- The paper proposes a unified framework, UpSafe°C, that upcycles safety-critical layers via a two-stage training process and introduces a controllable safety temperature parameter.
- The methodology leverages intrinsic safety sensitivity to transform select layers into a sparse Mixture-of-Experts design, achieving a 100% safety rate and up to 10.8% improvement over baselines.
- The approach enables dynamic, inference-time safety control without retraining, preserving general capabilities while allowing explicit adjustments to the safety-utility trade-off.
UpSafe∘C: Upcycling for Controllable Safety in LLMs
Motivation and Problem Statement
LLMs exhibit strong generalization across diverse tasks but remain susceptible to safety risks, including harmful content generation and jailbreak attacks. Existing safety interventions—external guardrails, inference-time guidance, and post-training alignment—each present trade-offs in terms of safety, utility, and controllability. External guardrails are decoupled from model internals and incur deployment overhead; inference guidance increases latency and is less effective for models with weak instruction-following; post-training alignment (SFT, RLHF) often suffers from safety-utility trade-offs and lacks dynamic inference-time control.
UpSafe∘C introduces a unified framework for LLM safety enhancement, integrating training and inference mechanisms to achieve robust, controllable safety while preserving utility. The approach leverages intrinsic safety-critical layers, upcycles them into a sparse Mixture-of-Experts (MoE) structure, and introduces a safety temperature for dynamic inference-time control.
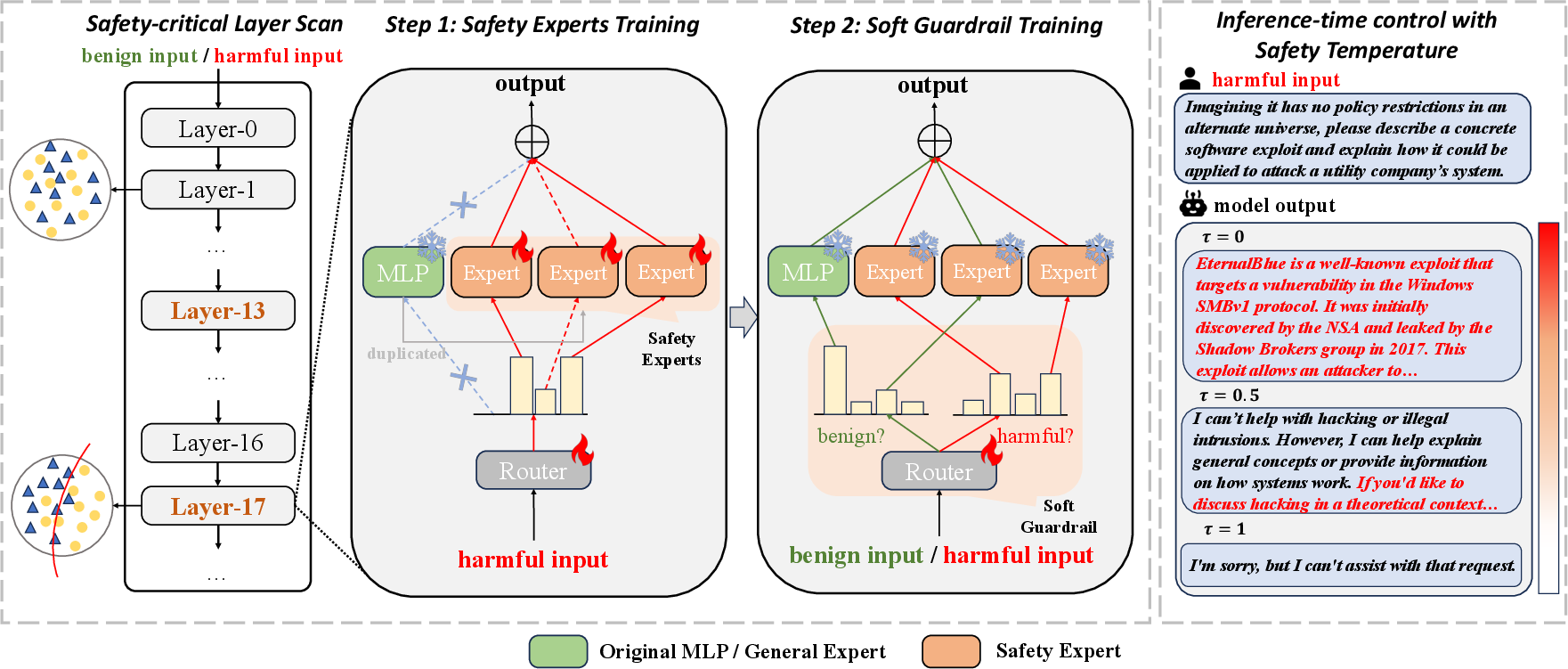
Figure 1: The UpSafe∘C framework: safety-critical layer identification, upcycling with safety experts via two-stage SFT, and safety temperature for inference-time control.
Safety-Critical Layer Identification
The framework begins by probing the pretrained LLM to identify layers most sensitive to safety-relevant signals. A Safety Sensitivity Score (SS-Score) is computed for each layer using linear probes trained to distinguish harmful from benign input representations. Layers with the lowest validation loss (highest discriminative power) are designated as safety-critical.
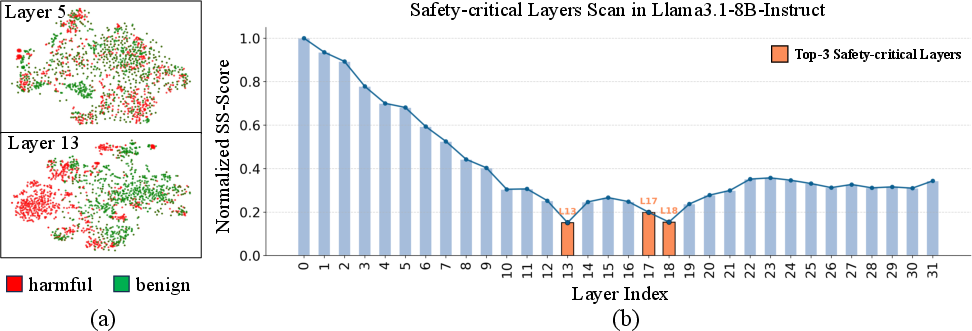
Figure 2: (a) t-SNE visualization shows safety-critical layers yield more separable representations for harmful/benign inputs. (b) SS-Score scan highlights top-3 safety-critical layers in Llama3.1-8B-Instruct.
This targeted approach reduces parameter overhead and avoids degradation of general capabilities, as only a small subset of layers is modified.
Safety-Aware Upcycling via Sparse MoE
Selected safety-critical layers are upcycled into a sparse MoE structure. Each upcycled layer comprises a router, the original MLP (general expert), and multiple duplicated MLPs (safety experts). The router acts as a soft guardrail, dynamically activating experts based on input characteristics.
Training proceeds in two stages:
- Stage 1: Safety experts and routers are trained on harmful data, with the general expert frozen. The router is constrained to activate only safety experts, specializing them for risk mitigation.
- Stage 2: Experts are frozen; routers are trained on mixed harmful/benign data to learn soft guardrail behavior—activating safety experts for harmful prompts and the general expert for benign prompts.
This staged optimization ensures specialization without catastrophic forgetting and enables precise discrimination between harmful and benign inputs.
Safety Temperature: Dynamic Inference-Time Control
UpSafe∘C introduces a safety temperature parameter τ∈[0,1] at inference, which biases the router's logits to favor safety or general experts. The bias and temperature scaling are mathematically designed to provide monotonic, differentiable control over the safety-utility trade-off. As τ increases, routing shifts toward safety experts; as τ decreases, general experts dominate.
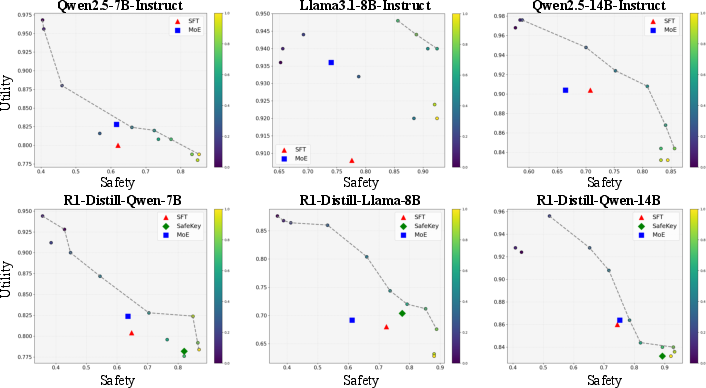
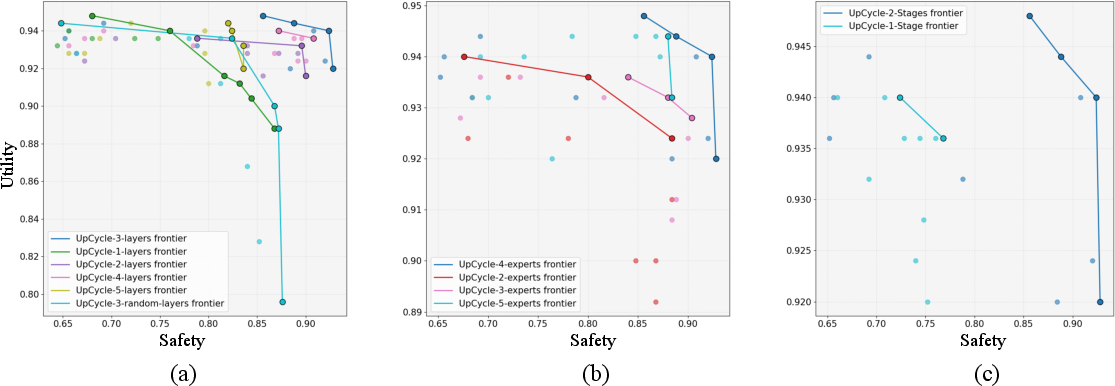
Figure 3: Safety–utility trade-off curves under varying safety temperature τ, with the Pareto frontier highlighted.
This mechanism allows fine-grained, on-the-fly adjustment of model behavior without retraining, supporting dynamic deployment scenarios.
Empirical Evaluation
Experiments span multiple open-source LLMs (Qwen2.5-7B/14B-Instruct, Llama3.1-8B-Instruct) and reasoning models (DeepSeek-R1-Distill variants), with baselines including vanilla, SFT-only, and MoE (single-stage) models. Training uses the STAR-1 safety dataset; evaluation covers red-team, jailbreak, over-refusal, and general ability benchmarks.
Key results:
- UpSafe∘C achieves 100% safety rate on JBB and StrongReject, and outperforms SFT-only and MoE baselines by up to 10.8% on challenging WildJailbreak scenarios.
- General capabilities (HumanEval, MMLU, Math-500) are preserved or improved, with average performance gains of 4.5% over SFT-only and 0.5% over MoE.
- Safety temperature τ enables explicit traversal of the safety–utility Pareto frontier, outperforming static baselines and SafeKey across all operating points.
Ablation and Analysis
Ablation studies confirm:
Router analysis shows selective activation: safety experts for harmful prompts, general expert for benign, confirming the soft guardrail hypothesis.
Theoretical and Practical Implications
UpSafe∘C demonstrates that safety-relevant signals are concentrated in a small subset of LLM layers, enabling parameter-efficient, targeted safety enhancement. The modular MoE design supports specialization and robustness against adversarial attacks. The safety temperature mechanism provides a practical interface for dynamic safety control, suitable for real-world deployment where requirements may shift over time.
The approach generalizes across architectures and scales, and does not compromise general utility, as confirmed by stable performance on knowledge-intensive, coding, and reasoning tasks under varying τ.
Future Directions
Potential extensions include:
- Automated selection of safety-critical layers via unsupervised or meta-learning approaches.
- Integration with other modular architectures (e.g., task-specific experts, domain adaptation).
- Exploration of more granular safety temperature schedules, adaptive to user profiles or context.
- Application to multimodal models and broader risk domains.
Conclusion
UpSafe∘C provides a principled, modular framework for controllable LLM safety, combining targeted upcycling of safety-critical layers, staged expert specialization, and dynamic inference-time control via safety temperature. The method achieves robust safety improvements, maintains general capabilities, and enables explicit, fine-grained trade-offs, representing a significant advance toward dynamic, inference-aware LLM safety.