OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
Abstract: Recent advances in video insertion based on diffusion models are impressive. However, existing methods rely on complex control signals but struggle with subject consistency, limiting their practical applicability. In this paper, we focus on the task of Mask-free Video Insertion and aim to resolve three key challenges: data scarcity, subject-scene equilibrium, and insertion harmonization. To address the data scarcity, we propose a new data pipeline InsertPipe, constructing diverse cross-pair data automatically. Building upon our data pipeline, we develop OmniInsert, a novel unified framework for mask-free video insertion from both single and multiple subject references. Specifically, to maintain subject-scene equilibrium, we introduce a simple yet effective Condition-Specific Feature Injection mechanism to distinctly inject multi-source conditions and propose a novel Progressive Training strategy that enables the model to balance feature injection from subjects and source video. Meanwhile, we design the Subject-Focused Loss to improve the detailed appearance of the subjects. To further enhance insertion harmonization, we propose an Insertive Preference Optimization methodology to optimize the model by simulating human preferences, and incorporate a Context-Aware Rephraser module during reference to seamlessly integrate the subject into the original scenes. To address the lack of a benchmark for the field, we introduce InsertBench, a comprehensive benchmark comprising diverse scenes with meticulously selected subjects. Evaluation on InsertBench indicates OmniInsert outperforms state-of-the-art closed-source commercial solutions. The code will be released.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to add a person or object (called a “subject”) into an existing video without asking the user to draw masks or provide complicated controls. The method is called OmniInsert. It uses powerful AI video models (based on “diffusion transformers”) to place the subject into the scene so it looks natural, stays consistent across frames, and matches the user’s prompt.
What questions does the paper try to answer?
In simple terms, the paper tackles three big problems:
- Data scarcity: How can we train a model to insert subjects into videos when there aren’t many “before and after” training examples?
- Subject–scene balance: How do we keep the inserted subject looking correct while leaving the rest of the video unchanged?
- Insertion harmonization: How can the subject’s position, motion, and interactions in the scene look realistic (not awkward or “copy-paste”)?
How did the researchers do it?
To solve these problems, the authors designed both a data-building pipeline and a new model with a training plan that teaches it how to insert subjects well.
Building training data (InsertPipe)
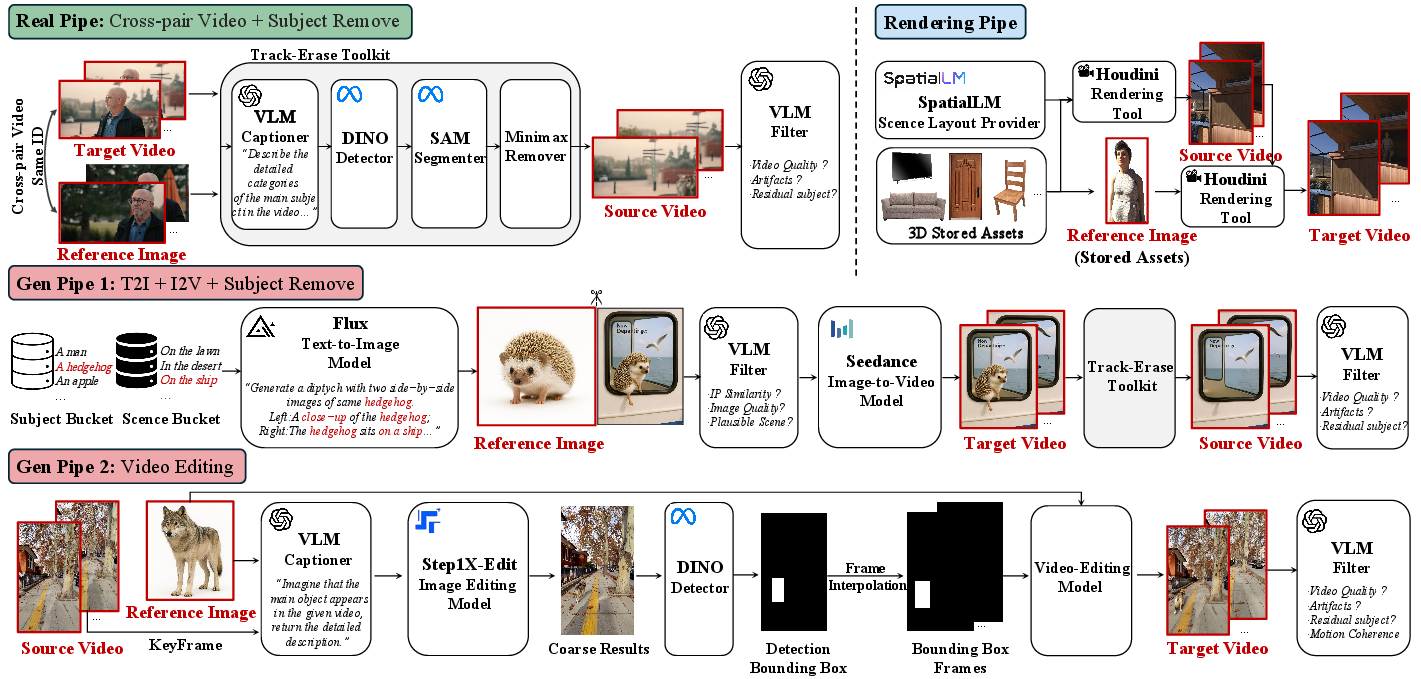
Because real “before and after” video pairs are rare, they built their own diverse dataset using three routes:
- RealCapture Pipe: They take real videos, detect and track the main subject, remove that subject to create a “source video” (an empty scene), and pair it with the original clip (the “target video”) and a matching subject from another video. This prevents simple copy-paste from the same video.
- SynthGen Pipe: They use AI to generate many different subjects and scenes. Then they make target videos with the subject interacting naturally, and create source videos by removing the subject. They also use AI tools to check that the pairs look consistent and realistic.
- SimInteract Pipe: For complex interactions (like someone waving behind a slowly opening door), they use a 3D rendering engine with prebuilt assets and motions to make clean source/target pairs with realistic camera views.
Think of InsertPipe like a factory that creates many examples of “video without subject” + “the wanted subject” + “video with subject inserted” to teach the model.
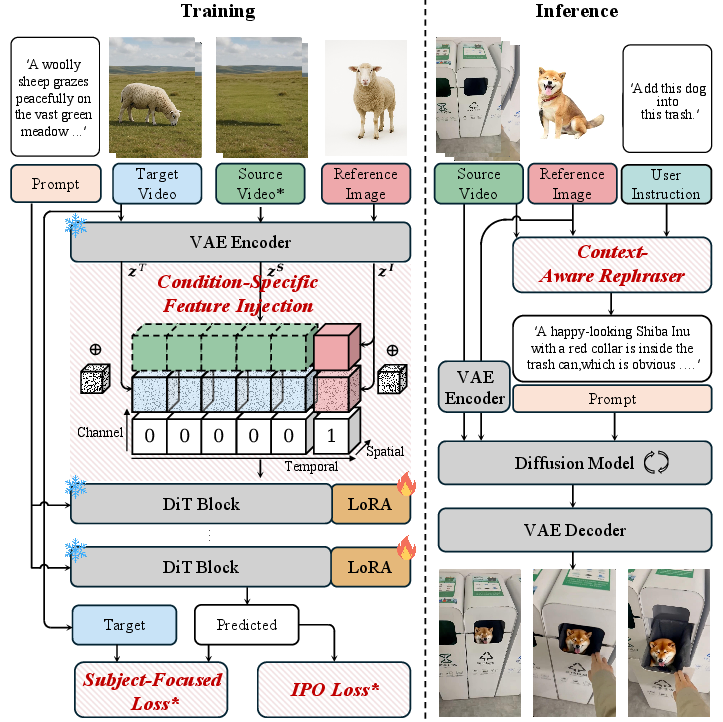
The model (OmniInsert with Condition-Specific Feature Injection)
OmniInsert is built on a diffusion transformer, a type of AI that learns to turn noisy video into clear video step by step. The key idea is how it feeds different kinds of information into the model:
- Background video condition (the source video): These features are injected in a way that lines up well with the video’s spatial layout, so the scene stays unchanged where it shouldn’t be edited.
- Subject condition (the person/object to insert): These features are injected across time so the subject looks consistent and moves naturally across frames.
You can think of it like having two dedicated lanes:
- One lane for the background video so the original scene stays stable.
- One lane for the subject so their appearance and motion are consistent.
This “Condition-Specific Feature Injection” lets the model fuse the two lanes without confusion or heavy computation.
Training strategy (Progressive Training, Subject-Focused Loss, and Preference Optimization)
Teaching the model to both preserve the background and insert the subject is hard because preserving the background is easy and can dominate learning. The authors train the model in four steps:
- Phase 1: Only learn subject insertion (ignore the background video), so the model gets good at recognizing and rendering the subject.
- Phase 2: Add the background video, so the model learns to align the subject with the scene.
- Phase 3: Fine-tune with high-quality portrait and synthetic rendering data to improve identity consistency and handle complex scenes.
- Phase 4: Preference Optimization (IPO): Use small human-labeled comparisons (better vs. worse insertions) to nudge the model toward realistic poses and fewer visual artifacts.
They also use a Subject-Focused Loss, which puts extra attention on the subject areas during training. That helps keep small or detailed subjects from getting blurry or changing appearance across frames.
Making prompts smarter (Context-Aware Rephraser)
At inference time (when users run the model), a helper module called the Context-Aware Rephraser reads the scene and the subject, then rewrites the user’s prompt with helpful details. This can include object textures, scene layout, and interaction hints (like “stand behind the counter” or “keep the same lighting”). The goal is to produce instructions that lead to more natural, coherent results.
A fair way to test (InsertBench)
Since there was no standard test set for this task, they created InsertBench: a collection of 120 short videos covering many scene types (indoors, nature, wearable cameras, animated scenes). Each video comes with carefully chosen subjects and a prompt, so researchers can compare methods fairly.
What did they find and why does it matter?
The authors tested OmniInsert against strong commercial tools and found:
- Better subject consistency and identity: The inserted subject looks more like the reference image across frames.
- Better text alignment: The video follows the user’s prompt more closely.
- High video quality: The motion and visuals are stable and pleasant.
In user studies, people preferred OmniInsert’s results much more often, especially for consistency, alignment with the prompt, and overall realism.
Why this matters:
- Mask-free means less work for users—no need to draw where to insert or carefully control motion with extra signals.
- Consistency and harmonization mean results look like they belong in the scene, which is crucial for filmmakers, advertisers, and creators.
- The method supports multiple subjects and complex scenes, expanding creative possibilities.
Why is this important?
OmniInsert moves academic research closer to production-ready video editing:
- It shows that careful data building, smart feature injection, and staged training can beat even strong commercial baselines.
- InsertPipe and InsertBench will help future researchers train and test new methods.
- The approach could power apps where users simply pick a subject, choose a video, and type a prompt—then get a realistic, coherent result without extra masks or controls.
In short, this work makes it easier and more reliable to insert anything into any video so it looks natural, consistent, and aligned with what the user wants.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single consolidated list of concrete knowledge gaps, limitations, and open research questions left open by the paper. Each point is written to be actionable for future work.
- Data transparency and reproducibility: The RealCapture Pipe relies on proprietary videos and multiple closed-source components (e.g., GPT-4/VLMs, commercial inpainting), making the full data construction pipeline hard to reproduce and audit. Clear release plans, licensing, and recipes for open-source replicas are not specified.
- Dataset bias and coverage: The composition and statistics of the InsertPipe outputs (category distributions, motion types, lighting/weather, camera motion, occlusions, long-tail objects) are not quantified, leaving potential biases and coverage gaps uncharacterized.
- Ground-truth validity of “source” via erasing: Creating “source videos” by erasing subjects may introduce artifacts and unrealistic priors that bias training and evaluation; there is no analysis of how these artifacts affect model learning or outcomes.
- Segmentation/Mask reliability: Subject-Focused Loss uses downsampled masks derived from tracking, but the robustness of training to mask errors, jitter, or leakage is not analyzed; no sensitivity study to segmentation/tracking quality (e.g., SAM2 failure cases).
- Domain gap from synthetic/rendered data: The impact of SynthGen/SimInteract synthetic data on real-world performance is not dissected; there is no ablation on ratios of real vs. synthetic data or cross-domain generalization robustness.
- Limited benchmark scale: InsertBench contains 120 five-second clips at 480p; scalability to longer durations, higher resolutions (e.g., 1080p/4K), and more complex scenes (e.g., crowded urban environments) is untested.
- Benchmark curation and licensing: The paper does not detail InsertBench’s licensing, subject consent processes, IP considerations, and whether benchmarks include sensitive identities (e.g., celebrities).
- Evaluation metrics for background preservation: There is no region-specific metric explicitly measuring invariance of unedited regions (e.g., masked reconstruction error); current metrics (e.g., VBench “Consistency”) may not isolate background fidelity.
- Objective measures of physical plausibility: Improvements in “insertion harmonization” (e.g., contact, collision avoidance, foot/ground alignment) are not measured with physics/contact metrics or geometry-aware evaluations.
- Multi-subject evaluation: While the method supports multiple references, there is no quantitative benchmark or study focusing on multi-subject cases (e.g., identity disambiguation, inter-subject occlusions, relative scaling).
- Occlusion and interaction modeling: Handling heavy occlusions, complex subject–scene interactions (hand–object contact, self-occlusions, moving obstacles) is not systematically evaluated or measured.
- Motion grounding and scene dynamics: The approach does not explicitly model scene dynamics (e.g., optical flow, physics engines) for the inserted subject; how motion is synchronized with camera motion and scene context is not formally evaluated.
- CAR (Context-Aware Rephraser) failure modes: The method depends on VLM scene understanding; the effects of VLM hallucinations, mislabeling, or misinterpreted context on insertion quality and user intent drift are not studied.
- User intent fidelity under CAR: CAR rewrites prompts; no protocol ensures that the enriched prompt preserves the user’s original intent or offers controllable degrees of rephrasing.
- IPO (preference optimization) details and stability: The definition of probabilities/log-likelihoods for diffusion outputs and the training stability of DPO-like losses in the video-diffusion setting are not fully specified; reproducible implementation details are missing.
- Preference data quality: IPO uses only ~500 preference pairs without reporting inter-annotator agreement, annotation instructions, or category/scene balance; robustness to noisy preferences is unknown.
- Overfitting/over-optimization risk from IPO: There is no study of preference overfitting (e.g., distribution shift after IPO or degradation on unseen domains), nor mechanisms to prevent preference drift.
- CFI design choices vs. alternatives: Condition-Specific Feature Injection (channel-concat for video, temporal-concat for subjects) is not compared against other injection strategies (e.g., cross-attention, FiLM/adapter modulation, gated fusion, key–value mixing), leaving the optimality of the design untested.
- Guidance scale sensitivity: The joint classifier-free guidance scales (S1, S2, S3) are fixed; there is no sensitivity analysis, auto-tuning strategy, or per-scenario adaptation study.
- Computational efficiency and scaling: Memory/latency impacts of concatenating conditions (especially with multiple subjects) and the added forward passes for multi-branch guidance are not reported; no throughput or VRAM scaling curves are provided.
- Robustness to small or off-frame subjects: While SL targets small subjects, there is no dedicated stress test for tiny, partially visible, or fast-moving subjects, nor quantitative metrics for such cases.
- Long video temporal consistency: The method is evaluated on ~5 s clips; behavior on long sequences (e.g., minutes), temporal drift control, and identity consistency over long horizons remain open.
- Identity fidelity across poses/views: There is no analysis of identity preservation under extreme poses, lighting variations, or view changes; FaceSim advantages and trade-offs vs. CLIP/DINO are not deeply examined.
- Multi-language and domain instructions: CAR and text alignment are evaluated in English; cross-lingual prompt support and alignment quality in multilingual settings are not addressed.
- Safety and ethical safeguards: The paper does not propose watermarking, provenance, or misuse detection for identity insertion, nor consent verification or policy controls for deepfake risks.
- Fairness and representation: Biases in subject demographics, clothing/culture, and scene geographies are not audited; no disparate performance analysis across groups is provided.
- Training hyperparameters: Key training choices (e.g., λ1, λ2 for loss weighting, data sampling strategies across phases, dataset sizes per phase) are not fully specified, limiting reproducibility and principled tuning.
- Failure case taxonomy: The paper does not include a systematic categorization of failure modes (e.g., identity drift, scale mismatch, shadow mismatch, lighting color cast mismatch) to guide targeted improvements.
- Lighting/shadows/color harmonization: There is no explicit module or evaluation for photometric consistency (lighting direction, shadow casting, color grading) between inserted subjects and scene backgrounds.
- Camera motion and rolling shutter effects: Robustness to fast camera motion, zooms, rolling shutter distortions, and motion blur is not separately evaluated or stress-tested.
- Compatibility with different base models: Generalization of CFI/PT/SL/IPO/CAR to non-DiT backbones, other noise schedules (e.g., EDM/SDE), or non-flow-matching training is not explored.
- Data pipeline quality controls: VLM-based filtering and thresholds for acceptance/rejection in InsertPipe are not quantified; ablations on filter strictness vs. downstream quality are absent.
- Subject matching for non-human categories: Cross-video subject pairing relies on CLIP and face embeddings; how well it works for non-human, texture-less, or deformable categories (animals, plush toys, tools) is not evaluated.
- Intellectual property of subjects: The pipeline does not discuss mechanisms to avoid copying trademarked characters or copyrighted appearances in synthetic/reference data; legal risk management is unaddressed.
Practical Applications
Practical Applications of “OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models”
The paper introduces OmniInsert, a unified, mask-free video insertion framework powered by diffusion transformers, alongside the InsertPipe data curation pipeline and the InsertBench benchmark. Below are concrete, sector-linked applications, categorized by readiness and noting assumptions/dependencies that affect feasibility.
Immediate Applications
- Media & Entertainment (Industry): rapid, cost-efficient video compositing for post-production
- Use case: Insert actors, extras, creatures, or props into shots without rotoscoping/masks; previsualization for storyboards; continuity fixes and background preservation.
- Tools/products/workflows: OmniInsert plug-in for NLE/VFX tools (e.g., Adobe After Effects, Premiere, DaVinci Resolve), batch-shot pipeline with CAR for auto-prompting, LoRA adapters for show-specific styles.
- Assumptions/dependencies: Licensed subject references; GPU/cloud inference (50-step Euler, 480p baseline); scene-aware prompting via VLM; watermark/provenance for edited shots.
- Advertising & Product Placement (Industry): dynamic brand insertion
- Use case: Insert logos, products, or mascots into catalog videos at scale; A/B test variations; localize campaigns.
- Tools/products/workflows: AdOps API with CFI for multi-condition control, InsertBench-driven QA, CAR-guided prompt templates (placement, size, occlusion).
- Assumptions/dependencies: Brand safety policies; scene-fit validation via VLM; disclosure/watermarking; performance monitoring; consistent identity preservation under SL.
- Social Media & Creator Tools (Daily Life/Industry): accessible video remixing
- Use case: Creators insert themselves, friends, or virtual characters into trending clips; collaborative content; fan edits.
- Tools/products/workflows: Mobile app integration (e.g., CapCut/TikTok), simplified UI with CAR for novice-friendly prompts, cloud-offloaded inference.
- Assumptions/dependencies: Network bandwidth; usage policies and consent; moderation and content filters; compute constraints for consumer devices.
- E-commerce & Fashion (Industry): virtual try-on and merchandising in video
- Use case: Overlay garments, accessories, or models onto lifestyle recordings; create lookbook videos with multi-subject insertion (garment + model + background).
- Tools/products/workflows: OmniInsert multi-reference pipeline; CAR prompt templates for sizing/lighting; SL-enhanced fidelity for small apparel regions.
- Assumptions/dependencies: Pose/layout alignment; accurate scale and occlusion handling; permission for model imagery; domain-specific LoRA.
- Game Development & Pre-Vis (Industry/Academia): rapid scene iteration with mixed assets
- Use case: Prototype cutscenes by inserting new characters or props; blend reality and stylized footage; quickly iterate narrative beats.
- Tools/products/workflows: InsertPipe-generated data for internal testing; SimInteract assets for controlled motion; configurable guidance scales for balance.
- Assumptions/dependencies: Asset libraries and motion bindings; reliance on VLM for layout; GPU budget; downstream animation pipeline coordination.
- AR/VR Marketing Videos (Industry): asynchronous effects without runtime masking
- Use case: Produce campaign videos placing virtual brand elements into live-action scenes with natural harmonization.
- Tools/products/workflows: CAR-generated VFX instruction prompts; IPO-refined model for artifact mitigation; batch rendering service.
- Assumptions/dependencies: Not real-time; camera metadata helps placement; disclosure requirements.
- Education & Cultural Content (Academia/Daily Life): contextualized historical or scientific inserts
- Use case: Insert historical figures into reenactments; demonstrate scientific apparatus in classroom recordings.
- Tools/products/workflows: Pedagogical prompt libraries; CAR to enforce scene realism and scale; watermarked outputs for transparency.
- Assumptions/dependencies: Ethical disclosure; subject likeness rights; institution policies.
- Synthetic Data Generation for Vision (Academia/Industry): scenario augmentation
- Use case: Insert pedestrians, vehicles, or objects in diverse urban videos to augment detection/tracking datasets.
- Tools/products/workflows: InsertPipe (RealCapture + SynthGen + SimInteract) for scalable, labeled insertions; SL to preserve small object fidelity.
- Assumptions/dependencies: Labeling strategy for inserted regions; domain gap vs. real-world; inpainting quality for source-video preparation.
- Benchmarking & Research Tools (Academia): standardizing MVI evaluation
- Use case: Evaluate new algorithms on InsertBench; reproduce ablations on PT, SL, IPO, CAR; study multi-condition guidance.
- Tools/products/workflows: Public benchmark and code; protocol with CLIP/DINO/FaceSim/ViCLIP/VBench++ metrics.
- Assumptions/dependencies: Community adoption; consistent metric baselines; availability of trained checkpoints.
- SaaS/API for Video Insertion (Software/Industry): managed service
- Use case: Enterprises integrate mask-free insertion via API for internal content pipelines (marketing, training, support videos).
- Tools/products/workflows: REST API exposing CFI settings, guidance scalars (S1–S3), CAR; LoRA fine-tuning per brand.
- Assumptions/dependencies: GDPR/CCPA compliance; subject IP licensing; operational SLAs; GPU autoscaling.
Long-Term Applications
- Real-Time Broadcast & Live Streaming (Industry): on-the-fly insertion
- Use case: Live sports and events with dynamic overlays (mascots, AR signage) without manual masking.
- Tools/products/workflows: Low-latency DiT variants, distillation/quantization for edge inference, hardware acceleration.
- Assumptions/dependencies: Sub-100ms latency targets; robust temporal consistency; resilient prompt control; specialized hardware.
- Telepresence & Personalized Avatars (Industry/Daily Life): identity-consistent video substitution
- Use case: Replace a participant with a licensed avatar in live video calls or recorded talks.
- Tools/products/workflows: Identity LoRA packs; CAR constraints for spatial/pose coherence; preference-optimized IPO for social plausibility.
- Assumptions/dependencies: Consent and licensing of likeness; stable face/body tracking; privacy safeguards; watermarking/provenance.
- Wearable AR & On-Device Insertion (Industry/Daily Life): ambient, context-aware overlays
- Use case: Insert navigational cues, assistants, or safety objects into the user’s view.
- Tools/products/workflows: Lightweight DiT with CFI variants; spatial layout models; energy-efficient runtimes.
- Assumptions/dependencies: On-device compute and battery; robust scene understanding; safety guardrails; real-time CAR alternatives.
- Interactive Storytelling & Games (Industry): player-driven content customization
- Use case: Players summon characters into game cutscenes or personalize narrative sequences without pre-authored masks.
- Tools/products/workflows: Authoring toolkits with InsertPipe-derived assets; CAR for interaction prompts; multi-reference pipelines for teams/parties.
- Assumptions/dependencies: Motion control interfaces; content policy and moderation; IP licensing for imported subjects.
- Large-Scale Ad Personalization (Industry): automated, context-optimized placements
- Use case: Deploy millions of videos with scene-specific product placement tuned to region/audience.
- Tools/products/workflows: Scene classifier + CAR for prompt optimization; IPO-refined models; QA with InsertBench-like suites.
- Assumptions/dependencies: Measurement frameworks; governance for synthetic content; scalable compute; opt-in/opt-out mechanisms.
- Public Policy & Governance (Policy): standards for disclosure and provenance
- Use case: Mandate provenance metadata for inserted content; enforce visible/invisible watermarking; define consent workflows for subject references.
- Tools/products/workflows: C2PA integration; cryptographic signatures; audit trails; usage dashboards.
- Assumptions/dependencies: Cross-industry adoption; interoperability; regulatory clarity; user education.
- Education & Training (Academia/Policy): authentic learning experiences at scale
- Use case: Personalized tutors or lab assistants inserted into instructional videos.
- Tools/products/workflows: Curriculum-aligned CAR prompts; classroom policies for disclosure; accessibility adjustments (captions, alt-prompts).
- Assumptions/dependencies: Pedagogical efficacy studies; avoidance of bias/misrepresentation; sustainable compute budgets.
- Smart Cities & Public Safety Simulation (Industry/Policy): scenario planning
- Use case: Generate complex crowd or vehicle interactions for planning drills or safety analysis.
- Tools/products/workflows: SimInteract motion libraries; CAR for spatial constraints; IPO for physical plausibility.
- Assumptions/dependencies: Realism requirements; ethical use; dataset governance; alignment with physics engines.
- Robotics & Autonomy (Academia/Industry): robust perception through synthetic variation
- Use case: Domain randomization by inserting diverse objects/humans into sensor video; rare event training.
- Tools/products/workflows: InsertPipe pipelines producing paired before/after clips; label transfer tools; evaluation via InsertBench adaptations.
- Assumptions/dependencies: Bridging sim-to-real gaps; accurate annotation propagation; sensor-specific modeling.
- Security & Deepfake Ecosystem (Policy/Industry): detection and mitigation
- Use case: Train detectors on insertion artifacts; standardize disclosures in platforms; countermeasure research.
- Tools/products/workflows: Curated insertion datasets; watermark verification services; platform-side provenance checks.
- Assumptions/dependencies: Cooperative platform policies; legal frameworks; evolving adversarial tactics.
Cross-Cutting Assumptions and Dependencies
- Technical: Access to strong video foundation models, VLM/LLM for CAR; GPU/accelerator resources; robust tracking/inpainting for InsertPipe; tuning via LoRA; guidance scale calibration (S1–S3).
- Legal/ethical: Subject likeness and IP licensing; consent workflows; watermarking/provenance; content moderation; regional regulations.
- Operational: Data governance for synthetic pairs; benchmarking adoption (InsertBench); QA processes to prevent copy-paste artifacts; user education on synthetic content.
- UX: Prompt quality (CAR) strongly influences realism; domain-specific templates and constraints improve outcomes; balanced multi-condition guidance is critical for subject-scene equilibrium.
Glossary
- Aesthetics: An automated metric estimating the visual appeal of generated videos. Example: "Dynamic Quality, Image-Quality, Aesthetics and Consistency~\cite{huang2024vbench++} for Video Quality."
- AnimateDiff: A diffusion-based approach that adds temporal modeling to image models for video generation. Example: "AnimateDiff~\cite{guo2023animatediff} integrates 1D temporal attention into 2D spatial blocks for efficiency."
- Classifier-free guidance: A sampling technique that balances diversity and fidelity by mixing conditional and unconditional predictions. Example: "Classifier-free guidance~\cite{ho2022classifier} balances sample quality and diversity in diffusion models through joint conditional and unconditional training."
- CLIP-I: A subject consistency metric based on CLIP similarity between frames and reference images. Example: "We assess three dimensions: CLIP-I, DINO-I and FaceSim~\cite{deng2019arcface} for Subject Consistency;"
- Condition-Specific Feature Injection (CFI): A mechanism to inject different conditions (video and subject) into the diffusion model using tailored concatenations and flags. Example: "we introduce a simple yet effective Condition-Specific Feature Injection (CFI) mechanism."
- Context-Aware Rephraser (CAR): An inference-time module that enriches prompts with scene-aware details to improve insertion harmony. Example: "the Context-Aware Rephraser (CAR) enriches user prompts at inference time by injecting fine-grained scene details (such as object textures, spatial layout, and interaction cues) into the instruction."
- DDIM inversion: A technique to map a real image/video back to a noise latent for editing through deterministic sampling. Example: "Prior approaches~\cite{ku2024anyv2v, zhao2023make} employ DDIM inversion to initialize the generation noise based on the reference video and inject subject features during the denoising steps."
- DINO-I: A subject consistency metric using DINO-based feature similarity. Example: "We assess three dimensions: CLIP-I, DINO-I and FaceSim~\cite{deng2019arcface} for Subject Consistency;"
- Diffusion Transformer (DiT): A transformer-based denoising network used in diffusion models for images/videos. Example: "The Diffusion Transformer (DiT)~\cite{peebles2023scalable} model employs a transformer as the denoising network to refine diffusion latent."
- Euler sampler: A numerical sampler used during diffusion inference to generate outputs in fixed steps. Example: "During inference, we use the Euler sampler with 50 steps"
- FaceSim: A face similarity metric (often ArcFace-based) for identity preservation. Example: "We assess three dimensions: CLIP-I, DINO-I and FaceSim~\cite{deng2019arcface} for Subject Consistency;"
- Flow Matching: A training framework for generative models that learns a velocity field between data and noise. Example: "Our method inherits the video diffusion transformers trained using Flow Matching~\cite{lipman2022flow}"
- Flow matching loss: The objective used in flow matching to regress the velocity between data and noise. Example: "In Phases 1â3, the flow matching loss ($\mathcal{L}_{\text{FM}$) serves as the primary training objective."
- Image-to-Video (I2V): Models that synthesize videos conditioned on images. Example: "we synthesize target videos depicting natural interactions using the Image-to-Video (I2V) foundation models~\cite{gao2025seedance}"
- InsertBench: A benchmark of videos, subjects, and prompts for evaluating mask-free video insertion. Example: "we introduce a comprehensive benchmark, InsertBench, which consists of 120 videos paired with meticulously selected subjects (suitable for insertion in each video) and the corresponding prompts."
- InsertPipe: A data construction pipeline (RealCapture, SynthGen, SimInteract) for generating paired training data. Example: "we propose a new data pipeline InsertPipe, producing training data consisting of reference subjects paired with appropriately edited videos and textual prompt."
- Insertive Preference Optimization (IPO): A fine-tuning method using human preference pairs to improve insertion plausibility. Example: "Insertive Preference Optimization (IPO) guides the model to learn context-aware insertion strategies using a curated set of paired videos that reflect human preferences across diverse scenes."
- LoRA: A parameter-efficient fine-tuning approach that adapts transformer weights via low-rank updates. Example: "we integrate the LoRA mechanism into the DiT blocks to avoid expensive full-parameter updates"
- Mask-free Video Insertion (MVI): The task of inserting subjects into videos without using explicit masks. Example: "In this work, our focus is on the task of Mask-free Video Insertion (MVI), inserting user-defined characters into a reference video according to the customized prompt."
- Patchification: The process of partitioning images/videos into patches (tokens) for transformer processing. Example: "or to concatenate reference visual tokens after patchification."
- Progressive Training (PT): A multi-stage training strategy to balance learning subject insertion and background preservation. Example: "we propose a novel Progressive Training (PT) strategy, which enables the model to balance multi-condition injection through multi-stage optimization."
- Rigged assets: 3D assets with skeletons and bindings enabling articulated motion in rendering. Example: "Leveraging rigged assets with predefined motion bindings, we synthesize interactions"
- Spatiotemporal patches: Patch tokens spanning both spatial and temporal dimensions for transformer-based video generation. Example: "These methods treat video as a sequence of spatiotemporal patches, processing them in a unified manner with a Transformer."
- Subject-Focused Loss (SL): A loss that emphasizes reconstruction in subject regions to improve identity/detail preservation. Example: "we design a Subject-Focused Loss (SL) to aid the model in focusing on capturing the detailed appearance of the subjects."
- Temporal attention: Attention mechanisms operating across time to capture motion and temporal coherence. Example: "AnimateDiff~\cite{guo2023animatediff} integrates 1D temporal attention into 2D spatial blocks for efficiency."
- Temporal interpolation: Generating intermediate frames to ensure continuity in synthesized or edited videos. Example: "Leveraging temporal interpolation and video inpainting to synthesize the target videos"
- U-Net: A convolutional encoder-decoder architecture widely used in diffusion backbones. Example: "VDM~\cite{ho2022video} extends 2D U-Net to 3D"
- VAE features: Latent features produced by a variational autoencoder used as conditioning signals. Example: "A straightforward solution is to inject VAE features of the references along the temporal dimension"
- ViCLIP-T: A text-video alignment metric based on video-language embeddings. Example: "ViCLIP-T~\cite{wang2022internvideo} for Text-Video Alignment;"
- Video erasing: Techniques to remove objects/subjects from videos, often for data generation. Example: "we apply video erasing techniques~\cite{zi2025minimax} to remove target subjects to create source videos"
- Video foundation model: Large generative or editing backbones specialized for video tasks. Example: "The development of diffusion models~\cite{ho2020denoising} has significantly advanced video foundation model research."
- Video inpainting: Filling or reconstructing missing/removed video regions with plausible content. Example: "Leveraging temporal interpolation and video inpainting to synthesize the target videos"
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for tasks like captioning and scoring. Example: "The Vision-LLM (VLM)~\cite{GPT4} then captions these clips, detailing subject appearance, scenes, and interactions."
- Visual tokens: Tokenized patch embeddings representing visual inputs for transformer models. Example: "to concatenate reference visual tokens after patchification."
Collections
Sign up for free to add this paper to one or more collections.

