- The paper introduces a novel real-time architecture using a diffusion model and an encoder-decoder pipeline for audio-driven 3D facial animation.
- It achieves photorealistic rendering with <15ms GPU latency, leveraging causal audio encoding and universal shared latent codes.
- Empirical evaluations demonstrate superior lip synchronization and reduced temporal artifacts compared to state-of-the-art methods.
Audio Driven Real-Time Facial Animation for Social Telepresence
Introduction and Motivation
Audio-driven facial animation holds critical importance for enabling photorealistic telepresence within immersive virtual environments, particularly in settings such as VR teleconferencing, social interaction, and accessibility applications. Previous methods lacked universality, temporal fidelity, or photorealistic rendering, often constrained by the necessity for personalized data or offline pipelines with substantial latency. The paper introduces a real-time, universally applicable system that animates photorealistic 3D facial avatars from audio input with <15ms GPU latency, using a novel encoder-decoder architecture centered on efficient diffusion modeling, causal audio encoding, and robust system design.
System Architecture and Representation
The system is structured as a modular encoder-decoder pipeline: the encoder E maps causal audio features and synthesized gaze information to shared latent facial expression codes, while the decoder D reconstructs photorealistic 3D face shapes and renders the appearance using a Universal Relightable Prior Model framework, supporting universal semantics and multi-subject generalization.
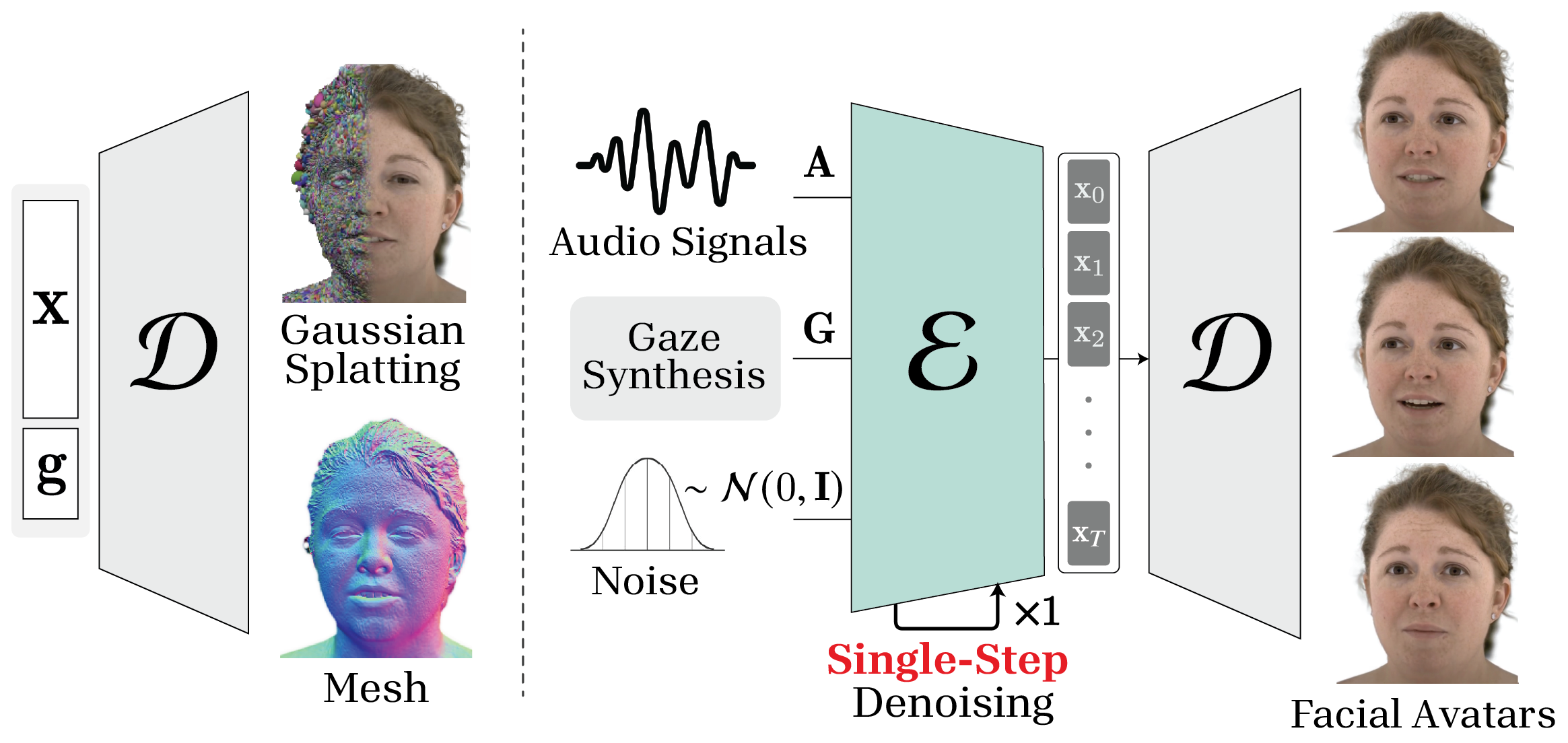
Figure 1: Overview of the decoder (left) and the encoder-decoder pipeline (right). The encoder E generates expression codes in real time based on single-step denoising of a diffusion model, which are decoded into 3DGS and mesh by the decoder D.
The encoder operates online, strictly excluding future input frames via windowed attention masks within the transformer denoising blocks, ensuring minimal latency and causal inference suitable for real-time avatars. The decoder leverages Gaussian Splatting and a learned latent prior for reconstructing high-fidelity mesh and texture, enabling consistent rendering across diverse identities.
Diffusion-Based Audio-to-Expression Model
The latent expression generation utilizes a diffusion process, specifically trained to denoise audio-driven latent codes sample-by-sample. The diffusion model follows DDPM [ho2020ddpm] sampling, but rather than running an iterative reverse process for each frame, the architecture incorporates a single-step distillation strategy. Distribution matching distillation aligns the output distribution of the single-step model with the full multi-step diffusion model, preserving expressivity while permitting rapid inference.
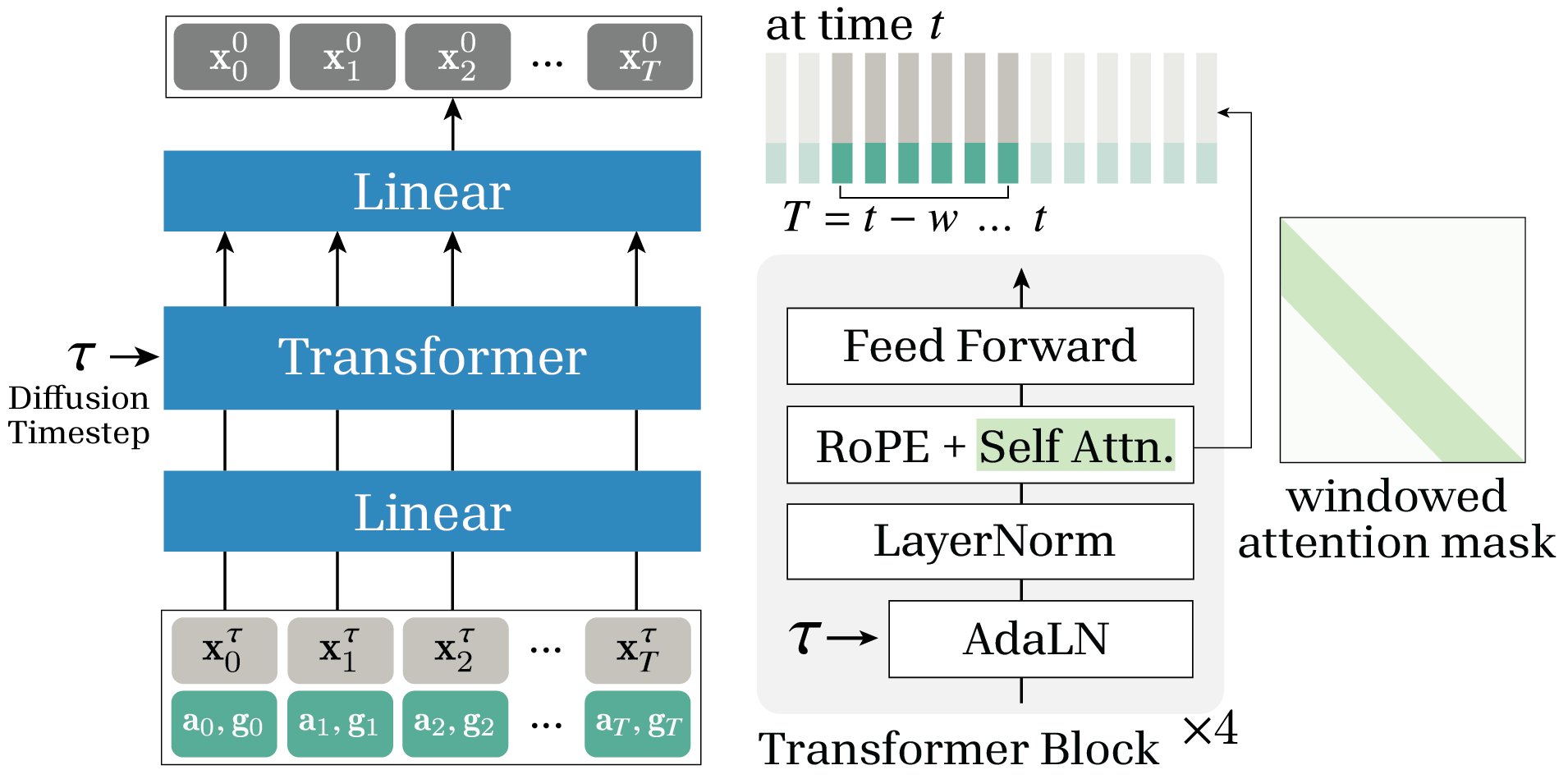
Figure 2: Transformer-based denoising network architecture. Windowed attention mask is applied in the self-attention layer of each Transformer block.
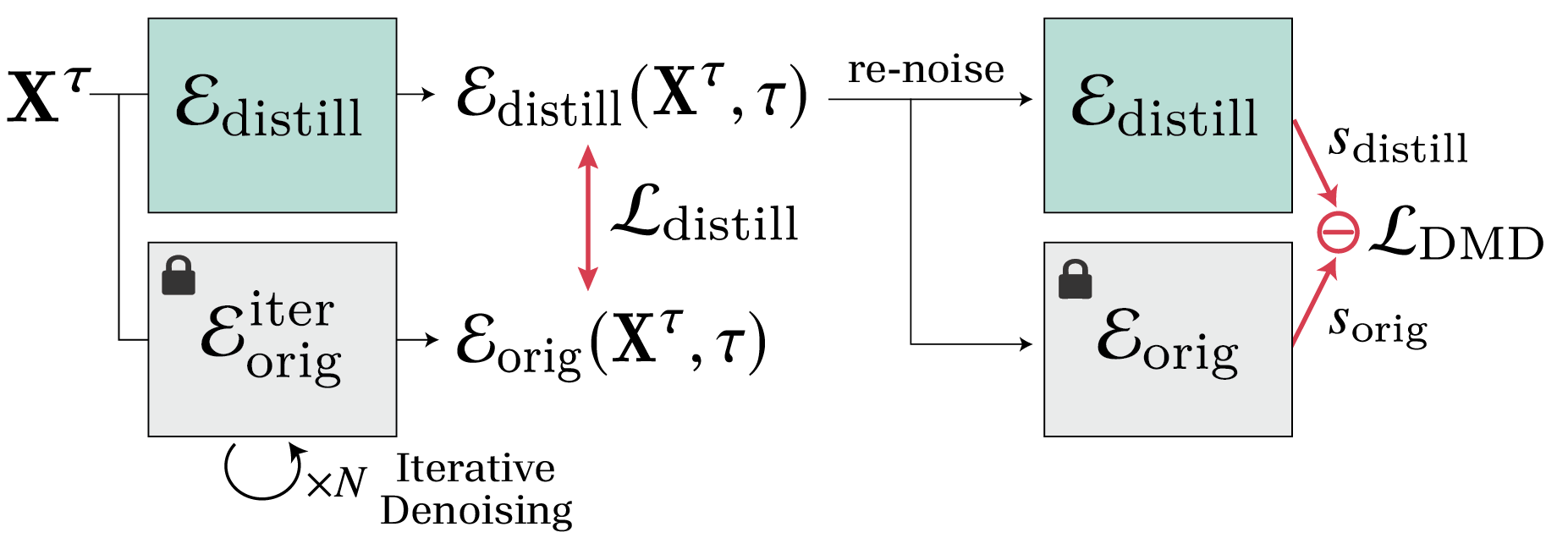
Figure 3: Pipeline of distillation training. The distilled model first learns via Ldistill from the original model's multi step and its own single step outputs, with re-noised samples used to compute LDMD.
Key architectural features:
- Online Transformer: Windowed self-attention restricts receptive field to only past and present states; RoPE relative positional embedding maintains global coherence.
- Classifier-Free Guidance (CFG): Key for conditional expressivity, but dropped at inference for speed post-distillation.
- Geometry-Based Losses: Lvel and Ljitter introduced to guide temporal dynamics and mitigate overfitting toward subjects with larger facial regions, via normalization.
Real-Time System Design Considerations
A crucial implementation decision is the use of strictly causal audio feature encoding. Wav2Vec 1.0 is adopted for its zero-lookahead convolutional architecture, which sharply contrasts with non-causal encoders like HuBERT and Wav2Vec 2.0, which exhibit up to 0.5s lookahead and violate causality—critical for real-time avatar response.
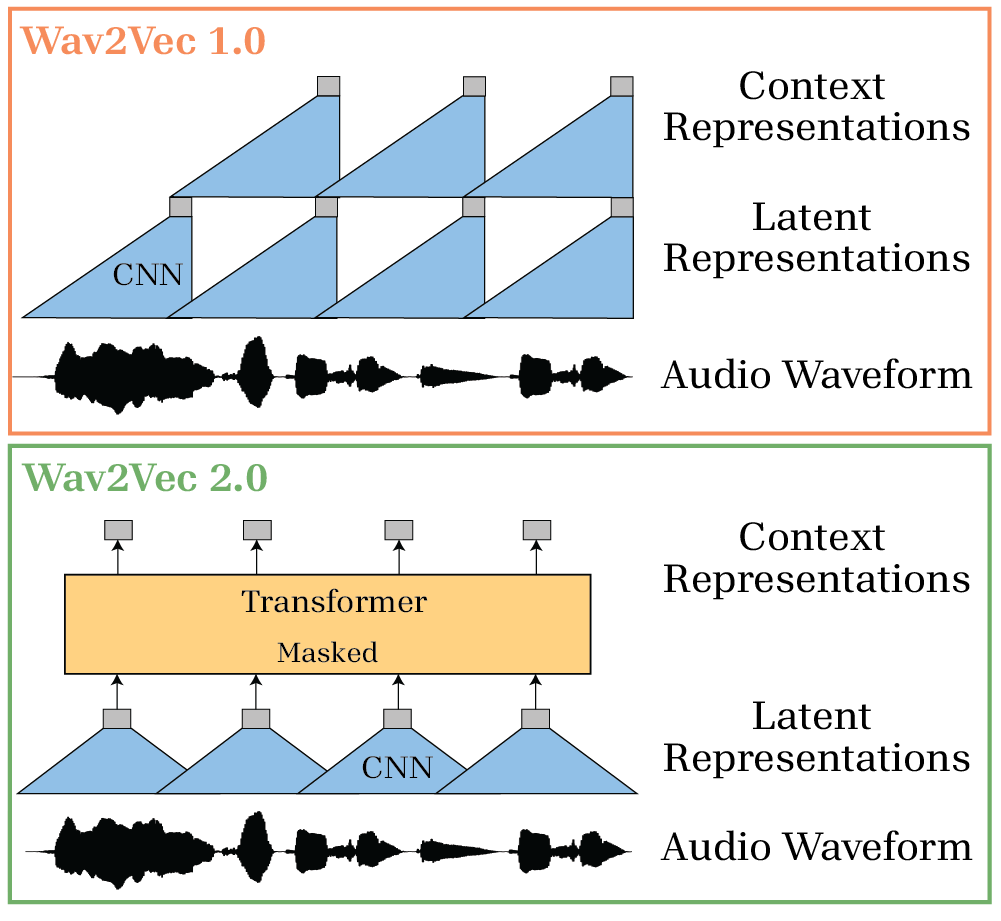
Figure 4: Visualization of network architecture of Wav2vec 1.0 and 2.0 audio encoders, adapted from the original papers.
Outpainting is used to enforce consistency when sampling latent codes at each frame, minimizing discontinuities inherent in stochastic diffusion processes.
Multimodal and Semantic Extensions
The framework accommodates additional modalities, including emotion conditioning and visual sensor integration. Emotion control is realized by inserting zero-initialized convolutional layers in the transformer network, trained with frozen backbone to infuse semantic labels without disrupting phonetic synchronization. CLIP-extracted embeddings feed semantic context into these layers.
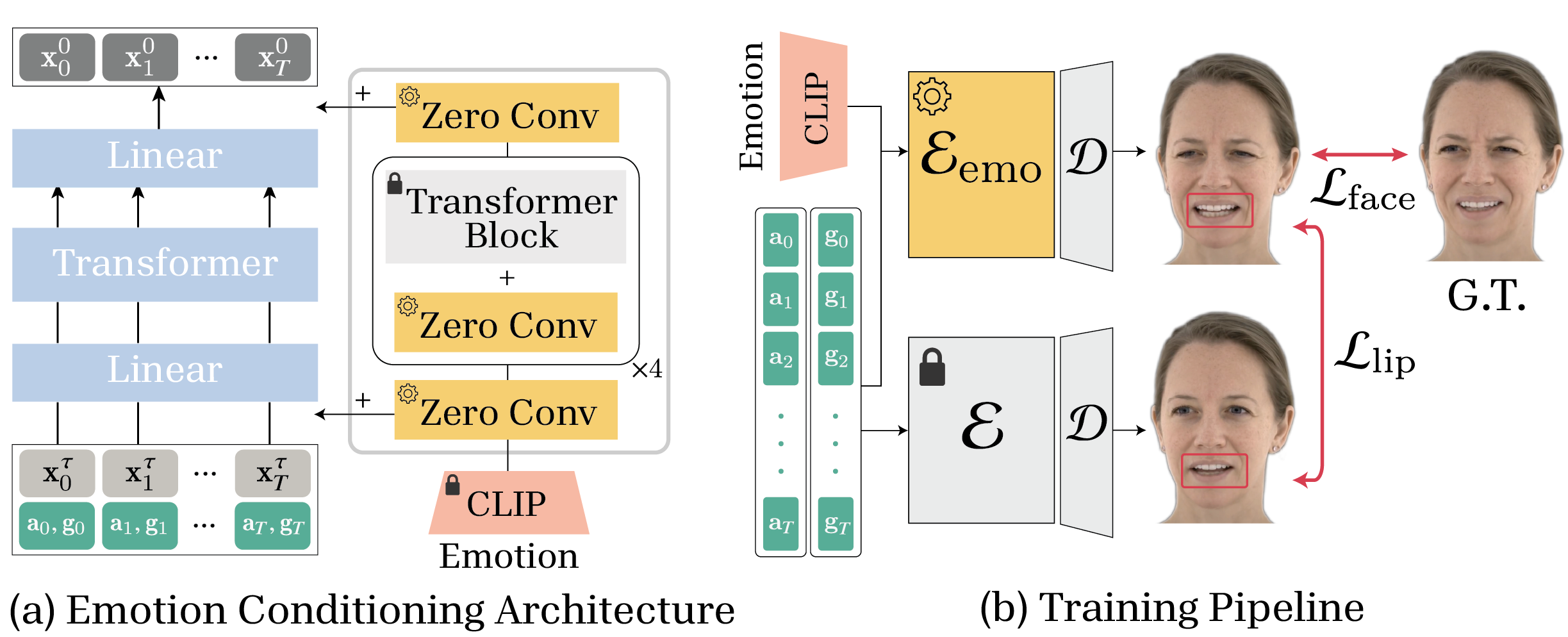
Figure 5: Emotion conditioning architecture (left) and training pipeline (right). Zero convolutional layers are added for conditioning and trained to preserve lip synchronization while infusing emotional context.
For sensor fusion, the architecture directly replaces gaze vectors with eye features extracted from head-mounted cameras in VR setups; this extensibility enables robust performance in practical wearable deployments.
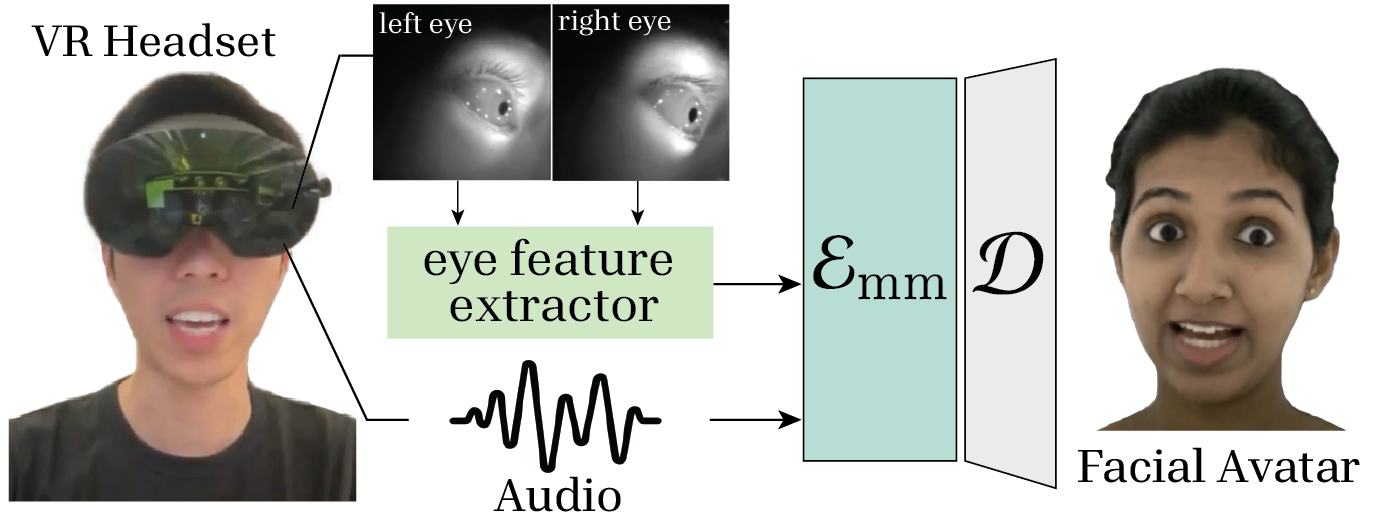
Figure 6: Pipeline for multimodal applications using a VR headset, with 2 HMC eye cameras and a microphone. Eye features are extracted and integrated with audio signals as model input.
Results and Evaluation
Quantitative results demonstrate that the system matches or exceeds the best offline baselines for animation accuracy—measured by Lip Vertex Error (LVE), Face Dynamics Deviation (FDD), and Lip Sync metrics—while operating at 100×−1000× lower latency.

Figure 7: Visual comparison with state-of-the-art baselines. Compared to baselines, the proposed method generates natural facial expressions with synchronized lip movements under tighter latency constraints.

Figure 8: Additional visual comparison with state-of-the-art baselines, showing fine-grained details like tongue and eyebrow motion.
Ablation studies reveal that geometry-based losses critically improve velocity and naturalness of facial expression dynamics, and that distillation combined with diffusion yields markedly superior expressivity over direct regression.
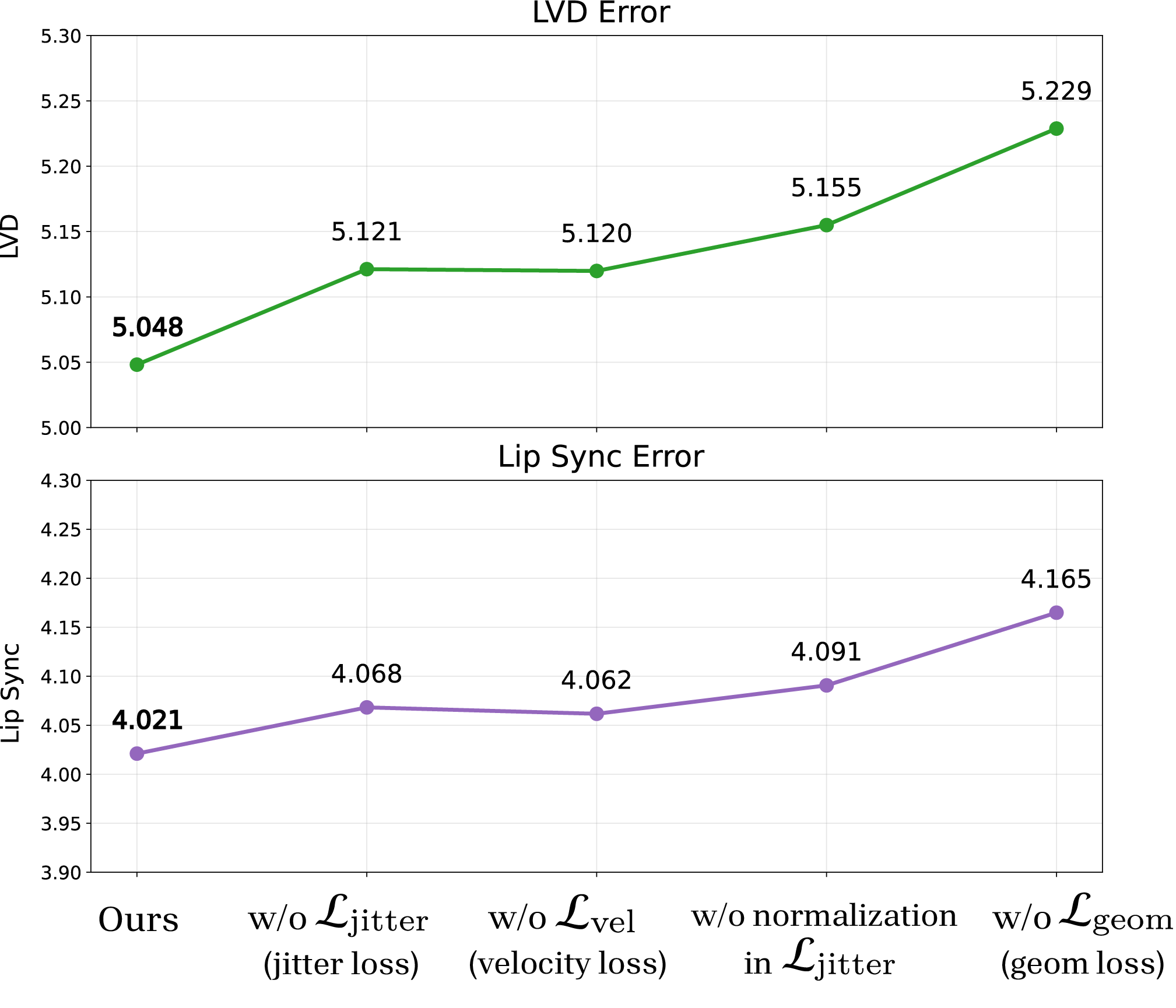
Figure 9: Ablation studies on velocity/jitter components of geometry loss; both improve motion realism, with jitter normalization essential for identity-agnostic accuracy.

Figure 10: Visual comparison with regression baseline for single-step generation. Distillation with diffusion produces more natural lip motions.
Emotion conditioning is shown to reliably modulate facial affect while preserving precise lip synchronization, outperforming direct backbone finetuning approaches.

Figure 11: Facial expression comparison with and without emotion conditioning. The emotion-conditioned model accurately reflects the specified emotional context.

Figure 12: Ablation of emotion conditioning design. Zero-initialized conditional layers enhance emotion alignment and lip fidelity versus direct finetuning.
Comparison against 2D-based approaches further highlights the advantages of the shared latent 3D representation, with substantially reduced temporal and geometric artifacts.
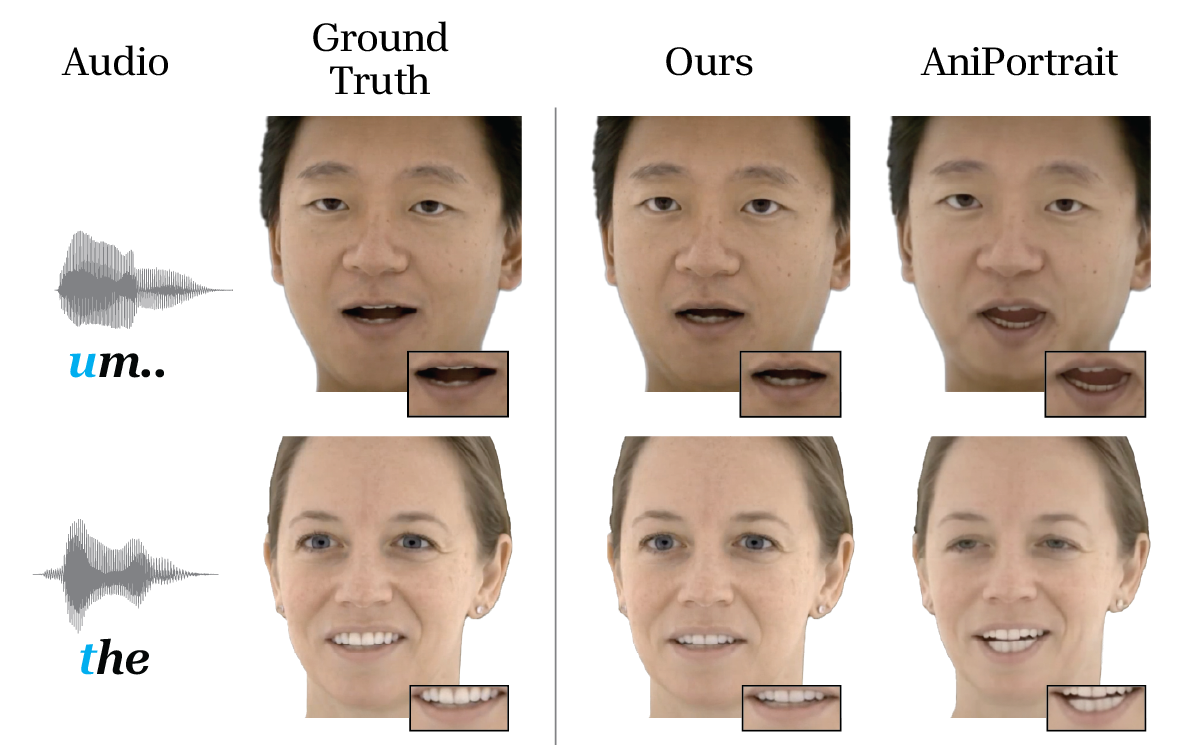
Figure 13: Visual comparison against 2D-based methods. The proposed method generates more plausible and temporally consistent facial avatar animations.
Practical Considerations and Limitations
- Computational Efficiency: The single-step pipeline supports real-time deployment (<15ms/frame) with single GPU, suitable for client-side VR applications.
- Universal Applicability: The encoder's shared latent code, learned on large multi-subject data, supports universal facial animation without personalization.
- Limitations: Minor jitter may persist in framewise sampling. Oral cavity and hair fidelity remain challenging for extreme geometry or occlusion.
- Scalability: Future work may extend to direct mobile deployment via quantization and integration of explicit head pose modeling.
Theoretical and Societal Implications
The introduction of a real-time multimodal diffusion pipeline with shared latent semantics paves the way for accessible social telepresence, scalable avatar systems, and enhanced user experience in VR/AR domains. It also necessitates careful attention to privacy, security, and misuse safeguards given the high-fidelity replication of personal appearance and affect.
Conclusion
This paper presents a robust, extensible pipeline for audio-driven, real-time, photorealistic 3D facial animation. Through innovations in diffusion architecture, causal audio encoding, loss design, and multimodal extension, it outperforms prior state-of-the-art models in both accuracy and latency, supporting universal application scenarios. The approach is directly applicable to future VR/AR systems and telepresence platforms, with clear avenues for further research in on-device optimization and multimodal expressivity.

