GeoSURGE: Geo-localization using Semantic Fusion with Hierarchy of Geographic Embeddings
Abstract: Worldwide visual geo-localization aims to determine the geographic location of an image anywhere on Earth using only its visual content. Despite recent progress, learning expressive representations of geographic space remains challenging due to the inherently low-dimensional nature of geographic coordinates. We formulate global geo-localization as aligning the visual representation of a query image with a learned geographic representation. Our approach explicitly models the world as a hierarchy of learned geographic embeddings, enabling a distributed and multi-scale representation of geographic space. In addition, we introduce a semantic fusion module that efficiently integrates appearance features with semantic segmentation through latent cross-attention, producing a more robust visual representation for localization. Experiments on five widely used geo-localization benchmarks demonstrate that our method achieves new state-of-the-art results on 22 of 25 reported metrics. Ablation studies show that these improvements are primarily driven by the proposed geographic representation and semantic fusion mechanism.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a computer to guess where a photo was taken anywhere on Earth using only what’s in the picture. The authors present a new method, called GeoSURGE, that builds a smarter “map in the computer’s head” and creates stronger picture features so the computer can match photos to places more accurately.
To keep it simple, think of two big ideas working together:
- A smarter map: the world is split into puzzle pieces of different sizes (from big to small), and each piece gets its own learned “fingerprint.”
- A smarter view of the photo: the model looks at both the photo’s fine details (colors and textures) and its meanings (what objects are in it, like sky, road, buildings), then blends them cleverly.
What questions are the researchers asking?
In plain terms, the paper asks:
- How can we represent the whole Earth in a way that’s easy for a computer to learn and use for locating images, without getting stuck on the limits of GPS numbers alone?
- Can we make photo features more reliable by combining what the image looks like with what it contains (its semantics), so things like lighting or weather don’t confuse the model?
- Will this combination beat the current best methods on standard tests?
How did they do it?
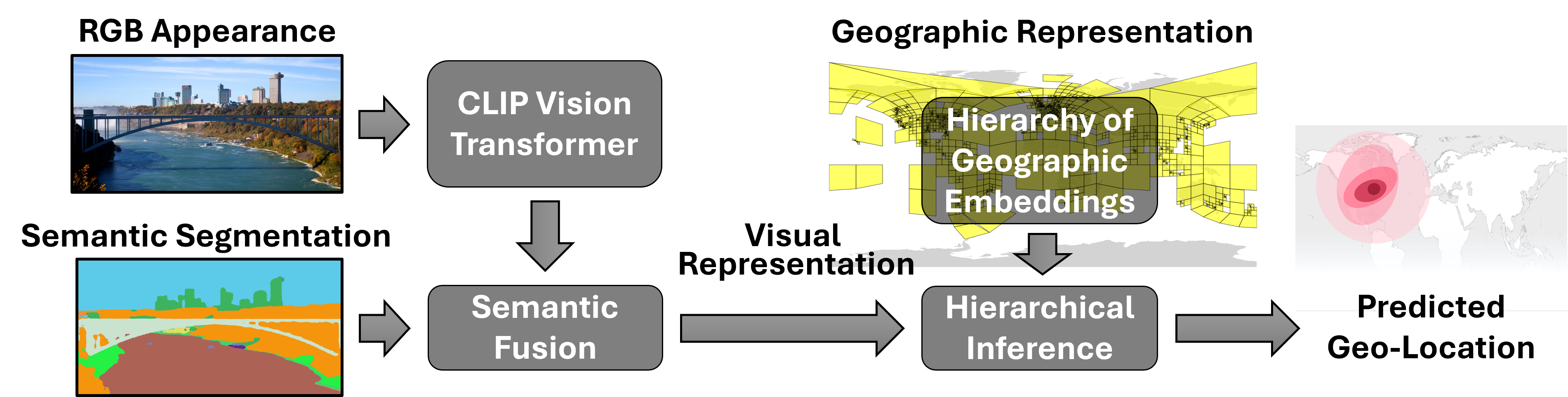
A smarter map of the world (hierarchy of geographic embeddings)
- Imagine zooming in on a map: continent → country → region → city → neighborhood. GeoSURGE does something similar by splitting Earth into “geocells” at several zoom levels.
- Instead of treating each geocell like a label (e.g., “Cell 123”), the system learns a unique numeric fingerprint (an “embedding”) for each geocell. This is like giving every puzzle piece a special code that captures what that area looks like across many photos.
- Because there are several levels (big to small), the model can reason at multiple scales: first roughly where in the world, then more precisely.
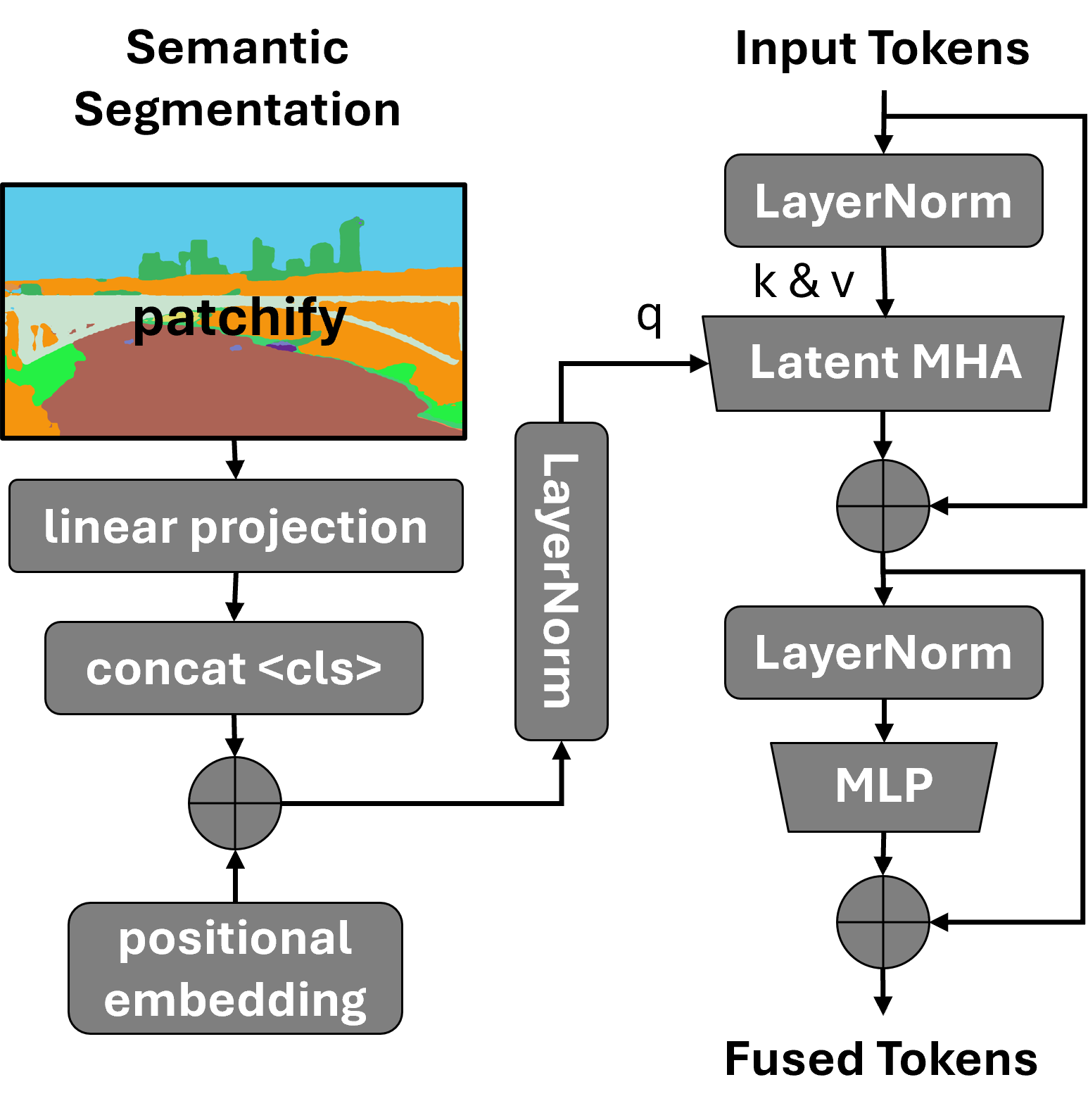
Seeing both details and meaning (semantic fusion)
- The model extracts two kinds of information from a photo: 1) Appearance: fine-grained visual details (colors, textures, patterns). 2) Semantics: what’s in the scene (sky, road, trees, people, water), made by a “semantic segmentation” tool that labels each pixel by object type.
- GeoSURGE blends these using a mechanism called “cross‑attention,” which you can imagine as a helpful conversation: the semantics (what’s where) ask the appearance features (how it looks) for the most relevant details. This creates a more robust photo fingerprint that’s less fooled by changes in lighting, weather, or moving things like cars and people.
Teaching the system (training with contrastive learning)
- The model learns by pairing each training photo with the correct geocell fingerprint (where it was taken) and many wrong ones.
- It’s trained to pull matching pairs closer and push mismatched pairs apart—like learning to recognize which key fits which lock.
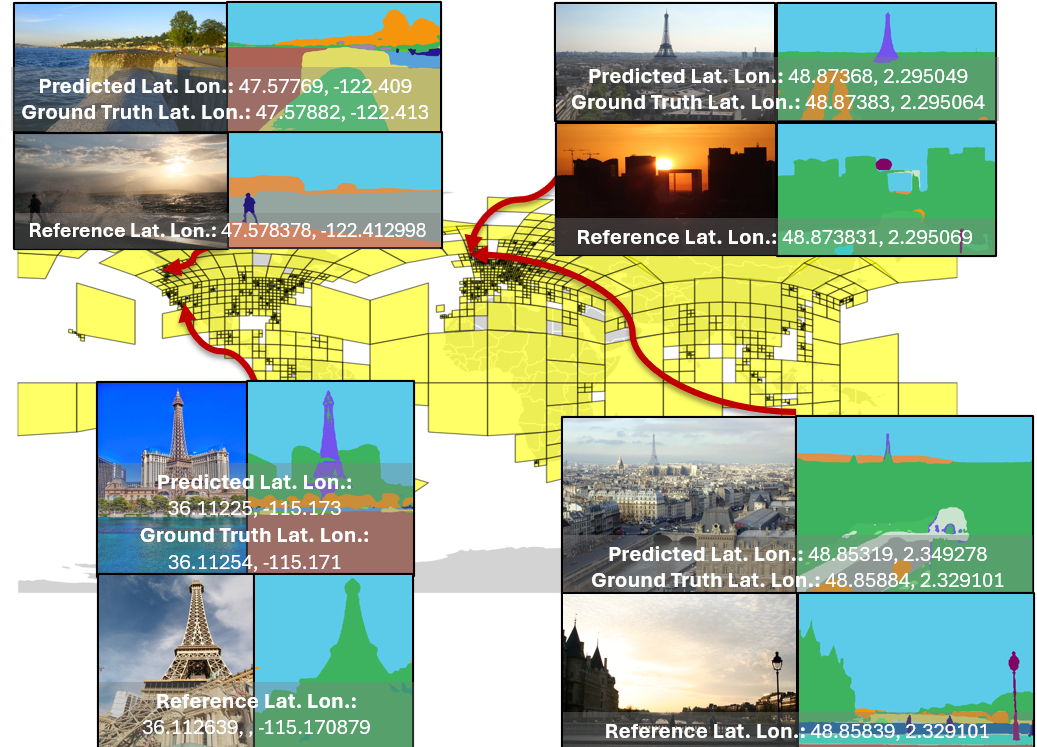
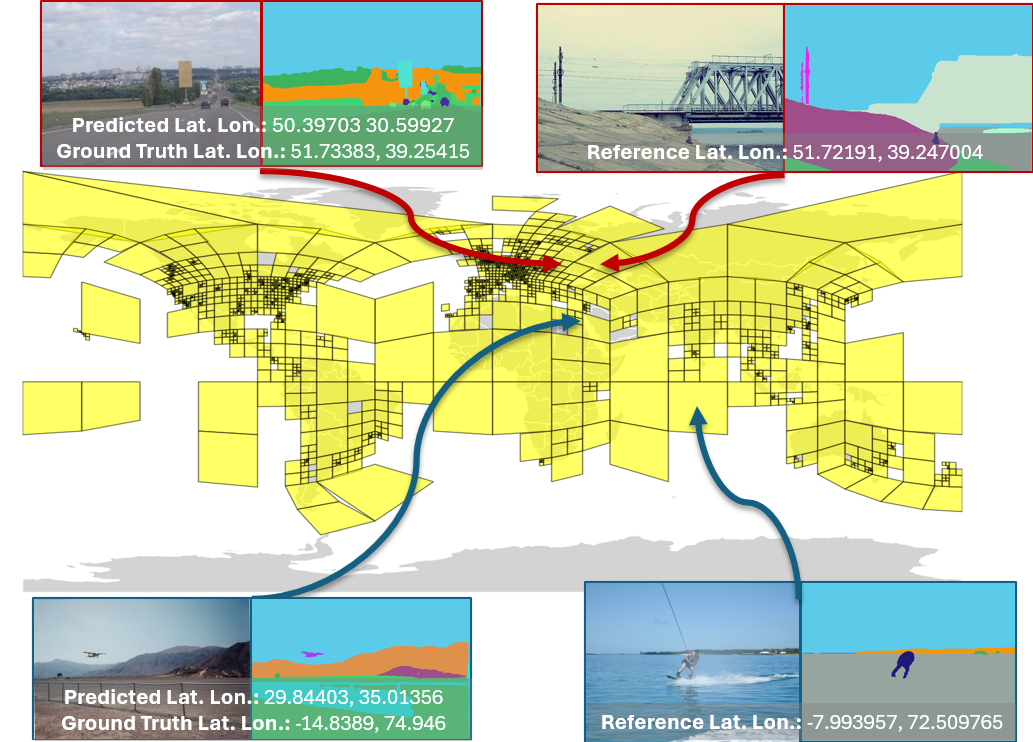
Figuring out a new photo’s location (inference)
- For a new image, the system creates its photo fingerprint and compares it to the geocell fingerprints at every zoom level.
- It combines the evidence across levels (big to small) to choose the most likely location.
What did they find?
On five well-known geo-localization tests (IM2GPS, IM2GPS3k, YFCC4k, YFCC26k, GWS15k), GeoSURGE set new state-of-the-art results on 22 out of 25 evaluation scores. In these tests, success means the predicted spot is within certain distances of the true location (like within 1 km, 25 km, 200 km, 750 km, or 2500 km).
Why this matters:
- The gains mainly came from two things: the multi-level geographic fingerprints (the “smarter map”) and the semantic fusion (the “smarter view”).
- Compared to similar systems that rely only on GPS numbers or only on photo appearance, GeoSURGE’s combination was more accurate and more robust.
Why it matters (implications and impact)
- Stronger global photo geo-localization can help:
- Disaster response teams quickly identify where a photo or video was taken.
- Wildlife or environmental projects map where scenes are captured.
- Navigation and location-based services get better without always needing extra data.
- The method shows that building a structured “mental map” (hierarchical geocells with learned fingerprints) and understanding what’s in a scene (semantics), not just how it looks, can significantly improve location guesses.
- Looking ahead, this approach could be combined with large vision-LLMs to further boost fine-grained accuracy—while still benefiting from a solid, explicit geographic model.
- As always, better location inference raises privacy considerations, so responsible use and safeguards are important.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps that remain unresolved and could guide future research:
- Coverage gaps from training-time geocell filtering: quantify how many geocells are excluded by the τmin threshold, measure test-time frequency of queries falling into excluded/low-sample regions, and develop strategies (neighbor smoothing, data augmentation, synthetic sampling, or few-shot adaptation) to handle them.
- Prediction for low-data or unseen geocells: design fallback mechanisms (e.g., nearest-neighbor in geodesic/adjacency space, uncertainty-aware abstention) and evaluate their impact on global accuracy and fairness.
- Cross-level training-consistency: the hierarchy’s partitions are trained independently but combined at inference via probability products; assess whether joint multi-level training with consistency constraints or shared parameters improves calibration and accuracy.
- Hierarchical probability aggregation: validate the independence assumption implicit in multiplying level-wise softmax probabilities; compare against learned aggregation (e.g., shallow MLP, conditional random fields, or Bayesian formulations) and perform probability calibration tests.
- Within-cell coordinate refinement: clarify how final GPS is derived (cell centroid vs. learned anchor) and evaluate continuous offset regression or retrieval-within-cell to reduce GCD error, especially at street/city scales.
- Spatial structure in geographic embeddings: embeddings are free parameters without explicit spatial priors; study adjacency-aware regularization (graph Laplacian, geodesic kernels), neighborhood contrastive losses, or graph neural networks over geocells.
- Partitioning scheme sensitivity: compare S2-based balanced partitions with alternatives (e.g., H3 hexagons, equal-area grids, administrative/climate/biome-driven partitions), and analyze trade-offs in resolution, coverage, and performance.
- Hyperparameter robustness: perform sensitivity analysis for τmin/τmax schedules, number of hierarchy levels, embedding dimensionality, and temperature parameters per level; report stability across seeds.
- Computational efficiency and scalability: quantify end-to-end inference latency/throughput and memory (segmentation + fusion + global similarity over all geocells), and develop scalable search (e.g., hierarchical pruning, approximate nearest neighbor over cell embeddings) for real-time/edge deployment.
- Segmentation dependency and domain robustness: measure accuracy degradation under semantic segmentation noise (night, weather, motion blur, occlusion), and evaluate different segmenters (e.g., Mapillary, outdoor-specific models, SAM variants) and label taxonomies for geo-relevant semantics.
- Fusion mechanism analysis: explain why semantic fusion sometimes underperforms (“None” better for certain GWS15k metrics), identify when fusion helps/hurts, and explore adaptive or confidence-weighted fusion, gating, token pruning, or alternative cross-modal adapters.
- Token-level representation choices: compare using CLS vs. pooled/spatial tokens for localization, investigate multi-head pooling strategies, and assess the impact of patch size and latent dimension settings on fine-grained accuracy.
- Negative sampling strategy: InfoNCE relies on in-batch negatives; investigate memory-bank, hard-negative mining across neighboring geocells, and mitigation of false negatives (different images from the same or adjacent cells).
- Uncertainty estimation and output format: provide calibrated confidence maps, top-K geocell paths, and uncertainty-aware metrics; study decision thresholds for abstention or hierarchical fallback to coarser levels.
- Scene-type stratification: analyze performance across indoor/outdoor, urban/rural, coastal/mountainous, and latitude bands; identify failure modes and tailor representations (e.g., specialized sub-networks) for hard scene categories.
- Textual cues and OCR: quantify gains from fusing image text (signage, language, scripts) via OCR/CLIP text tokens with semantic and visual features, especially for street/city-level localization.
- Hybridization with LVLMs: systematically evaluate combining GeoSURGE’s structured geographic embeddings with LVLM reasoning (RAG over geocells, tool-use pipelines) and measure cost–performance trade-offs at fine-grained scales.
- Multi-image/contextual cues: extend to sequences, panoramas, or auxiliary metadata (EXIF time, camera orientation) and quantify improvements over single-image localization.
- Training data bias and fairness: characterize MP-16 geographic and scene distributions, measure performance disparities across underrepresented regions, and test mitigation (reweighting, balanced sampling, data augmentation).
- Reproducibility and benchmark integrity: release code/pretrained weights, detail geocell indices per level, and provide a reproducible GWS15k protocol (given dataset access limitations) to ensure exact comparability.
- Adjacency-aware errors: explicitly evaluate confusions between neighboring geocells, report “near miss” metrics (e.g., adjacency-aware accuracy), and design losses that penalize distant mistakes more than local ones.
- Retrieval refinement within geocells: assess a two-stage approach (predict geocell, then retrieve/top-K refine using image references) and compare against current single-stage embedding matching.
- Cross-view and multimodal extensions: study integration with satellite/aerial views and map data (roads, landcover), evaluating cross-view contrastive objectives for global coverage and finer localization.
- Backbone diversity and scale: compare different vision backbones (OpenCLIP variants, ViT-H/G, ConvNeXt), extent of fine-tuning (beyond last block), and their effect on accuracy and computational cost.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and compute, leveraging the paper’s hierarchical geographic embeddings and semantic fusion for robust, global image geolocation. Each item specifies sectors, potential tools/workflows, and feasibility notes.
- Photo platforms auto-geotagging and album organization
- Sectors: Software, Consumer Apps
- Tools/workflows: Cloud API/SDK that returns best geocell + confidence; DAM (digital asset management) plugin enabling “search by place” for legacy photos lacking GPS; mobile photo apps offering post-hoc geotag suggestions.
- Assumptions/dependencies: Internet-scale geotagged training data similar to MP-16; compute for batch semantic segmentation (OneFormer) and CLIP inference; user consent and privacy safeguards.
- Newsroom and OSINT media verification
- Sectors: Media, Public Policy, Security
- Tools/workflows: Browser extension or newsroom tool to “Estimate likely location” with coarse-to-fine hierarchy, confidence scoring, alternative top-K geocells; triage dashboards prioritizing high-confidence media for human review.
- Assumptions/dependencies: Editorial standards require human-in-the-loop; model bias toward well-photographed regions; legal/ethical reviews to prevent misuse.
- Disaster response social-media triage
- Sectors: Public Safety, Government
- Tools/workflows: EOC dashboards ingesting public images, clustering by predicted geocell, surfacing street/city-level hits for situational awareness; alerts when imagery clusters in new regions during an event.
- Assumptions/dependencies: Access to real-time social feeds; need for coarse but fast localization; privacy and platform data-sharing agreements.
- Marketplaces, real estate, and insurance photo fraud screening
- Sectors: E-commerce, Real Estate, Insurance, Finance (risk)
- Tools/workflows: Backend service comparing claimed location vs. predicted geocell; auto-flags for manual inspection; claim-photo intake systems that mark “location mismatch” with confidence bands.
- Assumptions/dependencies: Tolerance for false positives; clear user disclosures; geographic performance varies with coverage (sparser regions → lower confidence).
- GIS and mapping curation
- Sectors: Mapping/GIS, Software
- Tools/workflows: Pipeline to geotag user-submitted photos (e.g., community mapping portals) and associate them to S2 cells/nearby POIs; QA workflows highlighting photos that contradict existing map layers.
- Assumptions/dependencies: Integration with S2 or alternative tiling; coverage bias for under-photographed locales.
- Environmental and citizen science data enrichment
- Sectors: Environmental Science, Academia
- Tools/workflows: Batch geotagging of species/land-use images without GPS; deduplicate or cluster observations by region; feed species distribution modeling with geocell-level labels.
- Assumptions/dependencies: Semantics from ADE20K may miss fine-grained ecological classes; requires domain QA.
- Enterprise DAM search and compliance
- Sectors: Enterprise Software, Legal/Compliance
- Tools/workflows: Internal indexing of historical media by predicted location; policy checks (e.g., embargoed regions); audit logs linking inference to model version and confidence.
- Assumptions/dependencies: On-prem or VPC deployment for data governance; model cards and auditability.
- Travel/tourism apps and content discovery
- Sectors: Travel, Consumer Apps
- Tools/workflows: Photo-based “Where was this?” assistant; suggest attractions nearby the predicted location; auto-tagging for itineraries.
- Assumptions/dependencies: City/region-level accuracy sufficient for user value; confidence UI/UX.
- Utilities/telecom field photo localization
- Sectors: Utilities, Telecom, Asset Management
- Tools/workflows: Associate technician photos with assets via predicted geocells when GPS is missing; bulk reconcile images to infrastructure segments.
- Assumptions/dependencies: Works best outdoors; indoor/subterranean scenes reduce accuracy.
- Post-mission drone and UAV imagery alignment
- Sectors: Robotics, Aerial Inspection
- Tools/workflows: Offline pipeline to align untagged frames to geocells; augment flight logs; sanity-check suspected GPS spoof/spike events.
- Assumptions/dependencies: Not a drop-in for real-time navigation; requires camera calibration consistency and outdoor scenes.
- Education and geogaming enhancements
- Sectors: Education, Gaming
- Tools/workflows: GeoGuessr-like engines powered by hierarchical geocell embeddings; classroom exercises linking visuals to geographic reasoning.
- Assumptions/dependencies: Curated content to avoid privacy-sensitive imagery; compute for interactive latency.
- Content moderation and geo-policy enforcement
- Sectors: Trust & Safety, Social Platforms
- Tools/workflows: Soft signals for location-based policy checks (e.g., restricted areas); route for human review rather than automatic takedown.
- Assumptions/dependencies: High risk of misuse; must implement strict governance, transparency, and appeals; treat outputs as probabilistic, not ground truth.
Long-Term Applications
These opportunities are plausible with further research, scaling, on-device optimization, or policy frameworks. They build on the paper’s innovations (hierarchical geographic embeddings and semantic fusion).
- GPS-denied visual localization for robots and autonomous systems
- Sectors: Robotics, Automotive, Defense
- Tools/workflows: Onboard “GeoSURGE-Lite” that provides coarse-to-fine geocell priors feeding SLAM; safety layers for GPS spoofing detection.
- Assumptions/dependencies: Real-time inference on edge accelerators; more robust indoor/cross-weather performance; rigorous safety validation.
- LVLM-augmented fine-grained geolocation
- Sectors: Software, Media Verification, Mapping
- Tools/workflows: Combine hierarchical embeddings with LVLM RAG (signage, language cues) to push street-level accuracy; reason over temporal context (seasonal vegetation).
- Assumptions/dependencies: Cost-effective LVLM inference; reliable prompt engineering; mitigations for hallucinations and content bias.
- Cross-view fusion with aerial/satellite imagery
- Sectors: Mapping, Energy, Agriculture
- Tools/workflows: Joint embedding linking ground photos to overhead tiles for precise anchoring (e.g., inspection photos to parcels/fields).
- Assumptions/dependencies: Access to up-to-date satellite/aerial imagery; domain adaptation for sensor differences.
- Privacy-preserving training and deployment
- Sectors: Policy, Enterprise Software
- Tools/workflows: Federated training with differential privacy; per-geocell auditability; red-teaming for deanonymization risks.
- Assumptions/dependencies: Legal frameworks and standardized disclosures; privacy budgets and performance trade-offs.
- Regulatory toolkits for disinformation response
- Sectors: Government, NGOs, Platforms
- Tools/workflows: Provenance pipelines that attach geolocation evidence, confidence, and model lineage; standardized evidence packaging for courts/regulators.
- Assumptions/dependencies: Chain-of-custody protocols; inter-agency data sharing; societal consensus on evidentiary standards.
- AR Cloud anchoring from a single photo
- Sectors: AR/VR, Consumer Apps
- Tools/workflows: Global anchor service using hierarchical geocells to rapidly narrow candidate anchors; fusion with device pose for precise placement.
- Assumptions/dependencies: Low-latency inference; map freshness; privacy-preserving scene understanding.
- End-to-end claim automation in insurance
- Sectors: Insurance, Finance (risk)
- Tools/workflows: Automated triage of claim photos with geolocation consistency checks; rules engines for payout routing or SIU escalation.
- Assumptions/dependencies: High-precision geofencing; explainable outputs; compliance and fairness audits.
- Real-time crisis mapping from streaming imagery
- Sectors: Public Safety, Humanitarian Aid
- Tools/workflows: Continuous ingest + geocell clustering to detect emerging hotspots; integration with satellite/video streams; multilingual public dashboards.
- Assumptions/dependencies: Data access agreements; resilient infrastructure at scale; ethical consent for public imagery use.
- Bias-aware, globally equitable geolocation
- Sectors: Academia, Policy
- Tools/workflows: Methods to reweight underrepresented regions, synthetic data augmentation, continuous monitoring for geographic fairness.
- Assumptions/dependencies: Open datasets from the Global South; governance on data sourcing; community partnerships.
- On-device, energy-efficient geolocation
- Sectors: Mobile, IoT
- Tools/workflows: Distilled models, quantization, and efficient segmentation to run on phones/body cams; intermittent connectivity modes.
- Assumptions/dependencies: Hardware acceleration; new training for low-power settings; acceptance of coarser outputs.
- Automated map maintenance and POI validation
- Sectors: Mapping/GIS, Transportation
- Tools/workflows: Batch inference over user imagery to validate POI existence/closure signals; workflows to queue human edits.
- Assumptions/dependencies: Cross-season/domain adaptation; guardrails against vandalism; licensing for map updates.
- Ecological monitoring and enforcement
- Sectors: Environment, Public Policy
- Tools/workflows: Global pipeline to geolocate images of wildlife, deforestation, or pollution events and fuse with remote sensing for enforcement.
- Assumptions/dependencies: Partnerships with NGOs; formal evidence chains; improved semantics beyond ADE20K classes.
- Compliance, governance, and standards for AI geolocation
- Sectors: Policy, Standards Bodies
- Tools/workflows: Model cards, datasheets for geocell coverage, confidence reporting standards, and API best practices.
- Assumptions/dependencies: Multi-stakeholder consensus; periodic audits; alignment with privacy laws (GDPR, state laws).
Notes on feasibility across applications:
- Performance varies by region, scene type, and image quality; street-level accuracy is not guaranteed everywhere.
- Dependencies include large geotagged training datasets, semantic segmentation quality (ADE20K classes via OneFormer), and substantial compute for preprocessing and inference.
- Ethical and legal risks (privacy, surveillance, misidentification) require strict governance, transparency, and human oversight.
- Coverage bias is significant: under-photographed areas and indoor scenes remain challenging; additional data and adaptation will be needed.
Glossary
- ADE20K: A large-scale semantic segmentation dataset providing object/scene categories used for segmentation tasks. "semantic classes are from ADE20K \cite{zhou2019semantic}"
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates to improve training stability. "We trained using the AdamW optimizer"
- CLIP: A vision-LLM that produces powerful image embeddings via contrastive pretraining. "We use CLIP \cite{radford2021learning} to extract features from the RGB image"
- CLS token: A special transformer token used to aggregate information across patches for classification. "plus a CLS token."
- contrastive learning: A training paradigm that pulls matched pairs together and pushes mismatched pairs apart in embedding space. "Our training process uses contrastive learning techniques \cite{radford2021learning}"
- cosine similarity: A similarity metric based on the angle between vectors, often used with normalized embeddings. "maximizes the cosine similarity of the correct pairs"
- geocells: Discrete geographic cells used to partition Earth’s surface for modeling and prediction. "discretize the Earth's surface into geographic cells (geocells)"
- geographic embeddings: Learned feature vectors that represent regions of the Earth. "a hierarchy of learned geographic embeddings"
- geographic representation: The model’s learnable parameterization of geographic space using embeddings over partitions. "The geographic representation is a learned hierarchy of embeddings that correspond to regions of Earth."
- geotagged images: Images annotated with GPS coordinates, used as supervision or references. "a large reference database of geotagged images"
- Google Street View: A global collection of panoramic imagery used as a benchmark source for geo-localization. "the Google Street View image panoramas"
- great circle distance (GCD): The shortest path between two points on a sphere, used as a geo-localization error metric. "We computed the great circle distance (GCD) from each predicted location to the ground truth location using the Haversine distance."
- Haversine distance: A formula for computing great-circle distance from latitude and longitude. "using the Haversine distance."
- hierarchical inference: A prediction strategy that integrates scores across multiple spatial scales in a hierarchy. "GeoSURGE uses a hierarchical inference process to produce a single prediction that integrates the complete partition hierarchy of Earthâs surface."
- InfoNCE loss function: A contrastive objective that maximizes the similarity of positive pairs relative to negatives. "Our learning objective is the InfoNCE loss function \cite{oord2018representation}"
- large vision-LLMs (LVLMs): Foundation multimodal models trained on internet-scale data for vision-language tasks. "leverages LVLMs, such as GPT-4V, extending the retrieval-based approach with retrieval augmented generation (RAG)."
- latent cross-attention: An attention mechanism that fuses modalities through a latent bottleneck for efficiency. "through latent cross-attention"
- multi-headed attention: Parallel attention heads that allow transformers to attend to multiple representation subspaces. "using latent multi-headed attention to promote memory efficiency"
- OneFormer: A transformer-based model for universal image segmentation (semantic/instance/panoptic). "We select OneFormer \cite{jain2023oneformer} for semantic segmentations"
- positional embeddings: Vectors added to tokens to encode positional information in transformers. "and adding positional embeddings."
- Random Fourier Features: A method to approximate kernel mappings via random sinusoidal projections. "introduced specialized components such as Random Fourier Features"
- retrieval augmented generation (RAG): A technique that augments model reasoning with retrieved external evidence. "retrieval augmented generation (RAG)."
- S2 Geometry Library: A spherical geometry library that partitions Earth into hierarchical cells for indexing. "In GeoSURGE we use Googleâs S2 Geometry Library to divide Earth's surface into geocells"
- semantic fusion module: GeoSURGE’s module that fuses RGB appearance and segmentation features to form robust visual embeddings. "we introduce a semantic fusion module that efficiently integrates appearance features with semantic segmentation"
- semantic segmentation: Pixel-wise labeling of an image into semantic categories. "appearance features with semantic segmentation"
- softmax: A normalization that converts scores into a probability distribution. "These similarities are then normalized using softmax to get probabilities."
- Ten Crop method: An evaluation technique that averages predictions over ten cropped views of an image. "we average the prediction of the Ten Crop method to provide a single prediction for the entire image."
- temperature parameters: Scaling factors in contrastive/softmax objectives that control distribution sharpness. "We initialized the learnable temperature parameters in Equation~\ref{eq:loss} to 0.07"
- vision transformer: A transformer architecture operating on image patches for image representation learning. "GeoSURGE first uses the CLIP vision transformer (i.e., without projection and output normalization)"
- visual-language grounding: Supervision linking visual content to textual labels or descriptions. "introduced CLIP and visual-language grounding, by training with images paired with their city names."
Collections
Sign up for free to add this paper to one or more collections.

