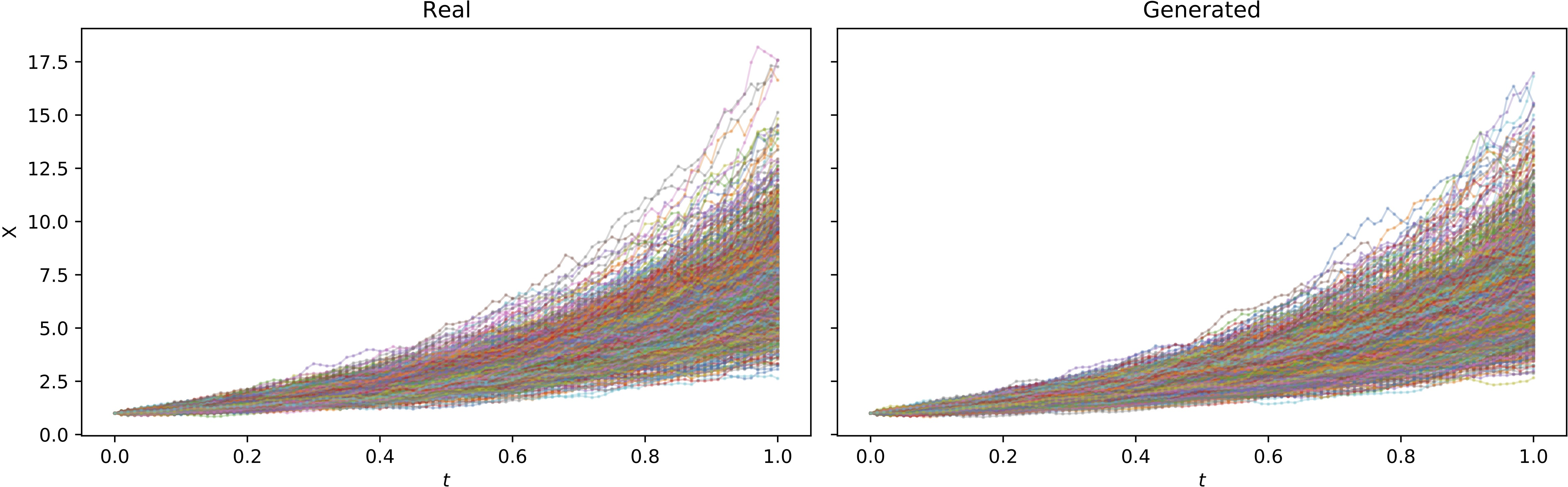
Figure 1: Plot of true training paths and generated (with joint instantaneous method) paths, with 1000 samples each.
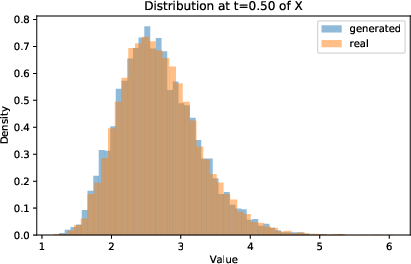
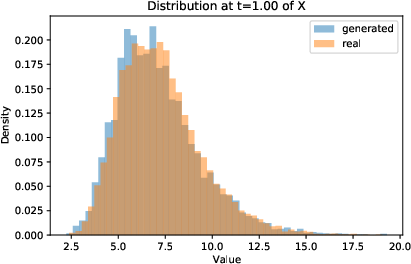
Figure 2: Distribution of μt5 at μt6 and μt7 of true training paths and generated (with joint instantaneous method) paths.
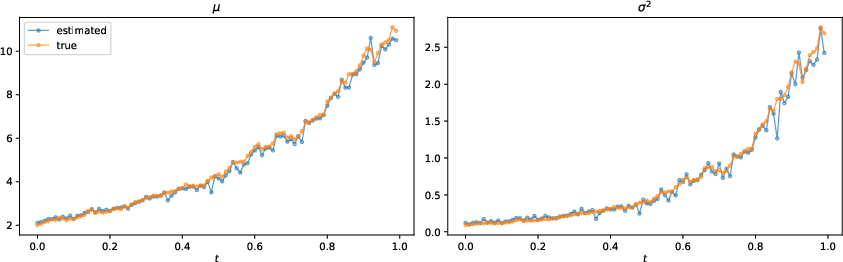
Figure 3: True and estimated (with joint instantaneous method) drift and diffusion coefficients along one generated path.
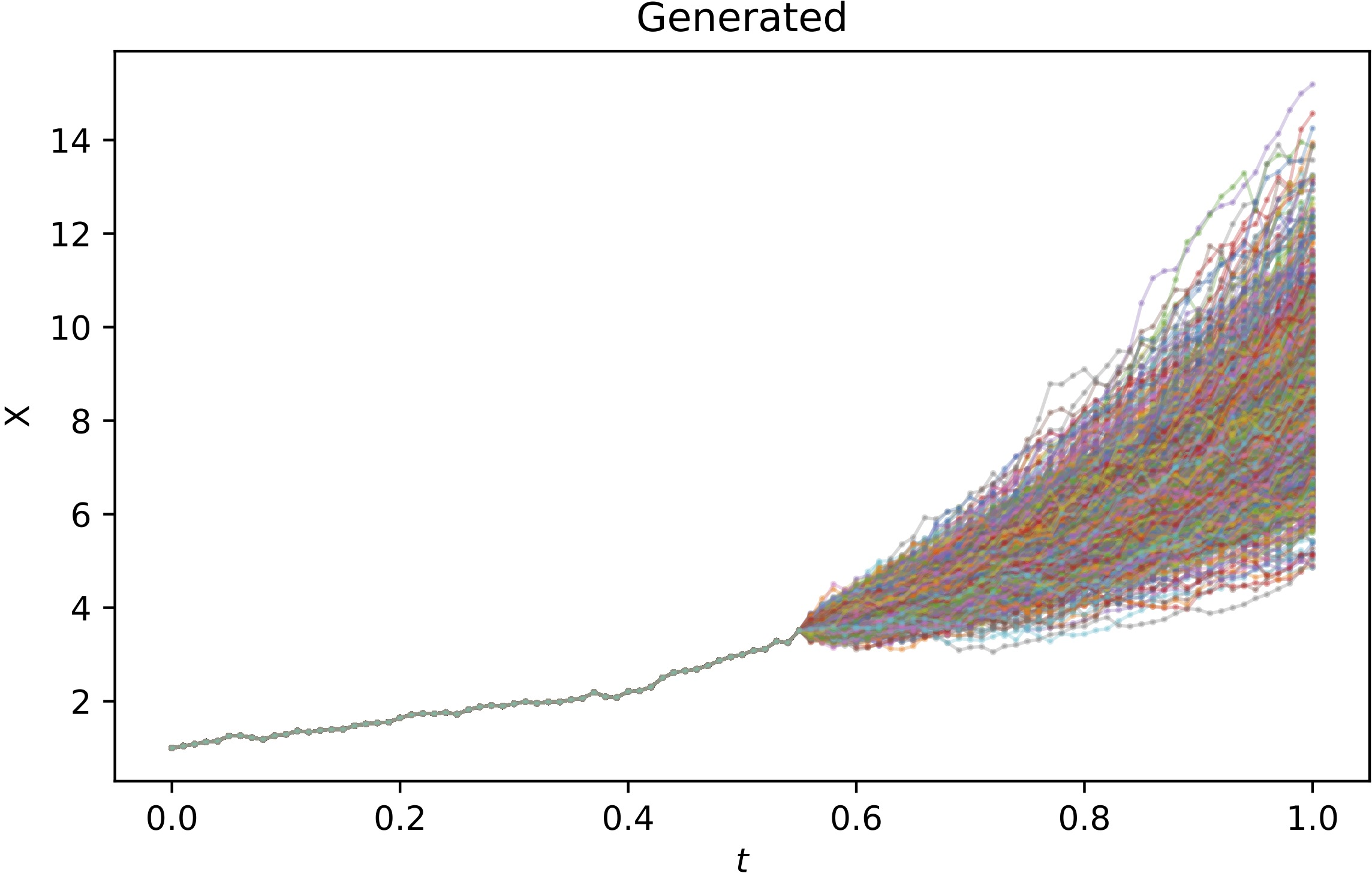
Figure 4: 1000 generated (with joint instantaneous method) path continuations, starting from the history of the first training path until μt8.
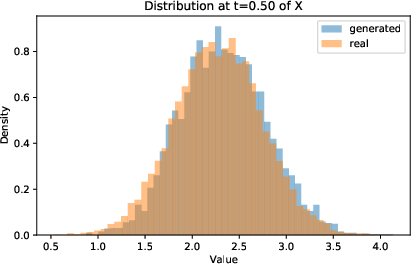
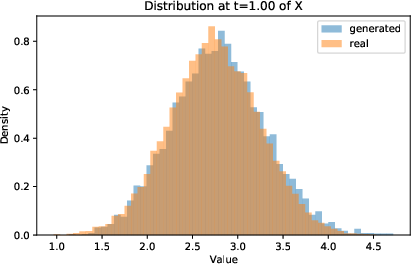
Figure 5: Distribution of μt9 at σt0 and σt1 of true training paths and generated (with joint instantaneous method) paths.
Key empirical findings:
- The joint instantaneous method with bias reduction yields generated samples whose estimated parameters closely match those of the training data, with negligible invalid paths.
- Marginal and pathwise distributions of generated samples are visually and quantitatively indistinguishable from the true process.
- The method is effective even when the underlying process violates some theoretical assumptions (e.g., unbounded coefficients in GBM).
Implementation Considerations
- Model Architecture: The NJODE is implemented as a neural ODE with jump updates at observation times, using feedforward networks for the drift, jump, and output mappings.
- Training: Models are trained with MSE-type losses on conditional expectations, with optional bias correction for diffusion estimation.
- Computational Requirements: Training is efficient due to the non-adversarial, prediction-based loss, and does not require sample generation during training.
- Scalability: The approach is scalable to high-dimensional and path-dependent processes, and naturally accommodates missing and irregular data.
Unlike adversarial generative models (e.g., neural SDE-GANs), the NJODE approach is purely predictive, avoids issues of mode collapse and instability, and provides theoretical convergence guarantees. It also improves upon direct coefficient learning in neural SDEs by handling incomplete data and providing law-level convergence, not just marginal matching.
Implications and Future Directions
The NJODE-based generative modeling framework offers a principled, efficient, and robust approach for learning and simulating complex stochastic processes from partial, irregular data. Its ability to handle path-dependence and missingness makes it particularly suitable for real-world applications in finance, physics, and biology.
Potential future developments include:
- Extension to jump-diffusion and Lévy processes.
- Integration with control and reinforcement learning for stochastic systems.
- Application to high-dimensional, multivariate time series with complex dependencies.
- Further improvements in estimator bias correction and uncertainty quantification.
Conclusion
The paper establishes NJODEs as a theoretically sound and practically effective tool for generative modeling of Itô processes from discrete, irregular, and incomplete observations. The framework's convergence guarantees, empirical performance, and flexibility position it as a strong alternative to adversarial and marginal-matching generative models for stochastic processes.

