- The paper addresses the KV cache memory bottleneck by proposing LESS, a method that synthesizes low-rank embeddings with sparse policies to retain essential information.
- LESS improves performance on tasks such as language modeling and summarization, reducing perplexity by over 20% and recovering more than 40% of Rouge-1 degradation.
- The method enhances inference speed by achieving up to 1.3x lower latency and 1.7x higher throughput compared to full KV cache implementations.
LESS: Efficient LLM Inference via KV Cache Compression
The paper "Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference" (2402.09398) addresses the memory bottleneck in LLM inference caused by the key-value (KV) cache. The authors propose LESS (Low-rank Embedding Sidekick with Sparse policy), a method that integrates a constant-sized low-rank cache with eviction-based sparse KV cache policies to retain information from discarded KV pairs. This approach aims to improve performance on tasks requiring recollection of previous tokens while maintaining efficiency.
Background and Motivation
The KV cache, which stores previous keys and values at each layer during decoding, significantly increases memory consumption. Sparse policies reduce the KV cache size by pruning less important KV pairs. However, these methods can lead to performance degradation in tasks that require recalling a majority of previous tokens. The paper identifies this issue and motivates the need for a more effective KV cache policy that minimizes performance degradation, scales slowly, and is easy to integrate into existing LLMs.
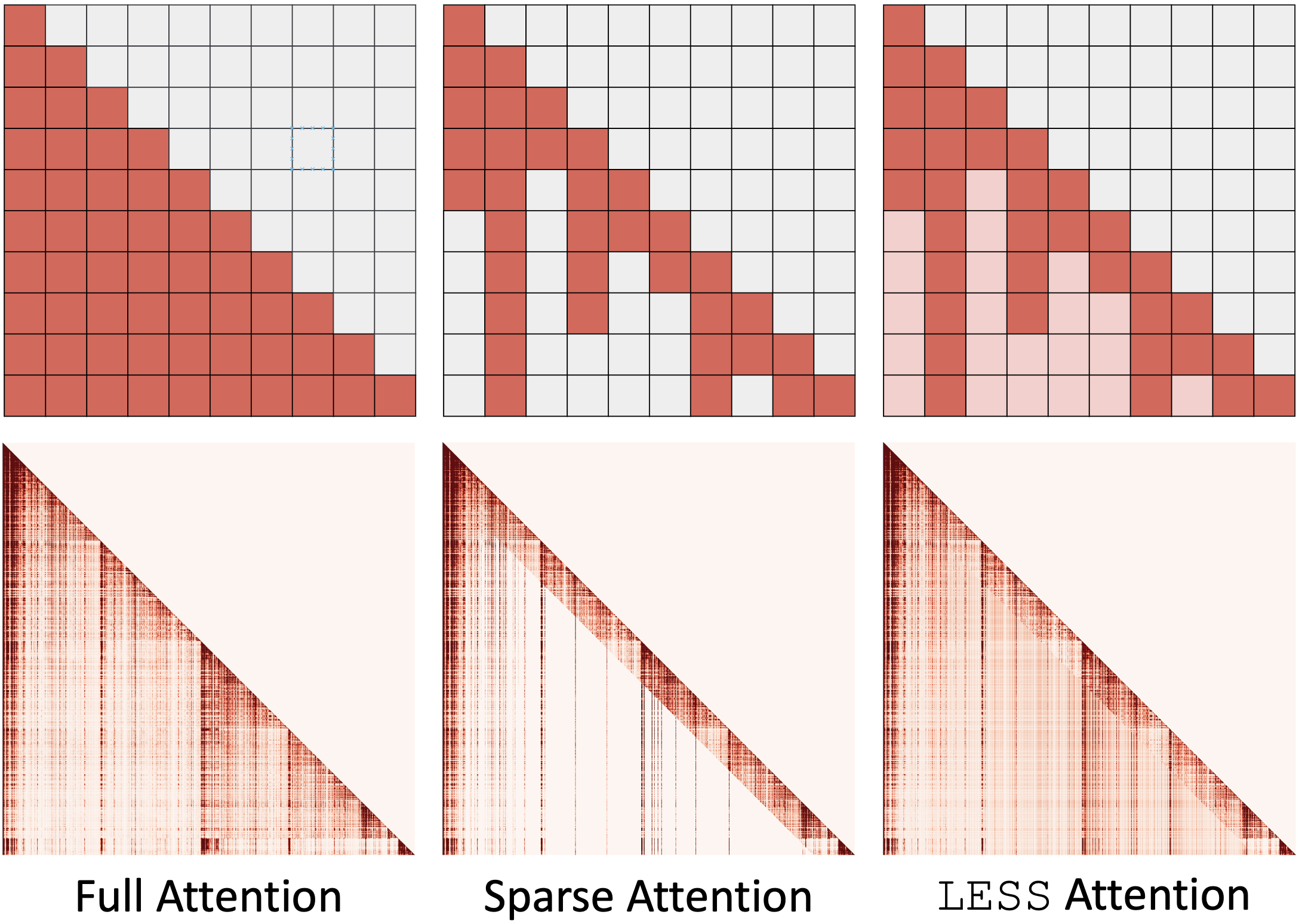
Figure 1: Toy (top row) and Llama 2 7B (bottom row) example decoder attention maps with $\hho$ as the underlying sparse policy.
The authors observe that the residual between full and sparse attention outputs is low-rank, motivating the use of low-rank methods to approximate these residuals for efficient caching. LESS leverages this observation by learning the residual between the original attention output and the output approximated by a sparse policy, thereby allowing queries to access previously omitted regions in attention maps (Figure 1).
LESS Method
LESS synthesizes sparse KV policies with low-rank states to improve performance. The method adds a constant-sized cache that does not scale with the sequence length. The kernels are defined as:
ϕ(q)=∣σϕ(σϕ(qWϕ,1)Wϕ,2)∣
ψ(k)=∣σψ(σψ(kWψ,1)Wψ,2)Wψ,3∣
where $\sigma_{\bcdot}$ are activation functions and $W_{\bcdot, i}$ are weight matrices.
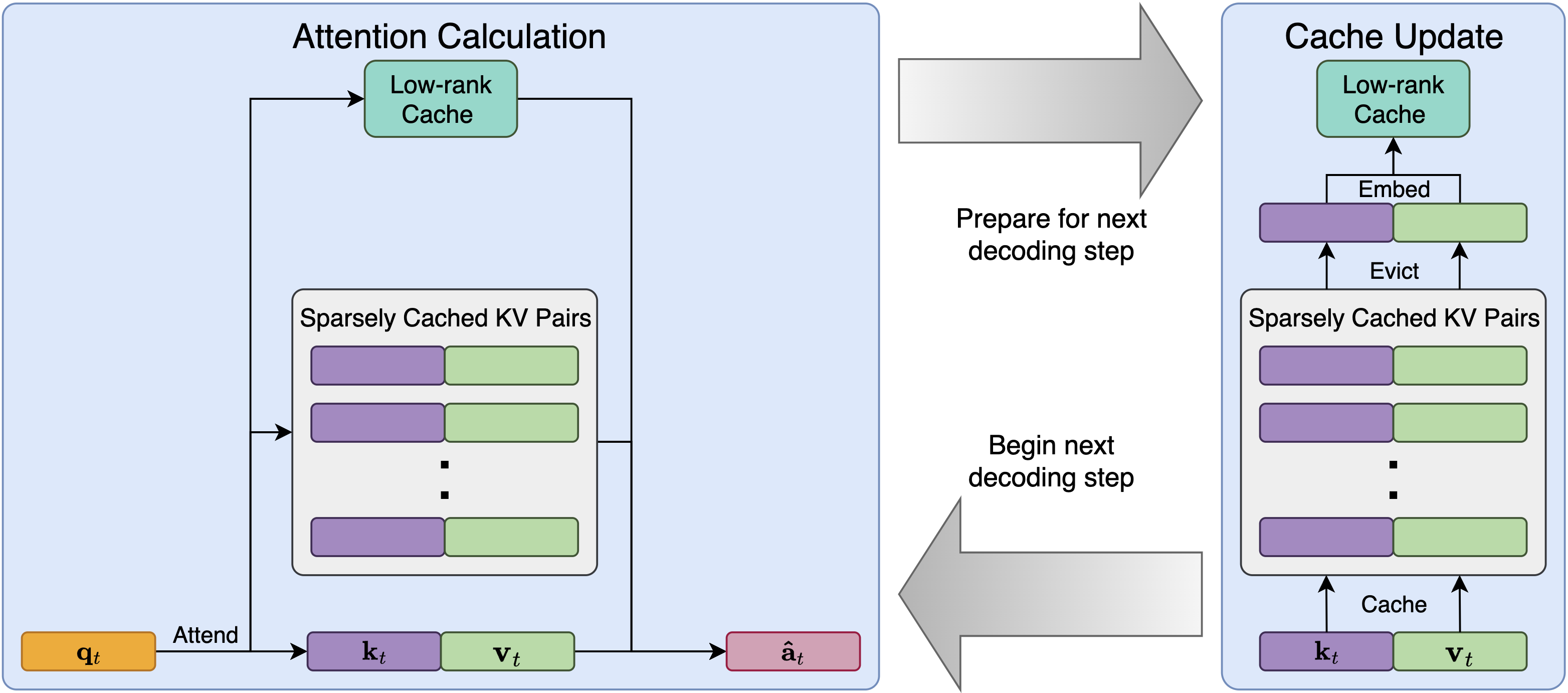
Figure 2: LESS algorithm during inference.
The attention calculation procedure involves computing an approximation of the original attention using cached keys and values from the sparse policy, as well as the low-rank cache (Figure 2). The cache is updated by embedding information from discarded KV pairs into the low-rank cache using recursive updates.
Implementation Details
The kernel functions ϕ and ψ are trained independently at each layer to minimize the ℓ2 distance to the output projection of the original attention layer. All weights except those in ϕ and ψ are frozen. The paper emphasizes that kernel initialization is critical, using learnable scalars initialized to a small value to allow the sparse policy to act as a warm start. An efficient implementation is developed to enhance throughput and reduce latency, using fused linear kernels and adapting an existing implementation for sparse caching.
Experimental Results
The paper evaluates LESS on Llama 2 and Falcon models with different sparse policies and sparsity levels. The experiments demonstrate that LESS achieves performance improvements in language modeling, classification, and summarization tasks.
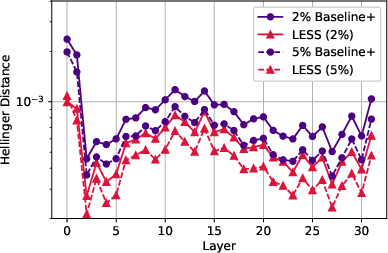
Figure 3: Layer-wise Llama 2 7B mean Hellinger distance from original attention probabilities, aggregated across WikiText evaluation samples.
Specifically, LESS reduces word perplexities on WikiText and PG-19 by over 20% from the sparse policy alone, and it recovers more than 40% of the Rouge-1 degradation caused by a sparse policy on the CNN/DailyMail dataset. The paper also reports latency reductions of up to 1.3x and throughput increases of up to 1.7x compared to full caching. Further analysis shows that LESS accurately replicates original attention probability distributions (Figure 3) and performs well with longer sequences.
Conclusion
The paper presents LESS as an effective approach to mitigate the KV cache bottleneck by synthesizing sparse KV cache algorithms with low-rank states. The method demonstrates significant performance gains while maintaining efficiency and being easy to train and deploy. Future work includes improving kernel design and investigating the residual of LESS.