- The paper introduces ReT-2, a recurrent Transformer that dynamically fuses textual and visual features via layer-specific gating mechanisms.
- It employs layer pruning and token reduction to improve efficiency while maintaining robust semantic alignment and retrieval accuracy.
- Empirical evaluations show state-of-the-art performance on benchmarks like M-BEIR, demonstrating scalability for universal multimodal retrieval tasks.
Introduction and Motivation
The paper introduces ReT-2, a unified multimodal retrieval model designed to support queries and documents containing both text and images. The motivation stems from the limitations of prior vision-language retrieval systems, which typically restrict themselves to single-modality queries or documents and rely on final-layer features for representation. ReT-2 addresses these constraints by leveraging multi-layer representations and a recurrent Transformer architecture with LSTM-inspired gating mechanisms, enabling dynamic integration of information across layers and modalities. This design facilitates fine-grained semantic alignment and robust retrieval in highly compositional multimodal scenarios.
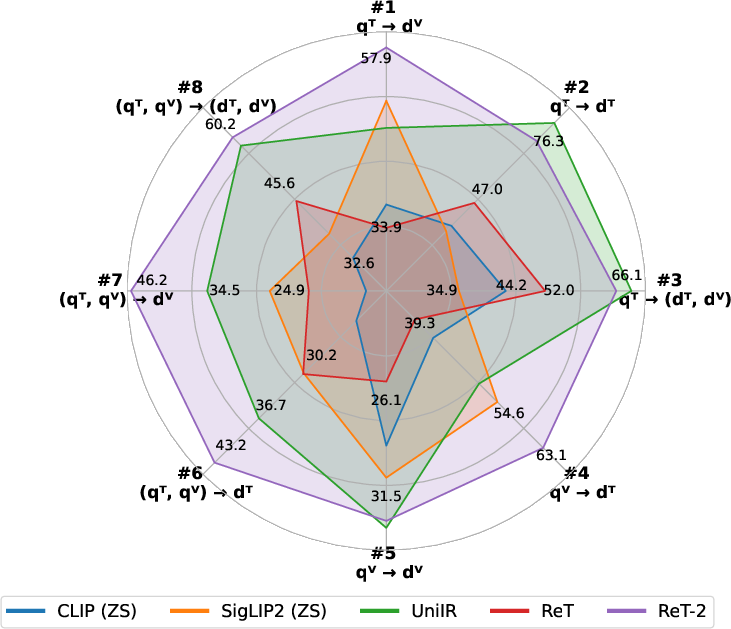
Figure 1: ReT-2 achieves superior average performance across M-BEIR tasks compared to previous methods, supporting diverse multimodal retrieval configurations.
Architectural Innovations
Recurrent Cell Design
The core of ReT-2 is a Transformer-based recurrent cell that fuses layer-specific visual and textual features. At each layer, the cell merges its hidden state with features from both modalities using cross-attention, followed by gated linear combinations modulated by learnable forget and input gates. This mechanism allows selective retention of information from shallower layers and dynamic modulation of unimodal feature flow, enhancing the model's ability to capture both low-level and high-level details.
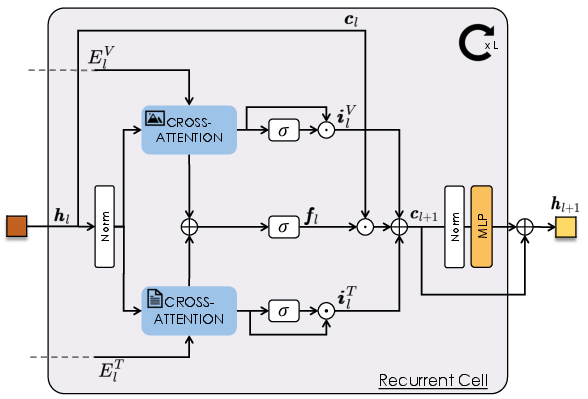
Figure 2: The recurrent cell integrates layer-specific textual and visual features into a matrix-form hidden state, enabling multi-layer fusion.
Layer Pruning and Token Reduction
To improve efficiency and robustness, ReT-2 prunes the number of layers processed by the recurrent cell, sampling three representative layers (early, middle, late) from each backbone. Additionally, the model reduces the number of input tokens from 32 to a single token per modality, addressing rank collapse observed in previous architectures and simplifying the contrastive objective.
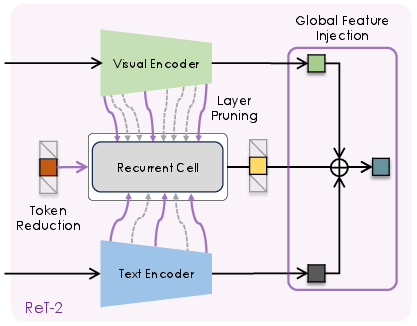
Figure 3: ReT-2 introduces token reduction, layer pruning, and global feature injection, differentiating it from the original ReT.
Global Feature Injection
ReT-2 augments the output of the recurrent cell with global features from the pooler tokens of the visual and textual backbones. This integration provides broader contextual information, further improving retrieval accuracy and robustness.
Training and Implementation Details
ReT-2 employs shared weights between query and document encoders, reducing model complexity and promoting consistent representation learning. Training utilizes the InfoNCE loss over the single fused token from both query and document sides. The model is compatible with various backbone architectures (CLIP, SigLIP2, OpenCLIP, ColBERTv2), and layer selection is standardized for architectural compatibility. Mixed precision training and gradient checkpointing are used for efficiency, with Faiss employed for fast retrieval during inference.
Empirical Evaluation
Multimodal Retrieval Benchmarks
ReT-2 is evaluated on the M2KR and M-BEIR benchmarks, encompassing a wide range of multimodal retrieval tasks and domains. Across all configurations, ReT-2 consistently outperforms prior methods, including FLMR, PreFLMR, UniIR, GENIUS, and MLLM-based retrievers. Notably, ReT-2 achieves state-of-the-art recall metrics, with substantial gains observed when backbones are unfrozen and scaled.
Ablation Studies
Ablation analyses demonstrate the effectiveness of each architectural modification. Token reduction and layer pruning yield efficiency gains without sacrificing performance, while global feature injection provides a +2.6 point improvement over the original ReT. Shared encoder weights further reduce overfitting, particularly on entity-centric datasets.
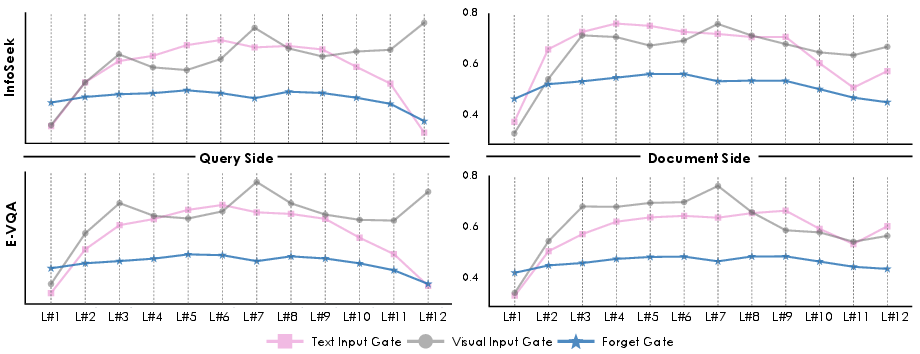
Figure 4: Gate activation analysis reveals the importance of selected layers for multimodal fusion, supporting the layer pruning strategy.
Computational Efficiency
ReT-2 offers significant improvements in inference speed and memory usage compared to fine-grained late-interaction models and MLLM-based retrievers. The use of a single token and pruned layers enables faster forward and retrieval times, making ReT-2 suitable for large-scale deployment.
Retrieval-Augmented Generation for VQA
ReT-2 is integrated into retrieval-augmented generation pipelines for knowledge-intensive visual question answering (VQA) tasks, such as Encyclopedic-VQA and InfoSeek. When paired with off-the-shelf MLLMs (LLaVA-MORE, Qwen2.5-VL), ReT-2 enables higher answer accuracy without task-specific fine-tuning, outperforming both general-purpose and task-specific retrievers.






Figure 5: Sample results for InfoSeek VQA, showing improved answer accuracy when Qwen2.5-VL is augmented with ReT-2-retrieved context.






Figure 6: Sample results for Encyclopedic-VQA, demonstrating ReT-2's ability to retrieve relevant multimodal documents for complex questions.
Theoretical and Practical Implications
ReT-2 demonstrates that multi-layer feature integration via recurrence and gating mechanisms is highly effective for universal multimodal retrieval. The model's architectural simplicity, efficiency, and robustness position it as a practical backbone for retrieval-augmented generation and other downstream multimodal tasks. The findings suggest that reliance on large MLLMs for retrieval can be mitigated by principled architectural design, enabling scalable and generalizable solutions.
Future Directions
Potential future developments include extending ReT-2 to additional modalities (audio, video), exploring adaptive layer selection strategies, and integrating more advanced gating mechanisms. The approach may also be adapted for real-time retrieval in interactive systems and further optimized for low-resource deployment.
Conclusion
ReT-2 establishes a new standard for universal multimodal retrieval by combining multi-layer feature fusion, recurrence, and gating within a unified Transformer framework. The model achieves strong empirical results across diverse benchmarks, offers significant efficiency gains, and enhances downstream performance in retrieval-augmented generation tasks. These contributions underscore the value of recurrent integration for scalable and robust multimodal retrieval systems.