Improving Faithfulness of Large Language Models in Summarization via Sliding Generation and Self-Consistency
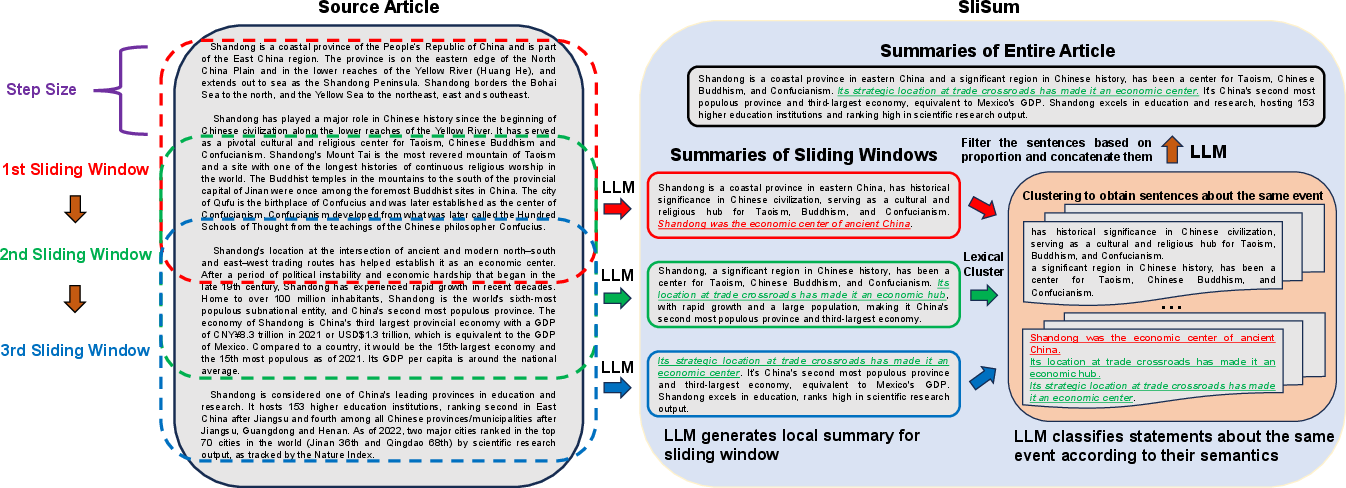
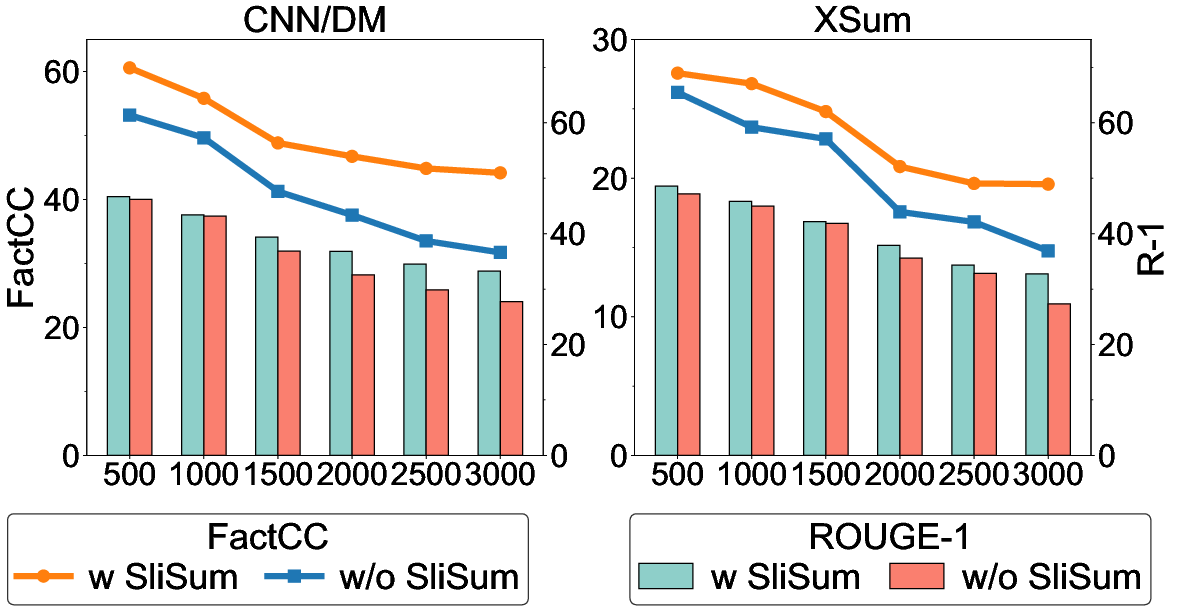
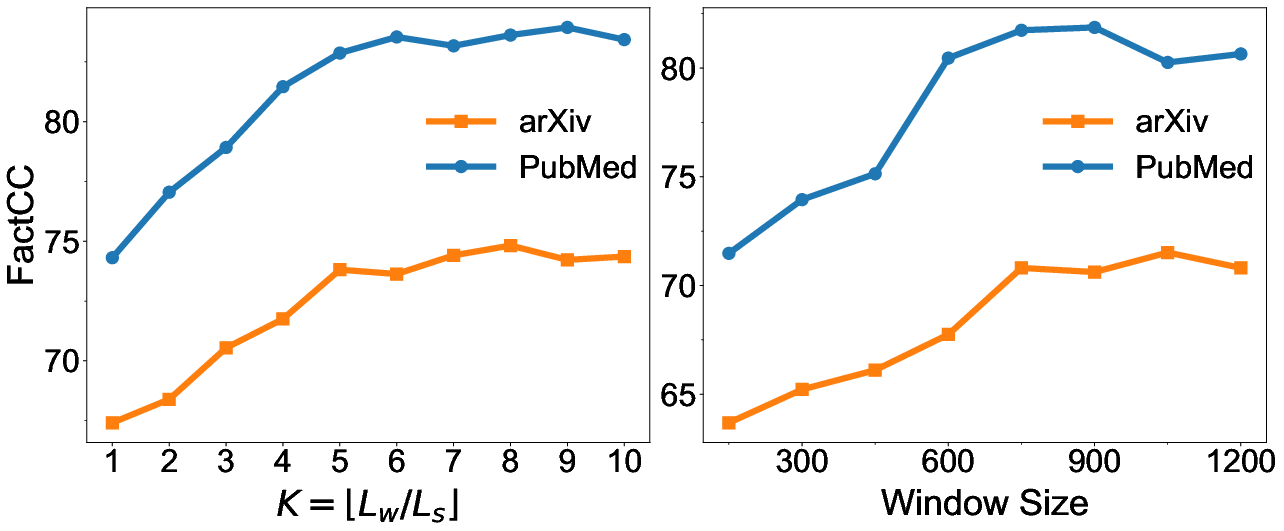
Abstract: Despite LLMs have demonstrated impressive performance in various tasks, they are still suffering from the factual inconsistency problem called hallucinations. For instance, LLMs occasionally generate content that diverges from source article, and prefer to extract information that appears at the beginning and end of the context, especially in long document summarization. Inspired by these findings, we propose to improve the faithfulness of LLMs in summarization by impelling them to process the entire article more fairly and faithfully. We present a novel summary generation strategy, namely SliSum, which exploits the ideas of sliding windows and self-consistency. Specifically, SliSum divides the source article into overlapping windows, and utilizes LLM to generate local summaries for the content in the windows. Finally, SliSum aggregates all local summaries using clustering and majority voting algorithm to produce more faithful summary of entire article. Extensive experiments demonstrate that SliSum significantly improves the faithfulness of diverse LLMs including LLaMA-2, Claude-2 and GPT-3.5 in both short and long text summarization, while maintaining their fluency and informativeness and without additional fine-tuning and resources. We further conduct qualitative and quantitative studies to investigate why SliSum works and impacts of hyperparameters in SliSum on performance.
- Anthropic. 2023. Model card and evaluations for claude models. Technical report, Anthropic.
- Correcting diverse factual errors in abstractive summarization via post-editing and language model infilling. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9818–9830, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- CLIFF: Contrastive learning for improving faithfulness and factuality in abstractive summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6633–6649, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- HIBRIDS: Attention with hierarchical biases for structure-aware long document summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 786–807, Dublin, Ireland. Association for Computational Linguistics.
- Purr: Efficiently editing language model hallucinations by denoising language model corruptions.
- Towards improving faithfulness in abstractive summarization. In Advances in Neural Information Processing Systems, volume 35, pages 24516–24528. Curran Associates, Inc.
- Revisiting zero-shot abstractive summarization in the era of large language models from the perspective of position bias.
- Toward unifying text segmentation and long document summarization. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 106–118, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 615–621, New Orleans, Louisiana. Association for Computational Linguistics.
- Sliding selector network with dynamic memory for extractive summarization of long documents. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5881–5891, Online. Association for Computational Linguistics.
- Chain-of-verification reduces hallucination in large language models.
- Multi graph neural network for extractive long document summarization. In Proceedings of the 29th International Conference on Computational Linguistics, pages 5870–5875, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Improving factuality and reasoning in language models through multiagent debate.
- A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, pages 226–231, Portland, USA. AAAI Press.
- Improving factual consistency in summarization with compression-based post-editing. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9149–9156, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Factorizing content and budget decisions in abstractive summarization of long documents. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6341–6364, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- TrueTeacher: Learning factual consistency evaluation with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2053–2070, Singapore. Association for Computational Linguistics.
- CRITIC: Large language models can self-correct with tool-interactive critiquing. In The Twelfth International Conference on Learning Representations.
- News summarization and evaluation in the era of gpt-3.
- MemSum: Extractive summarization of long documents using multi-step episodic Markov decision processes. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6507–6522, Dublin, Ireland. Association for Computational Linguistics.
- Lm-infinite: Simple on-the-fly length generalization for large language models.
- Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc.
- Zero-shot faithful factual error correction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5660–5676, Toronto, Canada. Association for Computational Linguistics.
- Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression.
- Knowledge graph-augmented language models for knowledge-grounded dialogue generation.
- Evaluating the factual consistency of abstractive text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346, Online. Association for Computational Linguistics.
- SummaC: Re-visiting NLI-based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics, 10:163–177.
- LangChain. 2023a. Summarization option 2. map-reduce.
- LangChain. 2023b. Summarization option 3. refine.
- HaluEval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449–6464, Singapore. Association for Computational Linguistics.
- Compressing context to enhance inference efficiency of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342–6353, Singapore. Association for Computational Linguistics.
- Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
- Lost in the middle: How language models use long contexts.
- A token-level reference-free hallucination detection benchmark for free-form text generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6723–6737, Dublin, Ireland. Association for Computational Linguistics.
- On improving summarization factual consistency from natural language feedback. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15144–15161, Toronto, Canada. Association for Computational Linguistics.
- Zero-resource hallucination prevention for large language models.
- SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore. Association for Computational Linguistics.
- On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online. Association for Computational Linguistics.
- Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. In The Twelfth International Conference on Learning Representations.
- Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797–1807, Brussels, Belgium. Association for Computational Linguistics.
- OpenAI. 2023. Introducing chatgpt.
- Check your facts and try again: Improving large language models with external knowledge and automated feedback.
- HeterGraphLongSum: Heterogeneous graph neural network with passage aggregation for extractive long document summarization. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6248–6258, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Incorporating distributions of discourse structure for long document abstractive summarization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5574–5590, Toronto, Canada. Association for Computational Linguistics.
- In-context retrieval-augmented language models.
- Parallel context windows for large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6383–6402, Toronto, Canada. Association for Computational Linguistics.
- On context utilization in summarization with large language models.
- Factually consistent summarization via reinforcement learning with textual entailment feedback. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6252–6272, Toronto, Canada. Association for Computational Linguistics.
- Leveraging gpt-4 for food effect summarization to enhance product-specific guidance development via iterative prompting.
- Evaluating the factual consistency of large language models through news summarization. In Findings of the Association for Computational Linguistics: ACL 2023, pages 5220–5255, Toronto, Canada. Association for Computational Linguistics.
- Llama 2: Open foundation and fine-tuned chat models. Technical report, Meta.
- Focused transformer: Contrastive training for context scaling. In Advances in Neural Information Processing Systems, volume 36, pages 42661–42688. Curran Associates, Inc.
- Exploring neural models for query-focused summarization. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1455–1468, Seattle, United States. Association for Computational Linguistics.
- David Wan and Mohit Bansal. 2022. FactPEGASUS: Factuality-aware pre-training and fine-tuning for abstractive summarization. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1010–1028, Seattle, United States. Association for Computational Linguistics.
- Large language models are not fair evaluators.
- Improving faithfulness by augmenting negative summaries from fake documents. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11913–11921, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations.
- Element-aware summarization with large language models: Expert-aligned evaluation and chain-of-thought method. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8640–8665, Toronto, Canada. Association for Computational Linguistics.
- FRSUM: Towards faithful abstractive summarization via enhancing factual robustness. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 3640–3654, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Personalized abstractive summarization by tri-agent generation pipeline. In Findings of the Association for Computational Linguistics: EACL 2024, pages 570–581, St. Julian’s, Malta. Association for Computational Linguistics.
- Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. In The Twelfth International Conference on Learning Representations.
- Alleviating exposure bias via multi-level contrastive learning and deviation simulation in abstractive summarization. In Findings of the Association for Computational Linguistics: ACL 2023, pages 9732–9747, Toronto, Canada. Association for Computational Linguistics.
- GRETEL: Graph contrastive topic enhanced language model for long document extractive summarization. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6259–6269, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Retrieval meets long context large language models. In The Twelfth International Conference on Learning Representations.
- Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thought.
- HEGEL: Hypergraph transformer for long document summarization. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10167–10176, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Extractive summarization via ChatGPT for faithful summary generation. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3270–3278, Singapore. Association for Computational Linguistics.
- Improving the faithfulness of abstractive summarization via entity coverage control. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 528–535, Seattle, United States. Association for Computational Linguistics.
- Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
- Benchmarking large language models for news summarization.
- Siren’s song in the ai ocean: A survey on hallucination in large language models.
- Why does chatgpt fall short in providing truthful answers?
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

