Fast quantum computation with all-to-all Hamiltonians
Published 29 Sep 2025 in quant-ph, math-ph, and math.MP | (2509.25345v1)
Abstract: All-to-all interactions arise naturally in many areas of theoretical physics and across diverse experimental quantum platforms, motivating a systematic study of their information-processing power. Assuming each pair of qubits interacts with $\mathrm{O}(1)$ strength, time-dependent all-to-all Hamiltonians can simulate arbitrary all-to-all quantum circuits, performing quantum computation in time proportional to the circuit depth. We show that this naive correspondence is far from optimal: all-to-all Hamiltonians can process information on much shorter timescales. First, we prove that any two-qubit gate can be simulated by all-to-all Hamiltonians on $N$ qubits in time $\mathrm{O}(1/N)$ (up to factor $N{\delta}$ with an arbitrarily small constant $\delta>0$), with polynomially small error $1/\mathrm{poly}(N)$. Immediate consequences include: 1) Certain $\mathrm{O}(N)$-qubit unitaries and entangled states, such as the multiply-controlled Toffoli gate and the GHZ and W states, can be generated in $\mathrm{O}(1/N)$ time; 2) Trading space for time, any quantum circuit can be simulated in arbitrarily short time; 3) Information could propagate in a fast way that saturates known Lieb-Robinson bounds in strongly power-law interacting systems. Our second main result proves that any depth-$D$ quantum circuit can be simulated by a randomized Hamiltonian protocol in time $T=\mathrm{O}(D/\sqrt{N})$, with constant space overhead and polynomially small error. The techniques underlying our results depart fundamentally from the existing literature on parallelizing commuting gates: We rely crucially on non-commuting Hamiltonians and draw on diverse physical ideas.
The paper presents O(1/N)-time and O(D/√N)-time protocols for simulating two-qubit gates and general quantum circuits, showcasing significant speedups.
It leverages bosonic amplification and Fourier transform techniques to implement many-qubit operations with controlled error scaling.
It establishes that all-to-all Hamiltonians can surpass standard circuit models by saturating Lieb-Robinson bounds and enabling rapid entangled state preparation.
Fast Quantum Computation with All-to-All Hamiltonians
Introduction and Motivation
The study addresses the computational power of all-to-all (ATA) Hamiltonians, a class of many-body quantum systems where every pair of qubits can interact with O(1) strength. Such Hamiltonians are realized in various experimental platforms, including trapped ions, cavity QED, and superconducting qubits, and are central to theoretical models in quantum optics, spin glasses, and quantum gravity. The canonical approach to quantum computation in these systems is to simulate quantum circuits by sequentially activating two-qubit interactions, leading to a computation time proportional to the circuit depth. This work challenges the optimality of this approach and demonstrates that ATA Hamiltonians can process quantum information on much shorter timescales, leveraging the full parallelism inherent in the Hamiltonian model.
Main Results: Polynomial Speedup over Circuit Depth
The paper establishes two principal results:
O(1/N)-Time Simulation of Two-Qubit Gates and Certain Many-Qubit Unitaries: Any two-qubit gate can be simulated by an ATA Hamiltonian on N qubits in time O(1/N) (up to subpolynomial corrections), with error 1/poly(N). This result extends to the implementation of certain O(N)-qubit unitaries, such as the multiply-controlled Toffoli gate, and the preparation of highly entangled states like GHZ and W states, all in O(1/N) time. This is a significant improvement over previous protocols, which required at least O(logN) or O(1) time for such operations.
O(D/N)-Time Simulation of General Depth-D Circuits: Any depth-D quantum circuit on N qubits can be simulated by a randomized ATA Hamiltonian protocol in time O(D/N), with constant space overhead and error 1/poly(N) for almost all inputs. This result is achieved using only 2-local interactions and is sufficient for practical applications, such as implementing Shor's algorithm in O(N) time.
These results are underpinned by protocols that exploit non-commuting Hamiltonians and semiclassical collective effects, in contrast to previous approaches based on parallelizing commuting gates.
Protocols for Fast Gate Simulation
O(1/N)-Time Protocols via Bosonic Amplification
The O(1/N)-time protocol is constructed by mediating data-qubit interactions through a large ancilla register, which collectively behaves as a bosonic mode in the symmetric Dicke manifold. The protocol proceeds in three stages: (1) squeezing the collective ancilla state to amplify the signal, (2) displacing the squeezed state conditioned on the data qubit, and (3) engineering a potential to imprint the desired phase, followed by reversing the squeezing. The Holstein-Primakoff transformation is used to map the collective spin operators to bosonic operators, and the protocol is implemented by truncating the bosonic Hamiltonians to K-local qubit interactions.
Figure 1: Sketch of the O(1/N)-time protocol for simulating multi-qubit gates via bosonic amplification using collective ancilla qubits.
The error can be made polynomially small by choosing a sufficiently large but constant K, and the protocol time scales as O(1/N). This approach enables the fast preparation of GHZ and W states and the implementation of multiply-controlled Toffoli gates, with speedups of O(N) and O(N) over previous methods, respectively.
Space-Time Tradeoff and Lieb-Robinson Bounds
By increasing the number of ancilla qubits relative to data qubits, the protocol allows for an arbitrary tradeoff between space and time: a depth-D circuit on Nd≪N data qubits can be simulated in time O(DNd/N). This demonstrates that, in the Hamiltonian model, computation time can be made arbitrarily small at the expense of space overhead, a feature not present in the standard circuit model.
The protocol also saturates the Lieb-Robinson bound for strongly power-law interacting systems, establishing the tightness of the bound T=Ω(Nα/(d−1)) for information propagation in systems with Hij∼rij−α and α<d.
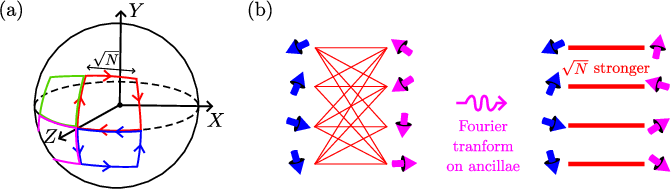
General Circuit Simulation: O(D/N)-Time Protocol
For arbitrary depth-D circuits, the paper introduces a protocol that achieves a O(N) speedup using only 2-local interactions and constant space overhead. The construction is based on a generalization of the Mølmer-Sørensen scheme, where the ancilla register is Fourier transformed to focus the interaction strength onto specific modes, enabling the parallel simulation of O(N) two-qubit gates in O(1/N) time per layer.
Figure 2: Sketch of the O(D/N)-time protocol for simulating general quantum circuits by focusing interaction strengths via Fourier modes of the ancilla register.
The protocol is exact for almost all input states and can be made robust to worst-case inputs by randomizing on-site fields, effectively reducing the simulation error to 1/poly(N). The approach leverages semiclassical trajectories in the collective spin phase space and geometric phase accumulation, with error control achieved via higher-order Suzuki-Trotter decompositions.
Theoretical and Practical Implications
The results demonstrate that the Hamiltonian model of quantum computation, when equipped with ATA interactions, is strictly more powerful than the standard circuit model under comparable interaction strengths. The O(1/N) and O(1/N) speedups are asymptotically optimal in the sense that they saturate known information propagation bounds. The protocols rely on non-commuting Hamiltonians and collective effects, highlighting the importance of many-body physics concepts such as squeezing and spin waves in quantum information processing.
From a practical perspective, the findings suggest that experimental platforms capable of engineering ATA Hamiltonians—such as trapped ions, cavity QED, and superconducting circuits—can realize quantum algorithms with significantly reduced execution times, provided that the required time-dependent and multi-body interactions can be implemented with sufficient control and fidelity. The space-time tradeoff further enables flexible resource allocation in hardware design.
Theoretically, the work opens several directions: (1) exploring whether the O(N) speedup for general circuits can be improved or made deterministic for all inputs, (2) investigating information processing tasks intrinsic to the Hamiltonian model that do not correspond to circuit simulation, and (3) developing error correction strategies compatible with continuous-time Hamiltonian evolution.
Conclusion
This work rigorously establishes that all-to-all Hamiltonians can process quantum information at rates polynomially faster than the standard quantum circuit model, under the same interaction strength constraints. The protocols developed leverage non-commuting dynamics and collective semiclassical effects, enabling the fast simulation of both specific many-qubit gates and general quantum circuits. These results have direct implications for the design and operation of quantum devices with ATA connectivity and motivate further investigation into the computational complexity and error correction in the Hamiltonian paradigm.