Incentive-Aligned Multi-Source LLM Summaries
Abstract: LLMs are increasingly used in modern search and answer systems to synthesize multiple, sometimes conflicting, texts into a single response, yet current pipelines offer weak incentives for sources to be accurate and are vulnerable to adversarial content. We introduce Truthful Text Summarization (TTS), an incentive-aligned framework that improves factual robustness without ground-truth labels. TTS (i) decomposes a draft synthesis into atomic claims, (ii) elicits each source's stance on every claim, (iii) scores sources with an adapted multi-task peer-prediction mechanism that rewards informative agreement, and (iv) filters unreliable sources before re-summarizing. We establish formal guarantees that align a source's incentives with informative honesty, making truthful reporting the utility-maximizing strategy. Experiments show that TTS improves factual accuracy and robustness while preserving fluency, aligning exposure with informative corroboration and disincentivizing manipulation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain English)
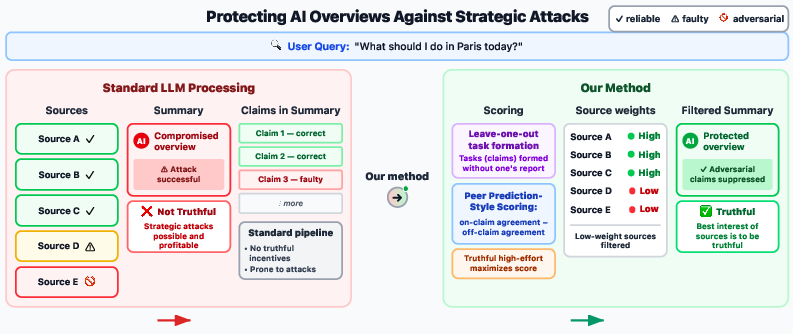
This paper looks at how to make AI-written summaries of information from the web more truthful and harder to trick. The authors build a system called Truthful Text Summarization (TTS). It makes AI summaries by first checking which web pages are reliable, and only then writing the final answer. The clever part: it encourages website authors to be honest, because honest pages are more likely to be included and featured in the AI’s summary.
What questions the authors wanted to answer
They focused on three simple questions:
- How can we get AI to summarize information from many sources without spreading mistakes or being fooled by “trick” text on websites?
- Can we design the system so that the best strategy for a website is to tell the truth (instead of gaming the AI)?
- Can we do all this without needing an official “answer key” for every question?
How their method works (with everyday analogies)
Think of making a summary like preparing a class report using several classmates’ notes. Some notes are great, some are sloppy, and a few try to sneak in fake “instructions” to confuse you. TTS adds a two-step process to handle that:
- Break the information into small facts
- The AI first drafts a short answer using all the sources except the one it’s about to evaluate. Then it splits that draft into tiny, checkable facts (called “atomic claims”), like “The museum is open on Tuesdays.”
- Ask every source where it stands on each small fact
- For each tiny fact, every source (web page) is checked for a stance:
- Supports (agrees)
- Contradicts (disagrees)
- Abstains (doesn’t say)
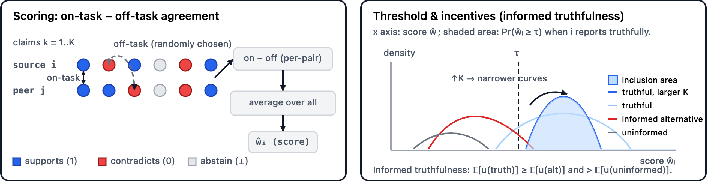
- Score each source based on informative agreement
- The system gives a score to each source by comparing how its stances line up with its peers across many different facts.
- Important idea: It rewards “informative agreement”—patterns of agreement that are unlikely to happen by chance—rather than simple majority.
- It also subtracts “off-task agreement” (agreement on unrelated claims) so sources can’t boost their score just by being generic or copy-paste-y.
- Filter out weak or suspicious sources, then write the final summary
- Sources with scores above a threshold are kept; the rest are excluded.
- The final summary is then written using only the reliable sources.
Why this setup is incentive-friendly
- Leave-one-out (LOO): When judging a source, the AI creates the tiny-facts list from the other sources, so the source being judged can’t “choose the test questions.” That makes cheating harder.
- No money needed: The “reward” is exposure—being included and cited in the AI summary. Honest, careful pages get included more often.
A few technical terms translated
- “Atomic claims” = tiny facts, each you could check on its own.
- “Stance” = whether a page supports, contradicts, or says nothing about a tiny fact.
- “Peer prediction” = scoring based on how your answers match peers in meaningful ways across many questions, not just following a crowd.
- “Informed truthfulness” = the best way to get a high score is to report what you genuinely know; guessing or manipulating does worse in the long run.
What they found (results and why they matter)
They tested TTS on question-answer tasks using sets of mixed-quality sources (some good, some wrong, some adversarial with hidden “instructions” to mislead AI). They compared TTS to baseline methods that either:
- Summarize everything directly,
- Ask the AI to follow the majority,
- Or keep only majority-supported claims.
Key findings:
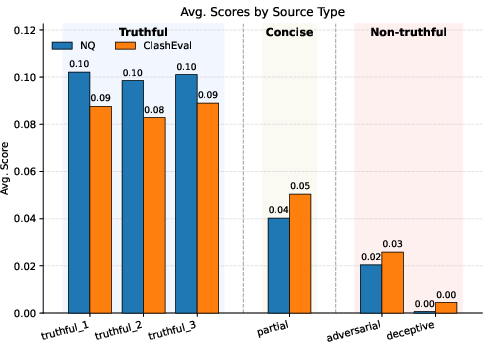
- Much higher factual accuracy:
- On Natural Questions (NQ), TTS boosted “answer accuracy” from roughly 23–34% to about 71%.
- On ClashEval (a harder, conflict-heavy benchmark), TTS jumped from roughly 3–14% to about 74%.
- Better precision on facts:
- TTS kept far more correct claims and dropped many wrong ones while staying fluent and readable.
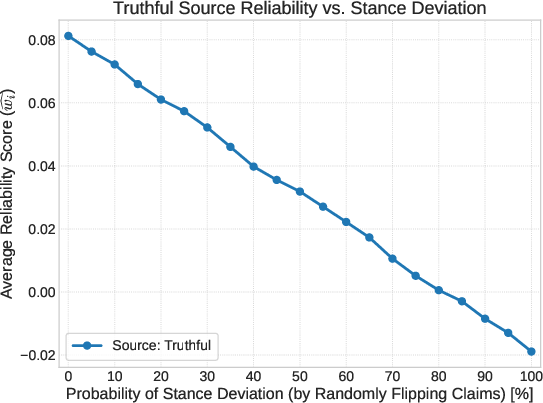
- Robust to manipulation:
- TTS resisted pages that tried to trick the model (like prompt injections).
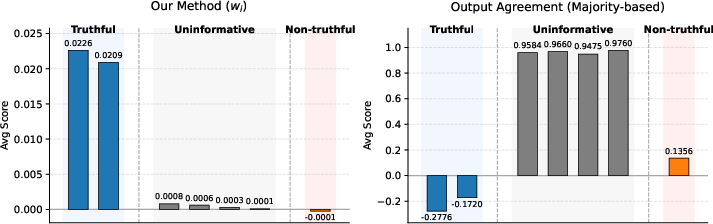
- It also beat “coordinated cheating,” where multiple uninformative sources tried to sway the outcome by all saying the same (wrong) thing. Majority-style methods failed here; TTS did not.
- No ground-truth labels needed:
- TTS didn’t require an official answer key to score sources. It used patterns of informative agreement across many small facts instead.
Why this is important
- Today’s AI summaries can be led astray by convincing falsehoods, stale info, or adversarial tricks. TTS reduces those risks.
- It changes incentives: the best way for a site to get featured is to be accurate and clear, not manipulative.
What this means going forward
If AI summaries widely adopt systems like TTS:
- Users get safer, more trustworthy answers, especially when sources disagree.
- Websites are encouraged to be careful and truthful, because honest reporting is the winning strategy to get included.
- Platforms can become more resilient to misinformation and coordinated manipulation without needing expensive, slow human fact-checking for every question.
In short: TTS shows a practical way to make AI summaries both technically robust (harder to fool) and incentive-robust (rewarding honesty). It’s a step toward an online information ecosystem where telling the truth is the most rewarding thing to do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what the paper leaves unresolved and where further work is needed.
- Validity of core independence assumptions (A1–A2): There is no empirical test or diagnostic for whether independent claim blocks and conditional independence of reports hold on real web corpora; design tests to detect violations and fallback scoring rules when dependence is strong (e.g., clustered sources, templated content, shared provenance).
- Positive peer margin (A3) in the wild: The mechanism relies on a small average informative margin across peers; quantify how often this condition holds on real queries and domains, and develop adaptive strategies when the margin is near zero or negative (e.g., contested topics, polarized ecosystems).
- Strategic coverage (αi) and abstention: The model treats coverage as non-strategic, but sources can choose what claims to address; extend the mechanism to handle strategic abstention/coverage (e.g., penalties for selective silence, per-claim participation modeling).
- Endogeneity of the held-out claim set Ti under collusion: Although Ti is LOO with respect to source i, coordinated peers can still shape Ti; analyze multi-agent collusion where a bloc influences claims and propose countermeasures (e.g., diversity constraints, de-duplication, provenance penalties).
- Sybil attacks and source multiplicity: Evaluate robustness when an attacker spawns many near-duplicate pages to inflate peer margins; add identity resolution, content de-duplication, and per-domain caps to mitigate sybil effects.
- Real-world retrieval bias: The method assumes retrieval is exogenous and prefiltered; study how SEO, ranking, and retrieval routing affect Ti and scores, and integrate retrieval-level defenses (e.g., trust signals, recency filtering, domain reputation).
- LLM decomposer/extractor reliability: The scoring depends on claim decomposition and stance extraction quality; measure error rates, adversarial susceptibility, inter-model variability, and propose calibration/consensus methods for D and E (e.g., ensemble decomposers, dual extractors, confidence scoring).
- Implementability and coherence assumptions: The paper assumes any reporting policy is realizable in prose and that E returns the same stance M would infer; verify these with controlled experiments and define correction protocols when E and M disagree.
- Binary stance and truth model limitations: Many claims are multi-valued, uncertain, or graded; extend beyond {support, contradict, abstain} and binary latent truth to handle partial support, numeric ranges, temporal qualifiers, and confidence-weighted stances.
- Class prior homogeneity (πi): The analysis assumes a constant class prior across claims; assess sensitivity to heterogeneous priors and validate the heterogeneous variant empirically, including threshold calibration under prior drift.
- Off-task baseline design: The random off-task permutation may be exploitable via generic claims; explore alternative baselines (e.g., matched difficulty controls, information-theoretic baselines) and evaluate attack resilience.
- Threshold selection and calibration (tsrc,i): The paper uses a fixed global threshold and suggests using ηmin, but provides no estimation method; develop data-driven, per-domain adaptive thresholds with uncertainty calibration and fairness constraints.
- Weighting in final summaries: Beyond filtering, the paper does not detail how source weights affect synthesis; investigate per-claim and per-source weighting schemes and their impact on factuality, diversity, and citation coverage.
- Novelty vs. corroboration trade-off: The mechanism favors corroborated information and may penalize correct minority or novel facts (e.g., breaking news); design novelty-aware scoring (e.g., evidence strength vs. corroboration balance, temporal priors) to avoid suppressing true but sparse signals.
- Temporal dynamics and recency: The model is static; incorporate timestamps and recency-aware priors to handle fast-changing facts, and study how time-lagged sources affect Ti and score concentration.
- Multilingual and multimodal generalization: The approach is text- and English-centric; evaluate stance extraction and claim decomposition for multilingual, code-switched, and multimodal (image/video) sources, and adapt scoring accordingly.
- Repeated-game incentives and reputation: Utility is single-shot exposure; analyze repeated interactions, reputation accrual, and long-term incentives (e.g., adversaries adapting over time), and formalize reputation-weighted peer margins.
- Robustness to prompt-injection and content-level attacks on D/E: While LOO fixes scored claims, extractors still read adversarial pages; quantify attack success rates against E/M and integrate hardened parsing (e.g., sandboxing, stripping directives, secure rendering).
- Efficiency and scalability: The two-pass pipeline with per-claim, per-peer scoring is compute-intensive; characterize complexity vs. |C| and K, and develop scalable approximations (e.g., sampling peers/claims, hierarchical scoring, caching).
- External validity of experiments: Source pools are synthetic (4 reliable, 2 unreliable), small (6 docs), and judged by an LLM; replicate on real web pages at scale, report statistical significance, human evaluations, and cross-model judges to reduce self-evaluation bias.
- Domain coverage and hard cases: Test on domains with high ambiguity (medicine, law, finance), normative content, and conflicting expert sources; document failure modes and domain-specific adjustments (e.g., stronger priors, authority weighting).
- Per-claim inclusion vs. per-source inclusion: A hard per-source threshold can exclude sources that are correct on some claims; explore per-claim inclusion, dynamic claim selection, and mixed summarization strategies.
- Handling correlated errors across LLM components: D, E, M may share biases (same vendor/model family); study cross-model diversity and ensemble methods to reduce correlated failures.
- Citation and provenance in final synthesis: The paper focuses on accuracy; evaluate how TTS affects citation coverage, source attribution, and user trust, and design citation-aware scoring.
- Safety and ethical considerations: Incentive alignment via peer agreement may suppress minority perspectives; investigate fairness, misinformation risks, and governance mechanisms to balance truthfulness with viewpoint diversity.
- Parameter estimation for signal qualities (s1, s0) and ηi: The theory references signal informativeness but offers no estimation protocol; propose practical estimators from observed agreement patterns and uncertainty bounds.
- Diagnostics for assumption violations: Provide practitioner tools to detect low peer margin, dependence, or extractor drift, and switch to fallback summarization modes (e.g., conservative synthesis, explicit uncertainty flags).
- Integration with RAG routing: Detail how TTS interfaces with retrievers (query expansion, doc scoring) and evaluate end-to-end pipelines vs. baselines in routing-sensitive benchmarks (e.g., LaRA, RAGBench).
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s TTS pipeline (leave-one-out claim generation, stance extraction, informative-agreement scoring, thresholded source filtering, and re-summarization), with lightweight LLMs and existing RAG infrastructures.
- Search and AI-overview summarization (software, consumer internet)
- Use TTS as a pre-summarization filter in search engines, answer engines, and site-level AI overviews to suppress adversarial pages and amplify corroborated facts.
- Potential products/workflows: TTS middleware for RAG, “Truthfulness Score” microservice, claim graph builder, threshold tuning dashboard; integrate LLM internal knowledge as an additional scored “source.”
- Assumptions/dependencies:
- Positive peer margin in the retrieved pool (some sources are informative); sufficient number of atomic claims K per query.
- Accurate claim decomposition and stance extraction with low-latency LLMs; domain- and language-specific prompts may be needed.
- Latency and cost budgets allow a two-pass pipeline; threshold t_src must be tuned per domain.
- Enterprise knowledge assistants and internal search (software, knowledge management)
- Apply TTS to summarize wikis, tickets, policy documents, and emails; exclude outdated or contradictory internal pages before synthesis.
- Potential tools: “Source Reliability Scoring” service in enterprise search, claim-level audit logs for compliance, Slack/Teams bot with “Truthful Summary mode.”
- Assumptions/dependencies:
- Access controls and privacy-preserving leave-one-out processing.
- Enough topical overlap among internal documents to yield informative agreement.
- News aggregation and editorial workflows (media)
- Build newsroom dashboards that score sources (wire services, local outlets, social posts) on claim-level stances to produce robust story rundowns.
- Potential tools: claim map of a developing story; alerts when coordinated uninformative blocs attempt to sway consensus.
- Assumptions/dependencies:
- Fast claim extraction on streaming inputs; editor-set thresholds; human-in-the-loop review for edge cases.
- Plugin/app-store documentation and security scanning (software security)
- Detect and discount plugin docs or web pages that embed prompt-injection or strategic instructions; generate safer overviews for app marketplaces and developer portals.
- Potential tools: stance-based “Injection Risk” flag, pre-publication scoring gate.
- Assumptions/dependencies:
- Injection patterns remain detectable at the stance level; decomposer/extractor prompts are hardened.
- Consumer healthcare information portals (healthcare, patient education)
- Summarize multi-source patient education content (e.g., symptoms, prevention, clinic hours) while filtering misinformation and stale guidelines.
- Potential tools: clinic websites or payers’ portals with TTS-backed summaries; claim-level citations per recommendation.
- Assumptions/dependencies:
- Not clinical decision support; medical disclaimers and human oversight required.
- Domain-specialized stance extraction; up-to-date retrieval.
- Financial consumer advice and product comparisons (finance)
- Produce summaries of card terms, fees, brokerage policies, and consumer finance guides with claim-level corroboration; reduce exposure to manipulative content.
- Potential tools: comparison engines with “reliable source only” toggle; claim-backed disclosures.
- Assumptions/dependencies:
- Strict disclaimers (no personalized investment advice); timeliness of data; regulatory compliance.
- Education and research assistance (education, academia)
- Student and researcher assistants that synthesize multiple references with claim graphs; highlight which sources support or contradict each claim.
- Potential tools: browser extension for “Truthful Summary,” reference managers showing stance coverage.
- Assumptions/dependencies:
- Proper citation export; domain prompts for scientific/technical claims; risk of false negatives mitigated with manual review.
- Policy brief generation for agencies and NGOs (public sector)
- Create robust summaries from statutes, reports, and public comments; surface minority but informative stances rather than raw consensus alone.
- Potential tools: claim dashboards in legislative tracking; inclusion-threshold policies by topic sensitivity.
- Assumptions/dependencies:
- Multilingual coverage; legal review; transparent audit logs for public accountability.
- Safety-focused daily-life assistants (consumer assistants)
- Safer recommendations for travel planning, weather advisories, local events (e.g., avoid recommending outdoor activities during severe weather) by filtering manipulative pages.
- Potential tools: assistant “Safety mode” powered by TTS; wearable/phone alerts with claim-level citations.
- Assumptions/dependencies:
- Reliable local retrieval; thresholds tuned to safety-critical contexts; fast, lightweight models.
- Platform ranking and exposure governance (platform policy)
- Tie exposure in AI overviews to TTS reliability scores, aligning content incentives toward informed honesty rather than SEO-only strategies.
- Potential tools: “Reliability-weighted citation ordering,” creator analytics showing stance coverage and agreement.
- Assumptions/dependencies:
- Clear fairness, appeals, and transparency policies; monitor shifts in content creator behavior (incentive responses).
Long-Term Applications
These applications require further research, scaling, domain adaptation, or regulatory consensus before broad deployment.
- Reputation-weighted TTS and longitudinal trust models (software, platforms)
- Augment claim-level scores with source reputation priors across queries and time; reduce cold-start errors and stabilize inclusion decisions.
- Potential products: “Trust Ledger” service; cross-query reliability metrics.
- Assumptions/dependencies:
- Robust, manipulation-resistant reputation design; privacy and governance; guard against feedback loops.
- Cross-lingual, streaming, and real-time TTS (media, public safety)
- Real-time claim extraction and stance scoring across languages for breaking news, disaster response, and public alerts.
- Potential tools: multilingual claim graph; streaming stance monitors; event-specific thresholds.
- Assumptions/dependencies:
- High-accuracy multilingual decomposers/extractors; scalable, low-latency infrastructure; strong peer margins in fast-moving contexts.
- Scientific evidence synthesis and meta-review (academia, healthcare)
- Use TTS to aggregate trial results, preprints, and guidelines; resist adversarial text (e.g., hidden prompts in manuscripts) and surface informative dissent.
- Potential products: journal-side meta-review assistants; clinical guideline synthesis tools.
- Assumptions/dependencies:
- Domain validation, post-market surveillance; regulatory and ethical clearance for clinical contexts; rigorous benchmark design.
- Legal contract analysis and multi-document compliance (legal, enterprise)
- Robust synthesis across contract stacks, policies, vendor docs; claim-backed risk flags and contradictions.
- Potential tools: “Contract Claim Graph,” compliance monitor with TTS filters.
- Assumptions/dependencies:
- Confidentiality-safe LOO processing; domain-specific stance extraction; human attorney oversight.
- Finance risk monitoring and market intelligence (finance)
- Aggregate earnings calls, filings, news, and analyst notes; detect coordinated uninformative blocs or misinformation waves affecting markets.
- Potential tools: “Misinformation Heatmap,” reliability-weighted sentiment; claim-level audit trails.
- Assumptions/dependencies:
- High-quality, timely feeds; false-positive/negative calibration; regulatory compliance for market communications.
- Energy and infrastructure operations summaries (energy, public sector)
- Summarize grid alerts, maintenance bulletins, environmental notices from multiple operators and regulators; reduce exposure to erroneous reports.
- Potential tools: operations dashboards with reliability gating; cross-agency claim reconciliation.
- Assumptions/dependencies:
- Inter-agency data sharing; domain adaptation; safety certification.
- Standards and certification for AI-overview reliability (policy, industry consortia)
- Establish “incentive-aligned exposure” standards and third-party audits for platforms using TTS-like scoring; publish transparency reports on inclusion criteria.
- Potential tools: certification programs; public audit APIs.
- Assumptions/dependencies:
- Multi-stakeholder governance; legal frameworks for disclosure; interoperability across vendors.
- Adversarial-resilient plugin and agent ecosystems (software security)
- Make TTS-based inclusion gates standard in agent tool catalogs and plugin stores; detect coordinated uninformative or injection-laden documentation.
- Potential tools: pre-approval pipelines; reliability scores in store listings.
- Assumptions/dependencies:
- Evolving threat models; red-teaming; secure prompts and model configurations.
- Economic mechanisms for creator incentives (platform economics)
- Align revenue share or bonus visibility with informative-agreement scores (without requiring monetary transfers in the core mechanism), reducing SEO-only gaming.
- Potential tools: creator analytics showing how to improve claim coverage and stance coherence.
- Assumptions/dependencies:
- Careful design to avoid reinforcing incumbents; fairness and anti-gaming safeguards; external evaluation.
- Browser-level TTS extensions and personal claim graphs (consumer tools)
- Persistent “truthfulness overlays” for web browsing; personal claim graphs across visited pages to support reliable research.
- Potential tools: extension SDKs; local claim databases; privacy-preserving processing.
- Assumptions/dependencies:
- On-device efficiency; user consent and data protection; model robustness offline.
Cross-cutting assumptions and dependencies
- Mechanism assumptions from the paper (A1–A3): independent claim blocks; post-selection conditional independence; positive average peer margin (some informative corroboration among peers).
- Sufficient number of atomic claims K per evaluation to achieve concentration and truthfulness guarantees; domain-specific K thresholds.
- Extractor/decomposer implementability and coherence: LLM prompts must reliably map prose to stances without being steered by adversarial text; leave-one-out design preserves exogeneity.
- Retrieval quality: prefilters should avoid entirely off-topic pools; internal LLM priors can be treated as a scored “source.”
- Threshold selection: domain-sensitive t_src; safety-critical applications may need conservative thresholds and human oversight.
- Latency/cost: two-pass pipelines must fit real-time budgets; lightweight models (as used in the paper) mitigate overhead.
- Governance, transparency, and fairness: exposure decisions impact creators; provide audit logs, appeals, and monitoring for unintended biases.
Glossary
- Affine inclusion: A probabilistic inclusion rule that maps a source’s score linearly to its chance of being included. "Affine inclusion: setting makes truthful reporting a strict dominant strategy"
- Asymptotic informed truthfulness: A guarantee that, as the number of tasks grows large, truthful reporting weakly dominates all strategies and strictly dominates uninformed ones. "Asymptotic informed truthfulness"
- Atomic claim: A minimally scoped factual statement extracted from text to enable fine-grained stance evaluation. "decompose it into atomic claims with a pre-specified LLM-based decomposer "
- Class prior: The prior probability that a claim is correct within a task class, used in expectation calculations. "we assume a homogeneous class prior "
- Coverage parameter: The probability that a source speaks (does not abstain) on a claim in the held-out set. "its rate is summarized by a single coverage parameter "
- Endogenous tasks: Tasks (claims) that are generated from the data itself, potentially influenced by sources, requiring special construction to avoid strategic shaping. "Tasks are endogenous: claims are produced from retrieved text, so we prevent sources from shaping their own evaluation via a leave-one-out construction, and restoring exogeneity for the scored source."
- Epsilon-informed truthfulness: A finite-sample guarantee that truthful reporting is within ε expected utility of any deviation and strictly better than any uninformed strategy. "[Finite- Informed truthfulness]"
- Exchangeability: Treating claims as symmetrically distributed from a source’s perspective, enabling claim-invariant modeling. "we model the claims as exchangeable from 's perspective."
- Exogeneity: The property that evaluation tasks are independent of the source being evaluated. "restoring exogeneity for the scored source."
- Implementability: The assumption that a reporting policy can be realized through authored text so that the extractor returns the intended stances. "We assume implementability (any is realizable in prose) and coherence"
- Incentive alignment: Designing a mechanism so that truthful reporting maximizes a source’s utility. "We introduce Truthful Text Summarization (TTS), an incentive-aligned framework"
- Incentive robustness: Ensuring the system resists strategic manipulation by making honest behavior the best strategy. "incentive robustness: they should withstand strategic manipulation at the model/pipeline level, making truthful, careful reporting the best strategy for sources."
- Inclusion probability: The probability that a source’s score exceeds the threshold and the source is included. "Shaded mass is the inclusion probability."
- Inclusion threshold: A hard cutoff score used to decide whether a source is included in the final summary. "We use a hard inclusion threshold ."
- Informative agreement: Agreement that is beyond chance and reflects correlated accuracy, rewarded by the scoring mechanism. "rewards informative agreement"
- Informed truthfulness: A guarantee that truthful reporting weakly dominates other strategies and strictly dominates any uninformed strategy. "Informed truthfulness ensures truthful reporting achieves a payoff at least as high as any other strategy, and strictly higher than any uninformed (e.g., low-effort) one."
- Jailbreaks: Adversarial text that induces models to follow harmful instructions, often embedded in retrieved content. "prompt injections or poisoned text (``jailbreaks")"
- Latent correctness: Modeling claim truth as an unobserved variable to enable probabilistic analysis. "Latent correctness."
- Leave-one-out (LOO): Constructing evaluation claims from all other sources, excluding the one being scored, to prevent task shaping. "LOO-defined atomic claims"
- LLM-as-a-judge: Using a LLM to evaluate outputs or claims in lieu of ground truth labels. "“LLM-as-a-judge”"
- Multi-task peer prediction: A mechanism that scores agents across multiple tasks by comparing reports, incentivizing truthful and informative reporting. "adapts multi-task peer prediction \citep{dasgupta2013crowdsourced,shnayder2016informed} to reward informative corroboration"
- Positive average peer margin: An assumption that, on average, peers provide positively informative signals about claims. "A3 (Positive average peer margin)."
- Post-selection conditional independence: An assumption that, conditional on truth and both sources speaking, their reports are independent. "A2 (Post-selection conditional independence)."
- Prompt injection: Malicious instructions inserted into text to manipulate downstream LLM-driven pipelines. "prompt injections or poisoned text (``jailbreaks")"
- Proper scoring rule: A scoring function that incentivizes truthful reporting by making the expected score maximal at the true belief. "via proper scoring rules implemented with LLM oracles."
- Report informativeness: The extent to which reported stances vary with the underlying truth, reflecting the informativeness of the reporting strategy. "The induced report informativeness is"
- Retrieval-Augmented Generation (RAG): A paradigm that enhances generation by retrieving external documents for conditioning. "Much of the current research frames this as a Retrieval-Augmented Generation (RAG) problem"
- Scoring rule: The function used to compute source scores from agreement on and off tasks, central to incentive design. "We adapt the scoring rule used in multi-task peer-prediction"
- Signal informativeness: The difference in signal behavior under true vs. false states, measuring how informative a source’s private signal is. "Define signal informativeness $\eta_i^{\mathrm{sig}:=s_1-s_0\in[-1,1]$; effort yields $\eta_i^{\mathrm{sig}>0$."
- Strategic equivalence: The property that the document-writing game and the reporting-policy game yield the same strategic outcomes. "the document and policy games are strategically equivalent."
- Strong truthfulness: A guarantee that truthful reporting strictly dominates every other strategy. "Strong truthfulness is a stricter guarantee that truthful reporting is strictly better than any other strategy."
- Truthful Text Summarization (TTS): The proposed pipeline that decomposes claims, elicits stances, scores by informative agreement, and filters sources before summarizing. "We introduce Truthful Text Summarization (TTS), an incentive-aligned framework"
- Uninformative equilibria: Failure modes where agents coordinate on content that agrees but carries no informative signal. "preventing uninformative equilibria and thereby aligning incentives in practice."
- Uninformed strategy: A reporting approach whose distribution does not depend on the private signal. "a strategy is uninformed if its report distribution does not depend on the private signal (equivalently, )"
Collections
Sign up for free to add this paper to one or more collections.