- The paper introduces RewardMap, a multi-stage RL strategy with difficulty-aware reward design to address sparse rewards in fine-grained visual reasoning.
- It leverages the ReasonMap-Plus dataset, extending benchmark questions with dense rewards to streamline cold-start training of multimodal language models.
- Experimental results show significant performance gains across benchmarks and enhanced perceptual and reasoning skills in structured spatial tasks.
RewardMap: Multi-Stage Reinforcement Learning for Fine-Grained Visual Reasoning
Introduction
The paper introduces RewardMap, a multi-stage reinforcement learning (RL) framework designed to address the challenge of sparse rewards in fine-grained visual reasoning tasks for multimodal LLMs (MLLMs). The work is motivated by the persistent difficulty MLLMs face in spatial reasoning over structured, information-rich inputs such as transit maps, as highlighted by the ReasonMap benchmark. Standard RL approaches are hampered by reward sparsity and unstable optimization, particularly in long-horizon reasoning scenarios. RewardMap tackles these issues through a combination of dataset extension (ReasonMap-Plus) and a novel RL curriculum with difficulty-aware reward shaping.
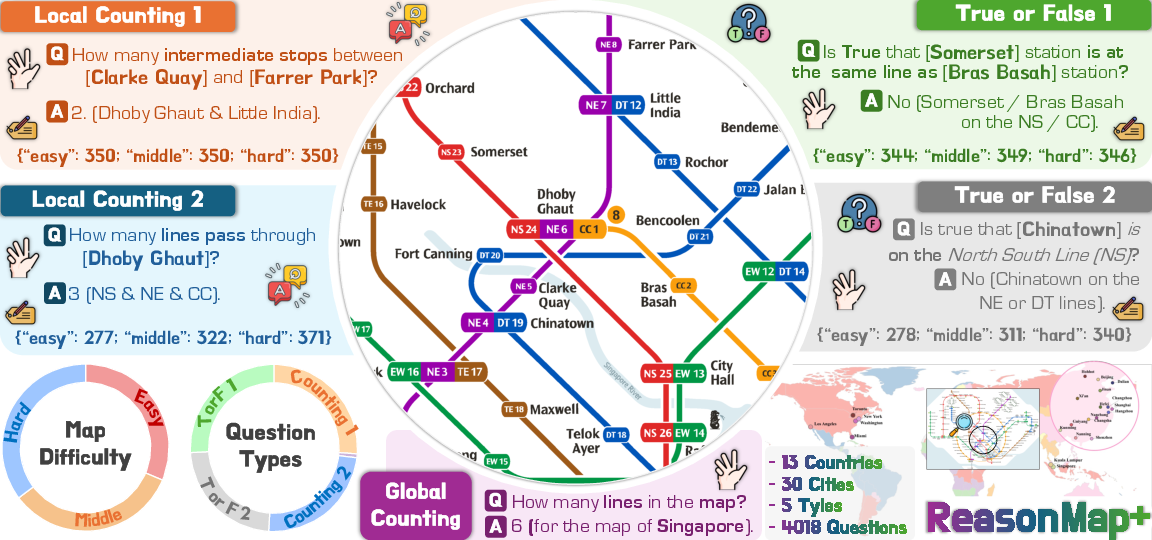
Figure 1: ReasonMap-Plus dataset overview, showing diverse question types and global coverage across cities and countries.
ReasonMap-Plus: Dataset Extension for Dense Supervision
ReasonMap-Plus is constructed to provide dense reward signals for cold-start training of MLLMs. It extends ReasonMap by introducing five question categories—global counting, local counting (two variants), and true/false (two variants)—each probing different aspects of fine-grained visual understanding. The dataset is organized along a difficulty continuum, with explicit annotations for both map and question difficulty. This structure enables curriculum learning and facilitates the staged progression from simple perception tasks to complex reasoning.
The dataset comprises 4,018 questions from 30 cities, balanced across difficulty levels and question types. The construction pipeline ensures diversity and correctness through template-based generation and manual review. This dense supervision is critical for effective RL initialization, mitigating the cold-start problem and enabling models to acquire foundational perceptual skills before tackling abstract reasoning.
RewardMap Framework: Difficulty-Aware Multi-Stage RL
RewardMap integrates two key components: a difficulty-aware reward design and a multi-stage RL curriculum. The RL backbone is Group Relative Policy Optimization (GRPO), which updates the policy based on group-centered advantages, but is sensitive to reward sparsity.
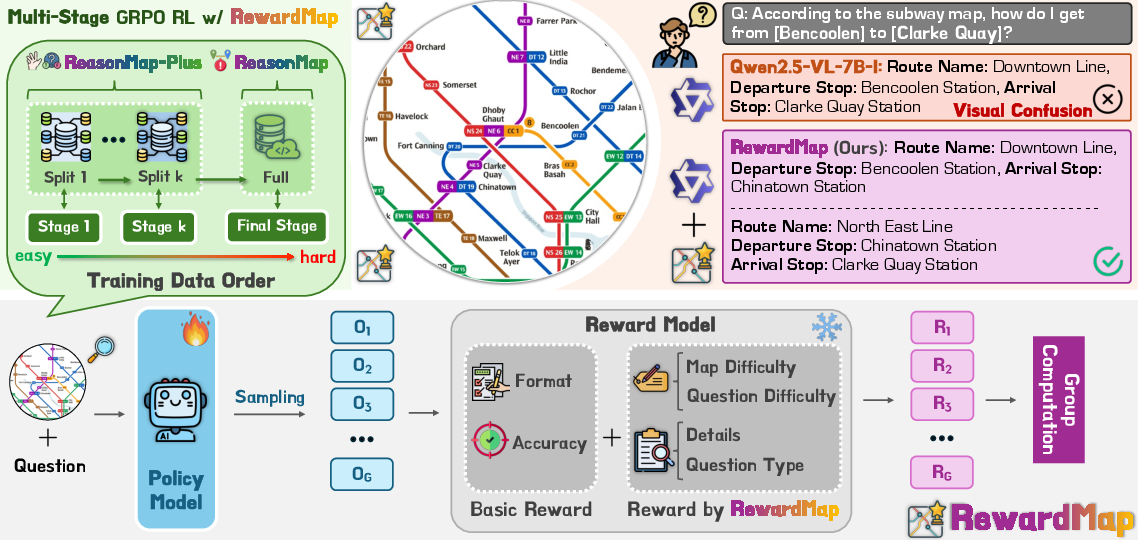
Figure 2: RewardMap framework overview, illustrating difficulty-aware reward design and multi-stage RL curriculum scheduling.
Difficulty-Aware Reward Design
The reward function in RewardMap is a weighted sum of three terms:
- Format Reward: Enforces compliance with output conventions (e.g., boxed answers).
- Correctness Reward: Assesses exact match or benchmark-specific correctness.
- Detail Reward: Provides partial credit for correct subcomponents (e.g., origin/destination stops, route names, transfer stations), alleviating reward sparsity in complex planning tasks.
The overall reward is scaled by a difficulty-aware weight, which incorporates both map and question difficulty. This design ensures that harder tasks yield proportionally higher rewards, guiding the model to focus on challenging samples and improving reward signal propagation.
Multi-Stage RL Curriculum
RewardMap employs a curriculum learning strategy, scheduling training data from easy to hard across multiple stages:
- Global Curriculum Principle: Tasks are partitioned by type and difficulty, ensuring the agent first masters basic perception before progressing to reasoning.
- Local Stochasticity Principle: Within each stage, samples are shuffled to prevent overfitting to a fixed trajectory.
This staged approach systematically bridges perception and reasoning, stabilizing optimization and enabling effective RL in the presence of sparse rewards.
Experimental Results
RewardMap is evaluated on ReasonMap, ReasonMap-Plus, and six additional benchmarks covering spatial reasoning, fine-grained visual reasoning, and general tasks. The framework consistently outperforms baselines, including SFT, SFT→RL, and RL with basic reward design.
- On ReasonMap, RewardMap achieves a weighted accuracy of 31.77% (long questions), surpassing the best open-source baseline (Qwen2.5-VL-72B-Instruct) and approaching closed-source performance (Seed1.5-VL).
- On ReasonMap-Plus, RewardMap attains 74.25% weighted accuracy, outperforming all baselines and reference models.
- Across six external benchmarks, RewardMap yields an average improvement of 3.47%, with the largest gain (13.51%) on SpatialEval.
Ablation studies confirm the complementary benefits of the reward design and multi-stage curriculum. The framework is robust across model scales, with significant improvements observed even for smaller models (Qwen2.5-VL-3B-Instruct).
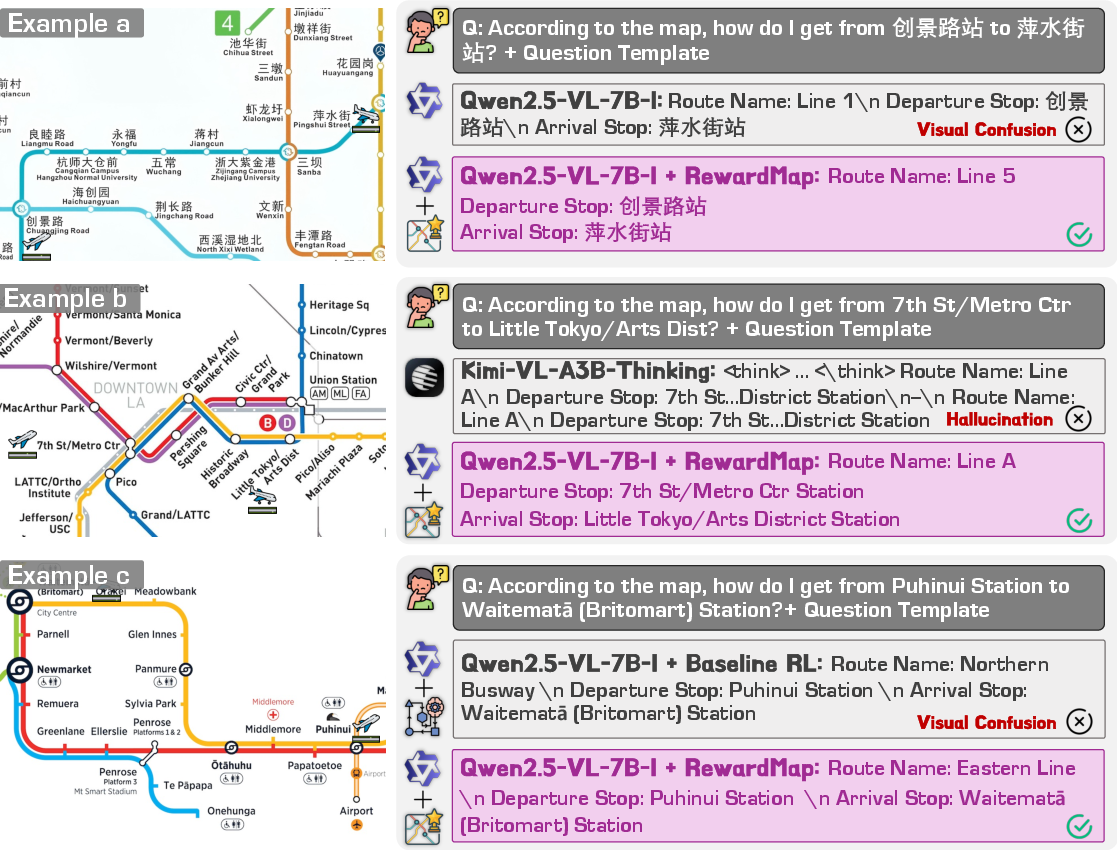
Figure 3: Qualitative comparison of RewardMap against reference models and RL baselines, demonstrating superior route identification and reduced hallucination.
Diagnostic Analysis
RewardMap effectively mitigates reward sparsity, as evidenced by smoother and higher reward trajectories during training compared to baseline RL. The multi-stage curriculum and detail reward design are both necessary for optimal performance; coarse-grained or single-component variants yield inferior results. The use of ReasonMap-Plus for cold-start training is shown to be critical, with consistent gains across all strategies.
Implications and Future Directions
RewardMap establishes a principled approach for applying RL to structured visual reasoning tasks in MLLMs, overcoming the bottleneck of sparse rewards. The difficulty-aware reward shaping and multi-stage curriculum are broadly applicable to other domains characterized by long-horizon reasoning and sparse supervision. The demonstrated generalization across diverse benchmarks suggests that RewardMap enhances both perceptual and reasoning capabilities, not merely overfitting to transit maps.
Theoretically, the work highlights the importance of reward granularity and curriculum design in RL for multimodal models. Practically, it provides a scalable framework for improving MLLM performance in real-world navigation, planning, and spatial reasoning applications. Future research may extend RewardMap to other structured visual domains (e.g., medical imaging, scientific diagrams), explore adaptive curriculum strategies, and investigate integration with advanced RL algorithms beyond GRPO.
Conclusion
RewardMap addresses the challenge of sparse rewards in fine-grained visual reasoning for MLLMs through a combination of dataset extension and multi-stage RL with difficulty-aware reward shaping. The framework yields consistent and substantial improvements across benchmarks, demonstrating enhanced generalization and robustness. The approach provides a foundation for further advances in RL-driven multimodal reasoning, with broad implications for both theory and application.