- The paper introduces Q-Filters, a training-free method that uses SVD-based analysis of Query vectors to filter and compress KV caches in autoregressive models.
- It achieves up to ×32 compression while maintaining lower perplexity in long-context language modeling without needing model retraining.
- The method offers a context-agnostic approach, compatible with efficient attention mechanisms like FlashAttention, and scales across diverse benchmarks.
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Introduction
The paper "Q-Filters: Leveraging Query-Key Geometry for Efficient KV Cache Compression" (2503.02812) addresses the challenge of memory bottlenecks in autoregressive LLMs, where the Key-Value (KV) Cache grows with increasing model sizes and context lengths. As LLMs evolve to handle longer contexts, the KV Cache poses a significant hurdle due to its memory demands, slowing down inference times. Q-Filters is proposed as a training-free method to compress the KV Cache without requiring access to attention weights, making it compatible with efficient attention algorithms like FlashAttention.
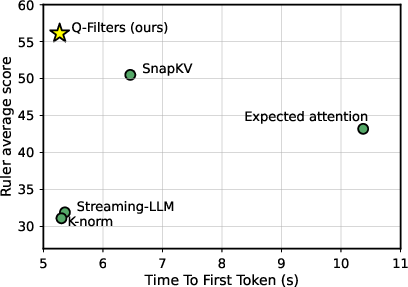
Figure 1: Accuracy vs Time to First Token (TTFT) tradeoff for Llama-3.1-70B-Instruct, measured on the Ruler dataset with ×8 compression.
Methodology
Q-Filters work by exploring the geometrical properties of Query (Q) and Key (K) vectors. The authors identify that the main direction in the hidden space, spanned by the principal eigenvector of Q, can efficiently estimate the importance of Key-Value pairs. This direction is context-agnostic and therefore allows for a robust filtering approach across different tasks and datasets.
In practice, Q-Filters uses Singular Value Decomposition (SVD) of Query vectors from a calibration dataset to determine principal directions, which serve as the filters. During inference, Key vectors are projected onto these predefined directions to evaluate their relevance, maintaining compatibility with models and attention mechanisms that do not provide direct access to attention weights.
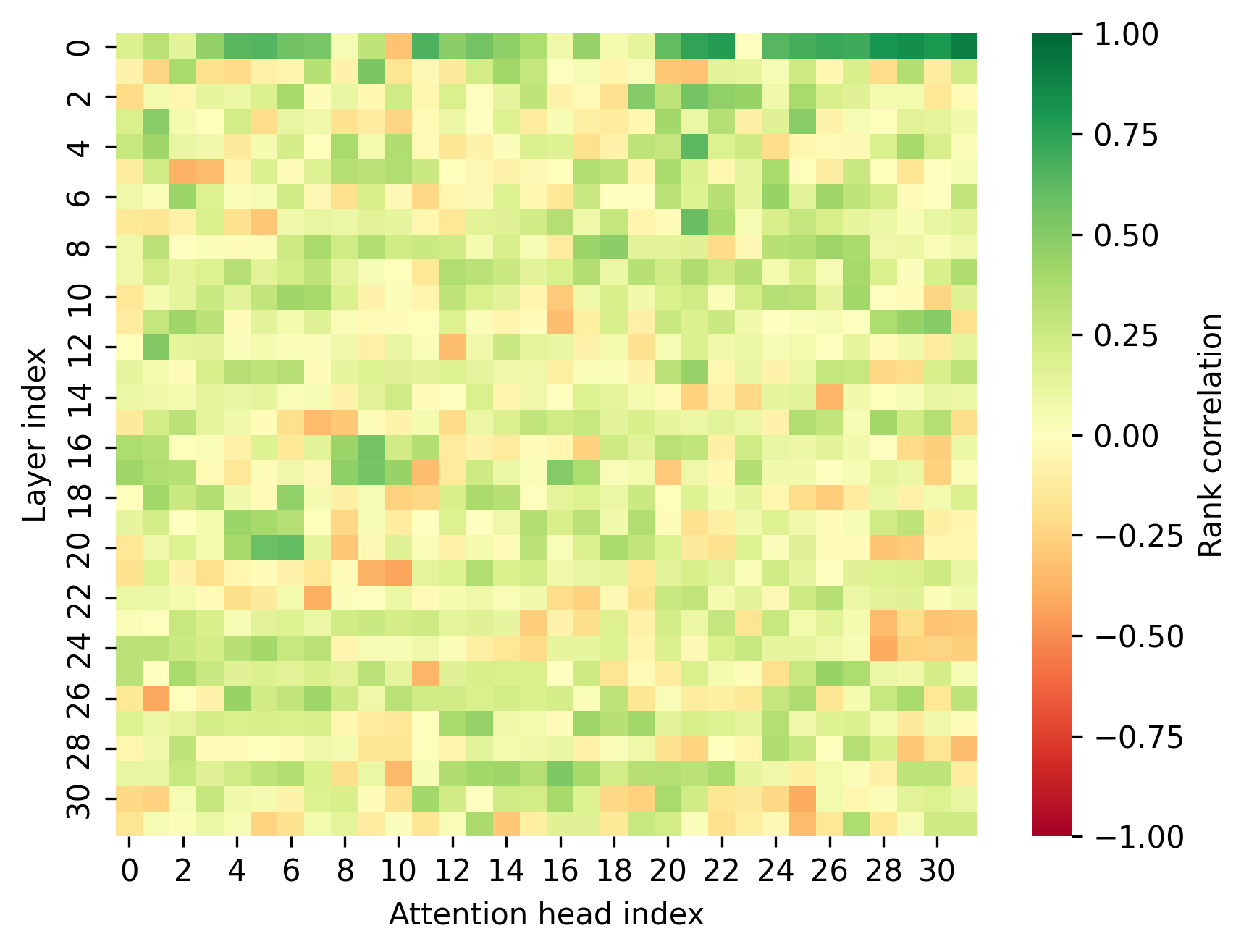
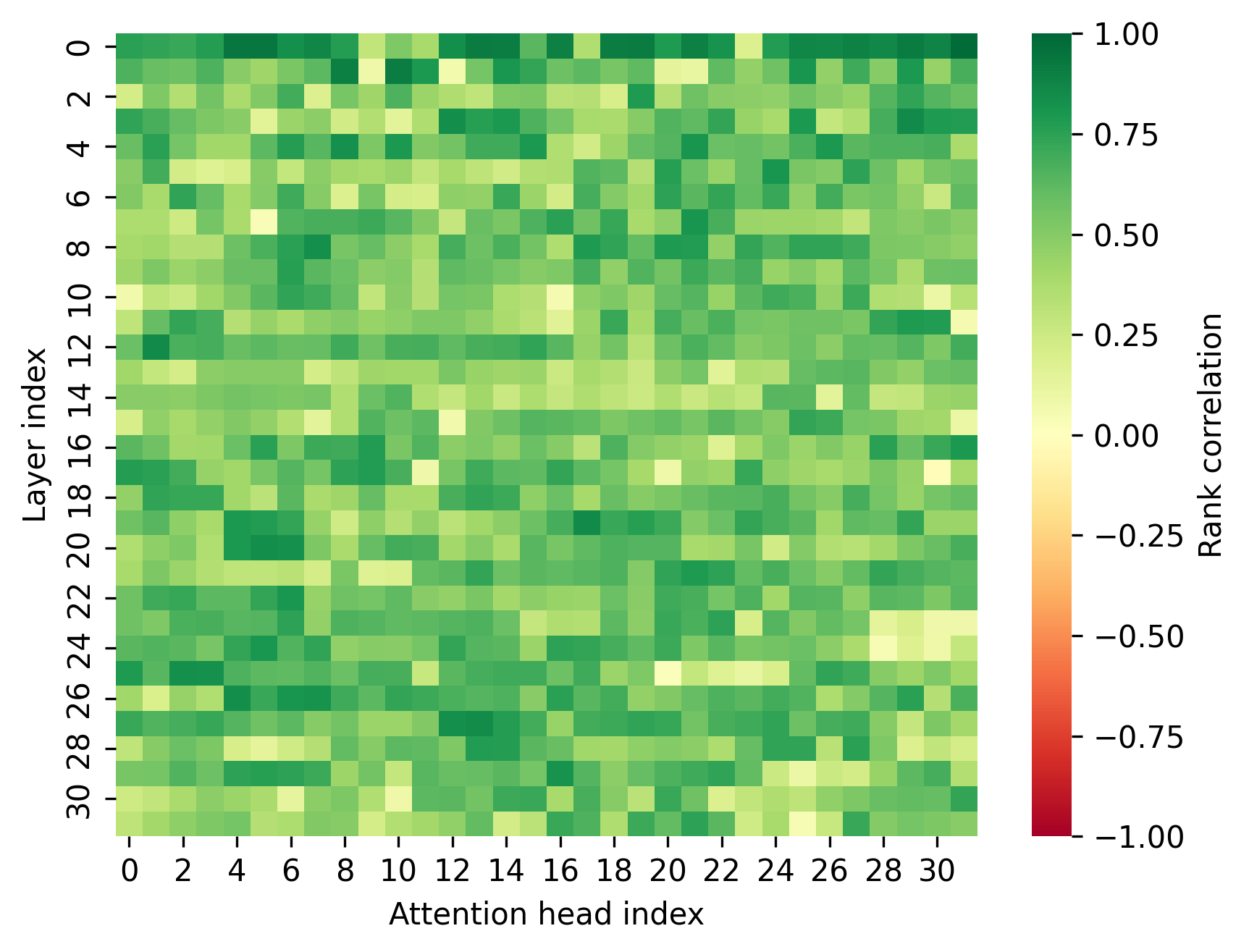
Figure 2: Spearman rank correlation between KV compression scoring metrics and the observed attention Sh for Llama-3.2-1B, for K-norm (top) and Q-Filters (bottom).
Experimental Results
The paper demonstrates the effectiveness of Q-Filters across several benchmarks, including language modeling on the Pile dataset, needle-in-a-haystack retrieval tasks, and the Ruler dataset for long context modeling. Notably, Q-Filters achieved competitive results with up to ×32 compression levels, reducing perplexity drops significantly compared to alternatives such as Streaming-LLM.
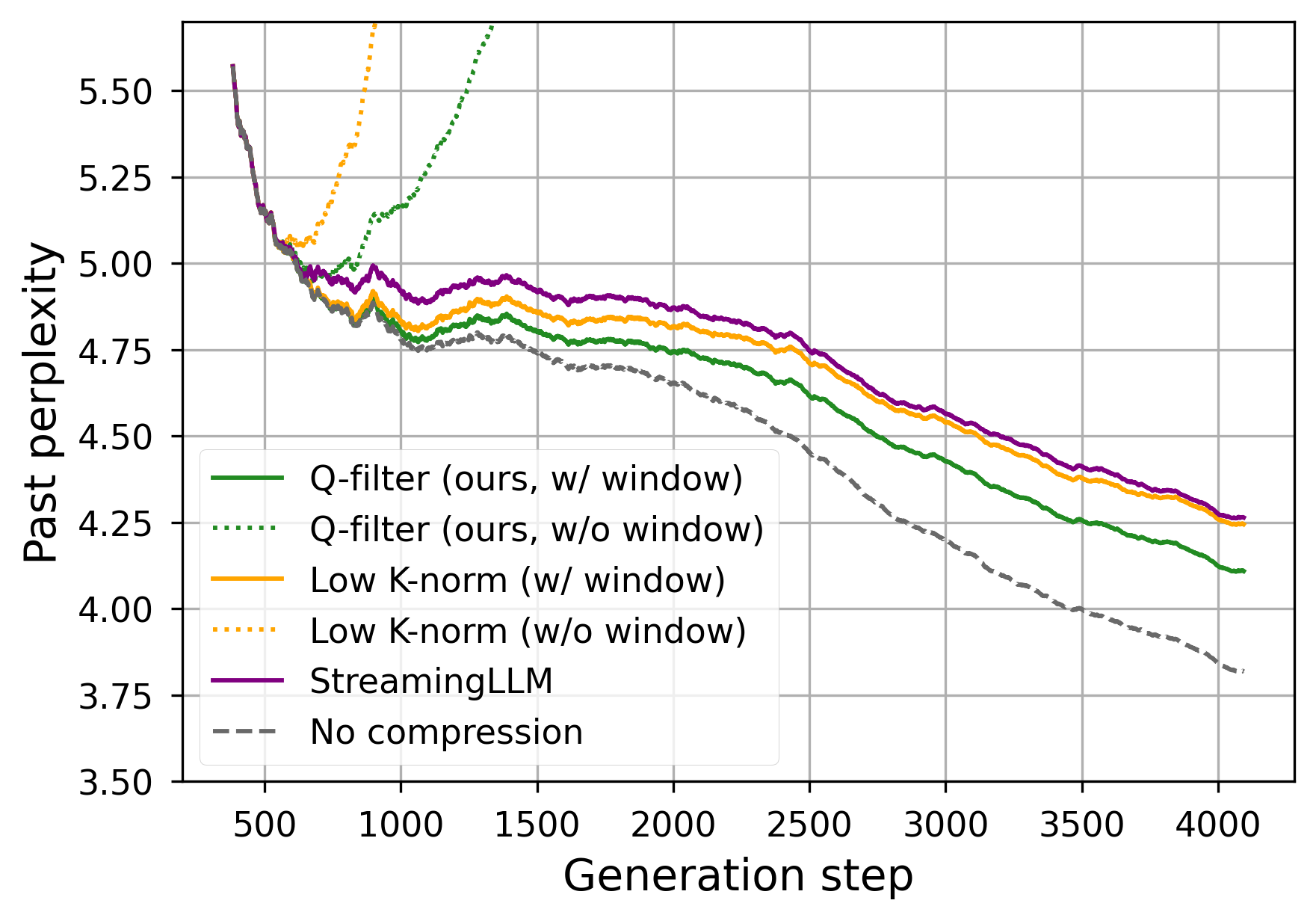
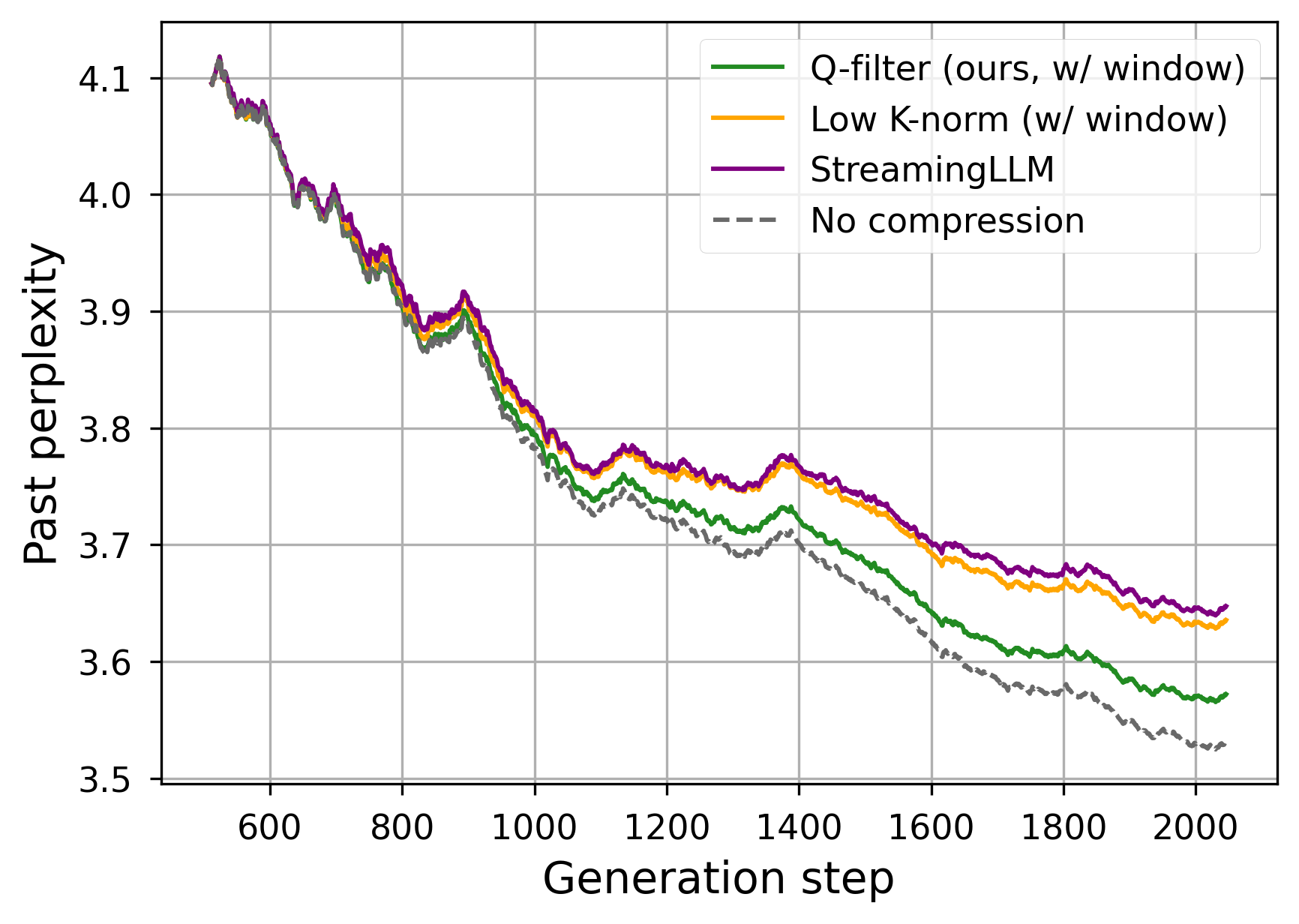
Figure 3: Generation performance for a KV Cache size limited to 512 items for Llama-3.1-8B (top) and Llama-3.1-70B (bottom).
In memory-constrained scenarios, Q-Filters consistently results in lower perplexity, indicating better retention of crucial context information. The approach excels particularly in scenarios requiring efficient query and retrieval across very long sequences due to its context-agnostic design.
Discussion
Q-Filters offer a compelling balance between computational efficiency and performance, highlighting its utility for real-time applications requiring rapid inference along extensive prompts. The method's ability to operate without retraining the model or accessing specific attention mechanisms positions it as a pivotal contribution to KV Cache compression.
While the primary focus is on geometric considerations in Query-Key relations, future developments may explore adaptive Q-Filters generation and integration with emerging attention acceleration techniques. The scalability and broad applicability of Q-Filters suggest potential paths for deployment in commercial settings that demand versatile model efficiency without sacrificing accuracy.
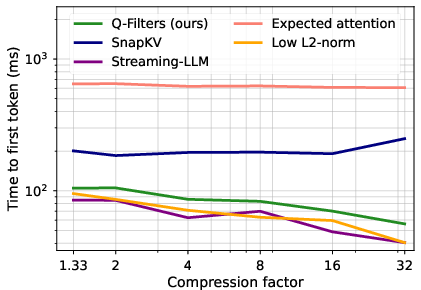
Figure 4: First token latency across KV Cache compression methods of Llama-3.2-8B with a length of 64k prompt.
Conclusion
The introduction of Q-Filters marks a significant advancement in addressing the challenges posed by expanding context lengths in autoregressive models. By leveraging the geometric properties of Query and Key vectors, Q-Filters provide a context-agnostic, training-free solution for efficient KV Cache compression. This approach not only reduces memory footprint but also enhances inference speed and accuracy across diverse applications, contributing notably to the practical scalability of long-context LLMs.

