How Much Backtracking is Enough? Exploring the Interplay of SFT and RL in Enhancing LLM Reasoning
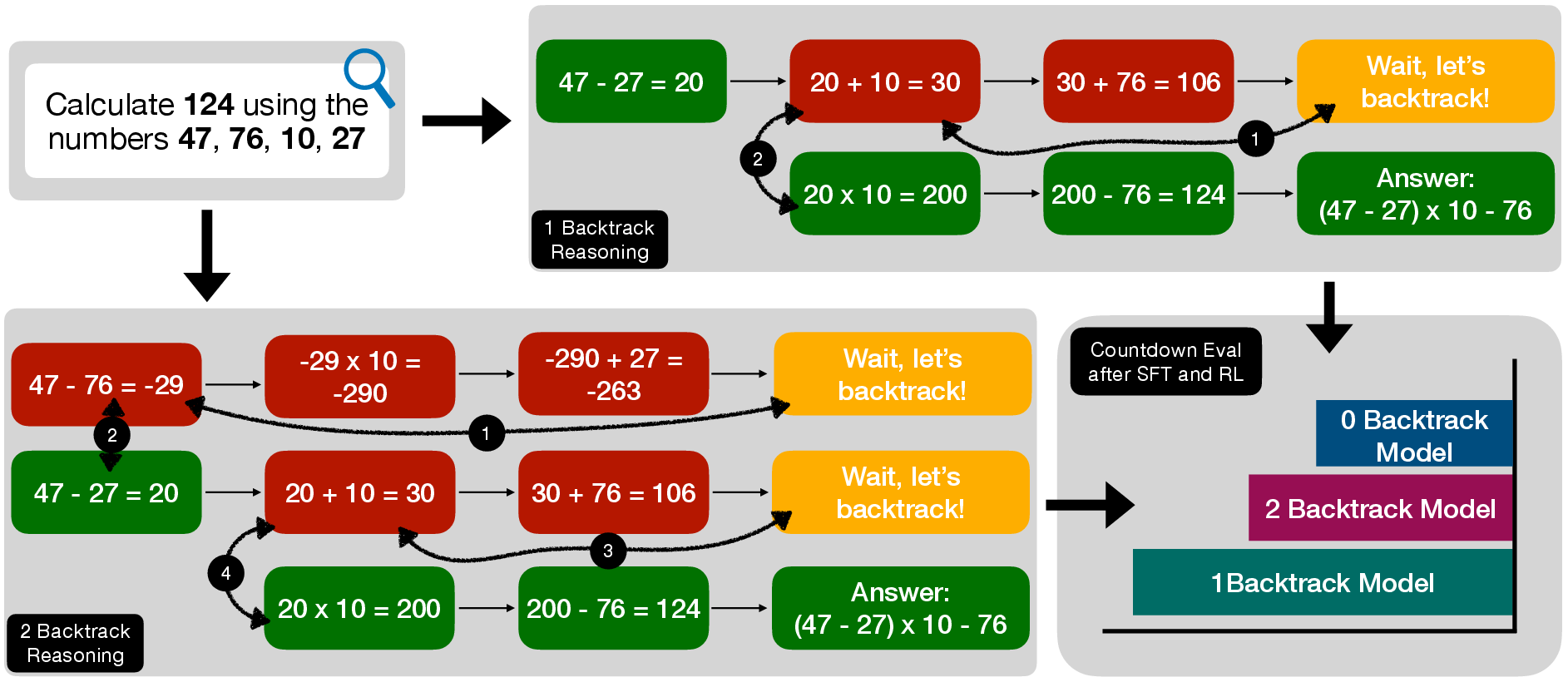
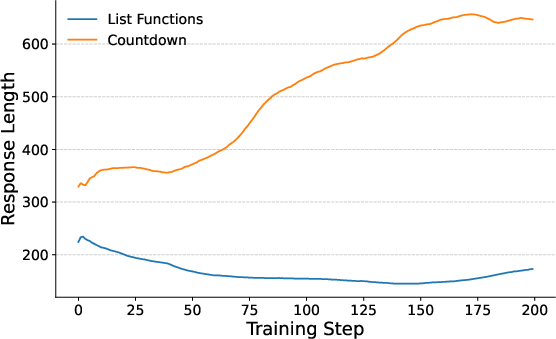
Abstract: Recent breakthroughs in LLMs have effectively improved their reasoning abilities, particularly on mathematical and logical problems that have verifiable answers, through techniques such as supervised finetuning (SFT) and reinforcement learning (RL). Prior research indicates that RL effectively internalizes search strategies, enabling long chain-of-thought (CoT) reasoning, with backtracking emerging naturally as a learned capability. However, the precise benefits of backtracking, specifically, how significantly it contributes to reasoning improvements and the optimal extent of its use, remain poorly understood. In this work, we systematically investigate the dynamics between SFT and RL on eight reasoning tasks: Countdown, Sudoku, Arc 1D, Geometry, Color Cube Rotation, List Functions, Zebra Puzzles, and Self Reference. Our findings highlight that short CoT sequences used in SFT as a warm-up do have moderate contribution to RL training, compared with cold-start RL; however such contribution diminishes when tasks become increasingly difficult. Motivated by this observation, we construct synthetic datasets varying systematically in the number of backtracking steps and conduct controlled experiments to isolate the influence of either the correctness (content) or the structure (i.e., backtrack frequency). We find that (1) longer CoT with backtracks generally induce better and more stable RL training, (2) more challenging problems with larger search space tend to need higher numbers of backtracks during the SFT stage. Additionally, we demonstrate through experiments on distilled data that RL training is largely unaffected by the correctness of long CoT sequences, suggesting that RL prioritizes structural patterns over content correctness. Collectively, our results offer practical insights into designing optimal training strategies to effectively scale reasoning in LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

