- The paper introduces MEDTalk, which disentangles emotion and content to control 3D facial animations with dynamic expressions.
- Its methodology combines self-supervised training, multimodal fusion modules, and disentangled embeddings to achieve independent lip and emotion control.
- Quantitative and user studies confirm improved lip synchronization, accurate emotional intensity, and diverse expression generation.
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
The paper "MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding" (2507.06071) introduces a novel framework, MEDTalk, for generating emotional 3D talking head animations with fine-grained control and dynamic emotion variations. The approach focuses on disentangling content and emotion features to enable independent control over lip synchronization and facial expressions. Furthermore, it integrates multimodal inputs, including text descriptions and reference images, to guide the generation of user-specified facial expressions. The framework uses MetaHuman as a base, facilitating integration into industrial production pipelines.
Disentangled Embedding Space for Facial Animation
MEDTalk's architecture hinges on a disentangled embedding space, achieved through self-supervised training on motion sequences. This decoupling network employs two encoders, Ee and Ec, to extract emotion and content features from the input motion sequence. These features are then concatenated and passed through a decoder D, which reconstructs the facial animation sequence. The training process uses a self-supervised feature exchange strategy with three key phases: self-reconstruction, overlap exchange, and cycle exchange. The training is supervised by the reconstruction loss Lrecon, which is the ℓ2 error of the reconstructed sequences.
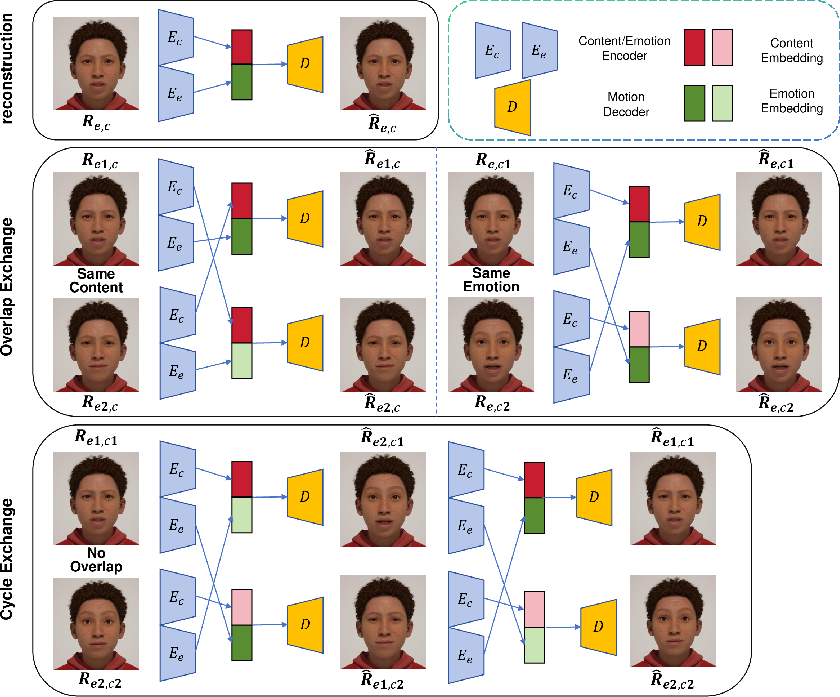
Figure 1: Illustration of the disentanglement strategy using self-supervised learning, which can effectively decouple content and emotion features.
The authors argue that this approach offers advantages over speech-based disentanglement, as facial motion directly expresses emotional expressions, avoiding complex audio-expression mappings. After training, the motion decoder is frozen, enabling features from different modalities to be mapped into a unified embedding space, simplifying multimodal control and ensuring consistent emotion representation across modalities. T-SNE visualizations confirm that distinct emotional categories are separated in the emotion embedding space but are indistinguishable in the content embedding space (Figure 2). Emotion embedding swaps further validate the independent control over facial expressions without affecting lip shapes (Figure 3).
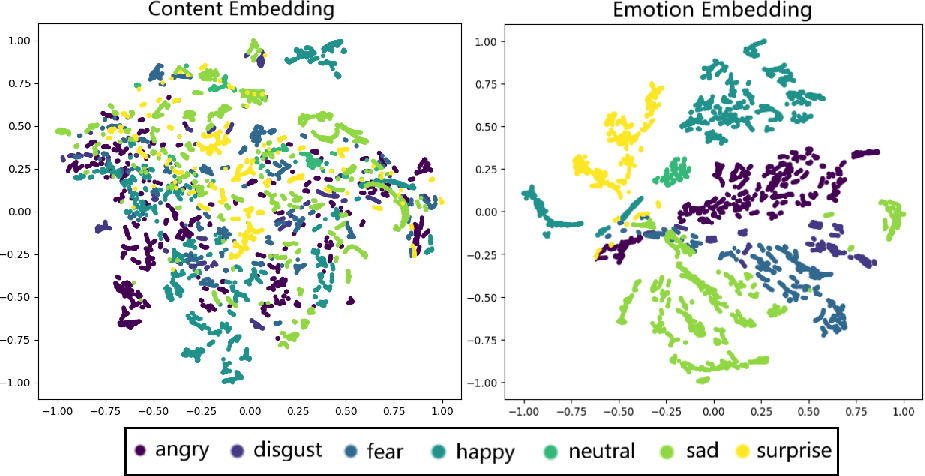
Figure 2: Disentangled Embedding Spaces.
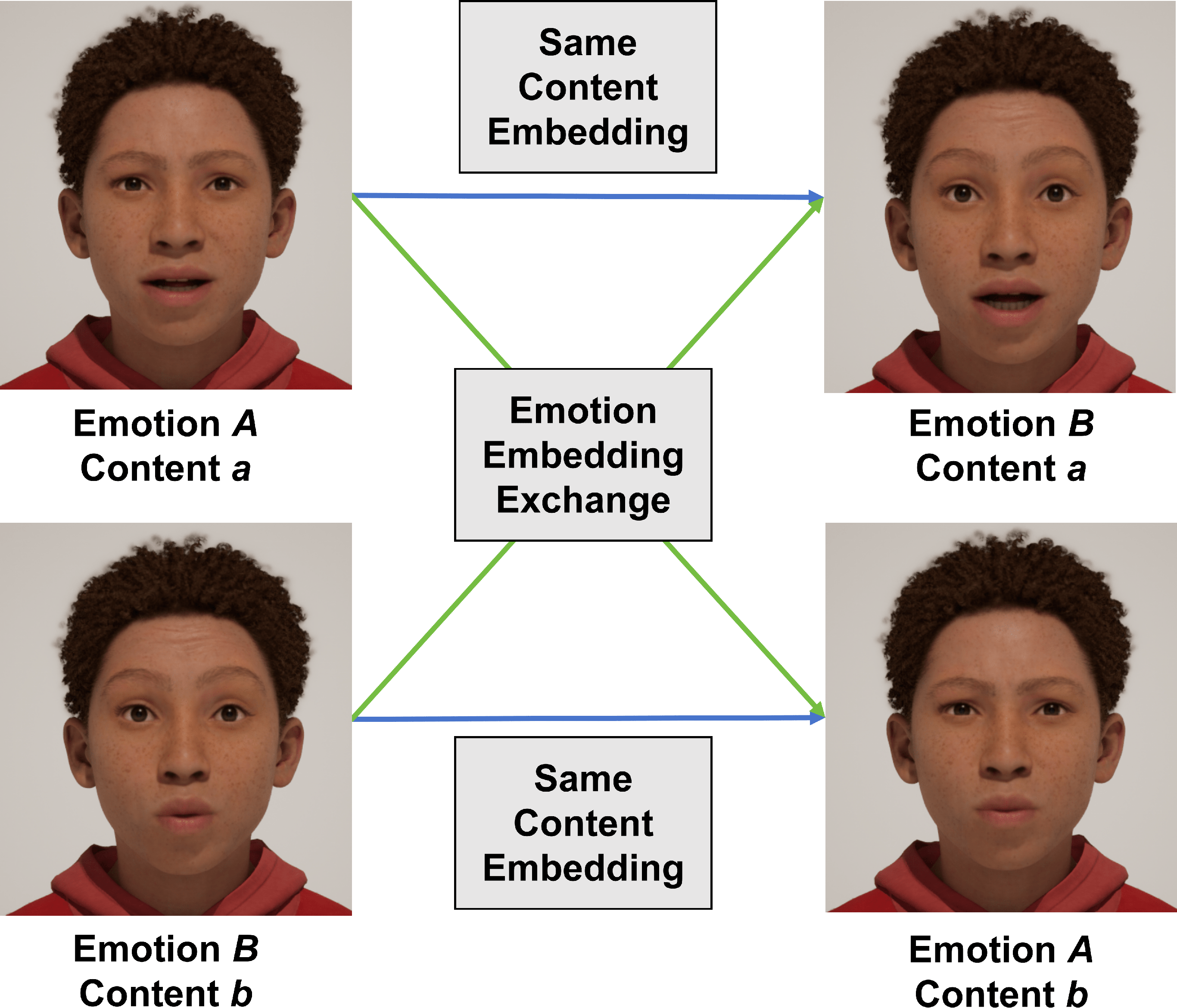
Figure 3: Swapping emotion embedding alters the emotional expression, with the lip shapes unaffected.
Dynamic Emotional Facial Animation with Multimodal Fusion
MEDTalk generates emotional facial animations with dynamic intensity using audio and emotion labels as inputs. The model comprises two primary modules: Audio Content Mapping (ACM) and Fusion Intensity Modeling (FIM). The ACM extracts lip-related features from the input audio A1:T using wav2vec2.0 [baevski2020wav2vec] and a lightweight mapping network. The FIM integrates audio and speech text features to predict frame-wise emotional intensity. This is achieved by extracting emotion-related features Haudio from audio using emotion2vec [ma2023emotion2vec] and encoding transcribed speech text using a pre-trained RoBERTa-based model [cui2020revisiting] to obtain text embeddings Htext. A Cross-Modality Fusion (CMF) module, employing cross-attention, integrates these modalities to predict frame-wise intensity $\hat{\bm{I}_{1:T}$ (Figure 4). The emotion embedding flabel is adjusted using the predicted frame-wise intensity. This dynamic emotion feature $\tilde{\bm{F}^{label}_{1:T}$ is then mapped into the frozen emotion embedding space via the fusion encoder Efuse. Training is supervised by a combination of reconstruction loss Lrecon, similarity loss Lsim, and intensity prediction loss Lint.
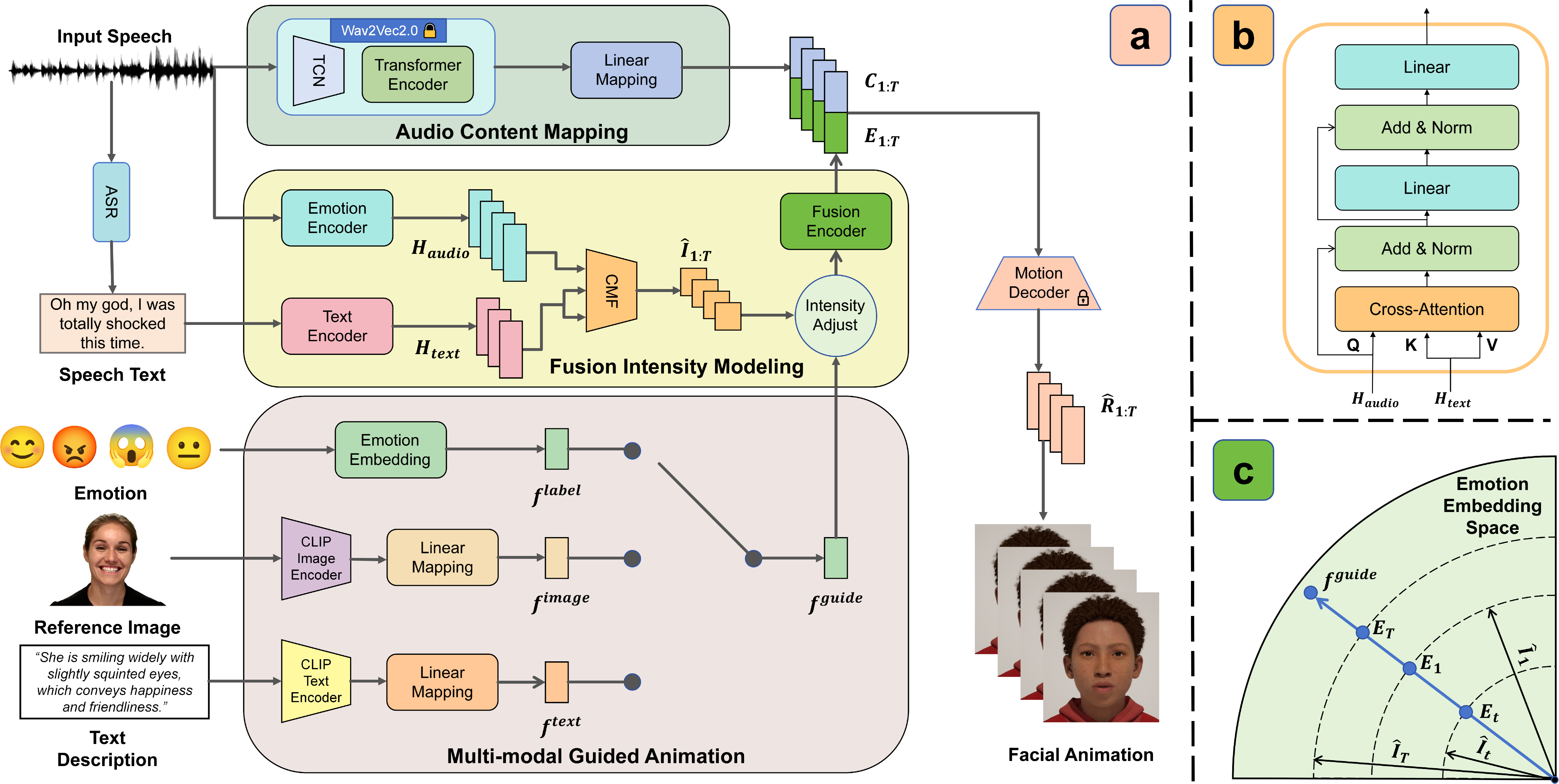
Figure 4: Illustration of MEDTalk. (a) The overall architecture of MEDTalk. It integrates audio, text, and multimodal guidance to generate expressive facial animations. (b) The Cross-Modality Fusion (CMF) module, which effectively combines audio and text features. (c) Intensity adjustment. The norm of emotion embedding is modulated based on the predicted emotion intensity.
Multimodal Guidance for Stylized Expression Generation
To enable fully user-controllable facial emotion features, MEDTalk incorporates text descriptions and reference facial images as optional guidance, overcoming the limitations of predefined emotion labels. The authors collect reference images and corresponding text descriptions from the RAVDESS dataset [livingstone2018ryerson]. CLIP's text encoder Etext and image encoder Eimage are used and projection networks Ptext and Pimage map the encoded features to latent features ftext and fimage with the same dimension as flabel. In multimodal guided generation mode, these multimodal embeddings replace the emotion label embeddings. The model is trained by freezing all components except Ptext, Pimage, and the fusion encoder Efuse, using a loss function including reconstruction loss Lrecon and similarity loss Lsim. The results of multimodal guidance exhibit strong alignment with the inputs provided, achieving accurate and controllable emotional expression (Figure 5).

Figure 5: Results of multimodal guidance. Given reference images or text descriptions, MEDTalk generates facial animations that accurately reflect the specified speaking style.
Evaluation and Results
The authors propose Mean Lip Error (MLE) and Mean Emotion Error (MEE) to evaluate the accuracy of generated animation. Additionally, Emotion Intensity Error (EIE) and Upper-Face Rig Deviation (FRD) are introduced to evaluate the dynamic characteristics of facial expressions. Quantitative results demonstrate that MEDTalk outperforms competing methods in MLE and MEE, indicating superior accuracy in lip shape and upper-face expressions. MEDTalk achieves the second-best performance in EIE, accurately capturing emotional intensity dynamics. FRD results indicate that MEDTalk surpasses other baseline methods in expression diversity. User studies further validate that MEDTalk outperforms other methods in lip synchronization, emotional accuracy, and vividness. Ablation studies confirm the effectiveness of the disentanglement strategy, the inclusion of frame-wise intensity, and the incorporation of both audio and text for dynamic emotion modeling.
Conclusion
MEDTalk offers a versatile and effective solution for controllable 3D talking head animation, enabling precise, independent control over lip movements and facial expressions by disentangling content and emotion embeddings. The framework enhances expressiveness by dynamically extracting emotion intensity from both audio and spoken text and supports multimodal input, allowing users to guide emotions through textual or visual cues. Although the generalization of lip shape generation is constrained by the diversity of the training data and the current multimodal guidance mechanism does not extend to individual facial movements, the authors plan to expand the dataset and explore more comprehensive multimodal control strategies in future work.

