- The paper presents H2, a framework that unifies diverse chip architectures for efficient LLM training by standardizing operator and runtime integrations.
- It achieves superlinear speedup—with improvements up to 109.03% and minimal overhead—through innovations in device-direct RDMA and tailored pipeline parallelism.
- The framework’s PyTorch compatibility and topology-aware communication design facilitate practical deployment on large-scale, heterogeneous clusters.
Large-Scale LLM Training on Hyper-Heterogeneous Clusters: The H2 Framework
Motivation and Hyper-Heterogeneity Characterization
The exponential increase in LLM parameter counts necessitates leveraging substantial and diverse computational resources. Production clusters are increasingly composed of chips from multiple vendors, introducing pronounced disparities in compute power, memory, communication bandwidth, and software stacks. The paper defines "hyper-heterogeneous" clusters as those exhibiting non-monotonic, unpredictable patterns in capabilities across devices, breaking from traditional capability-incremental architectures. Unlike previous heterogeneous setups where chip generations from the same vendor offer natural software and communication stack cohesion, the hyper-heterogeneous scenario demands solutions for operator precision alignment, unified runtime, and robust communication abstraction.
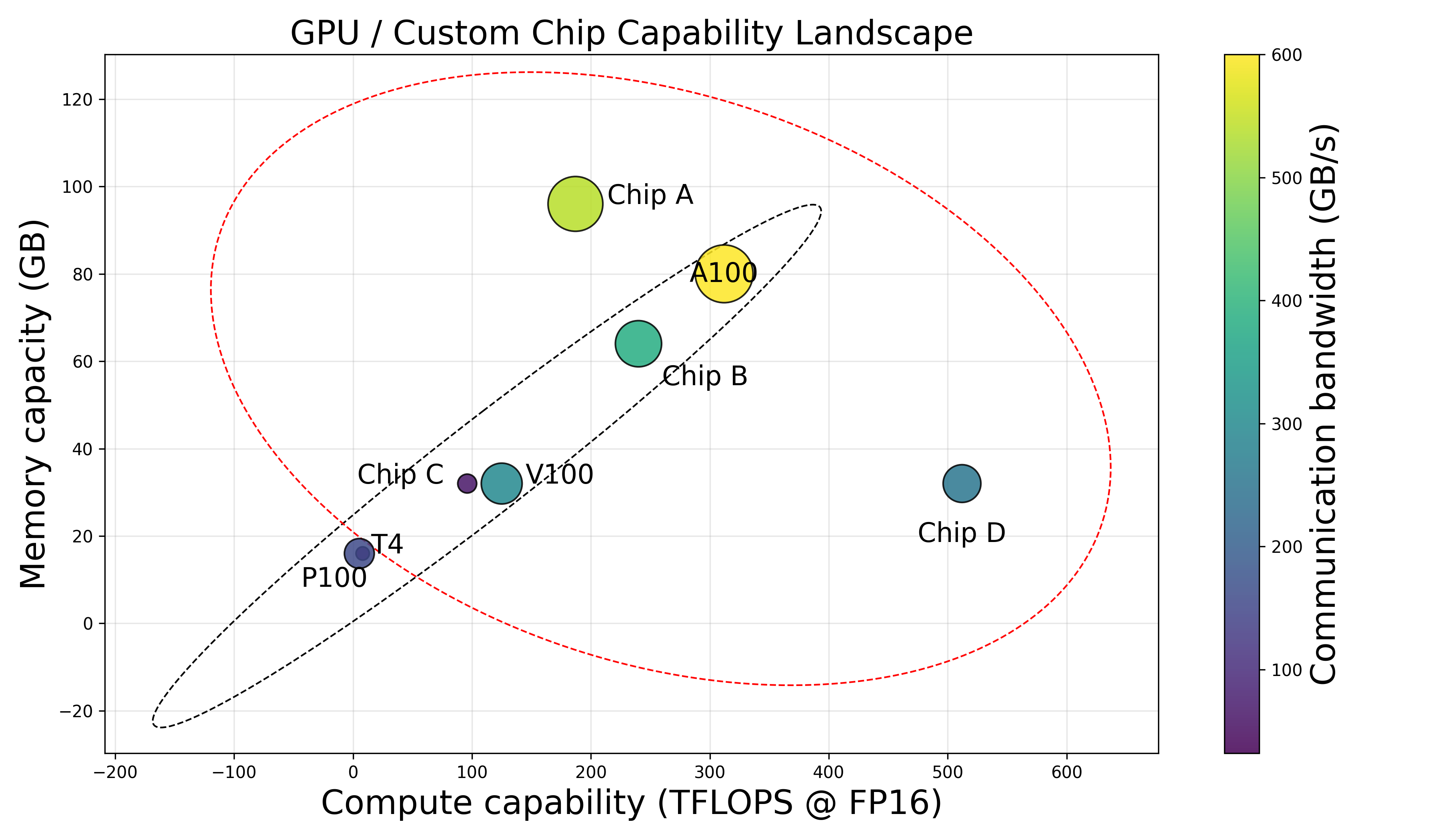
Figure 1: Contrasting capability-incremental architectures with hyper-heterogeneous clusters, with no predictable capability progression across chips.
Unified Software and Communication: DiTorch and DiComm
The H2 framework systematically addresses the technical isolation caused by disparate vendor software stacks, operator implementations, and communication libraries. DiTorch provides a PyTorch-compatible interface, harmonizing operator libraries and runtime semantics across chips. Through the Device-Independent Process Unit (DIPU) and Device-Independent Operator Interface (DIOPI), DiTorch creates standardized APIs and enables user-transparent execution on heterogeneous devices with minimal code adjustment. Precision congruity is enforced via operator-level numerical alignment and comprehensive profiling.
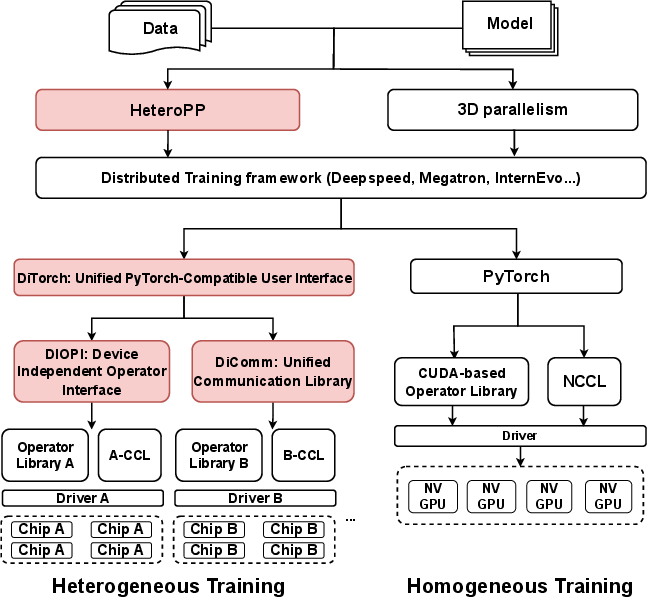
Figure 2: The LLM pre-training software stack, highlighting integration points for heterogeneous chip support (red components denote H2 contributions).
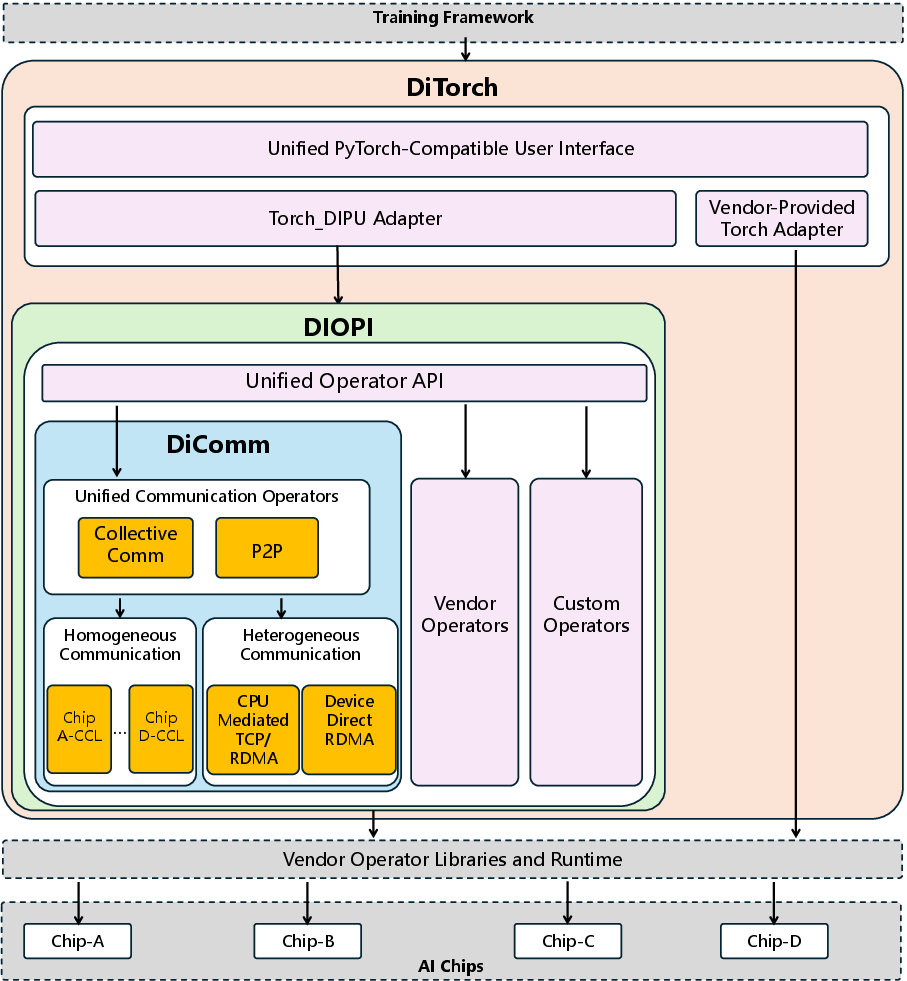
Figure 3: System architecture of DiTorch and DiComm, detailing unified interface and communication stack.
In terms of communication, DiComm abstracts RDMA and TCP interactions for both homogeneous and heterogeneous chip-to-chip communication. The device-direct RDMA mode notably bypasses host memory, reducing cross-chip communication latency by up to 9.94× compared to conventional CPU-mediated TCP/IP approaches.
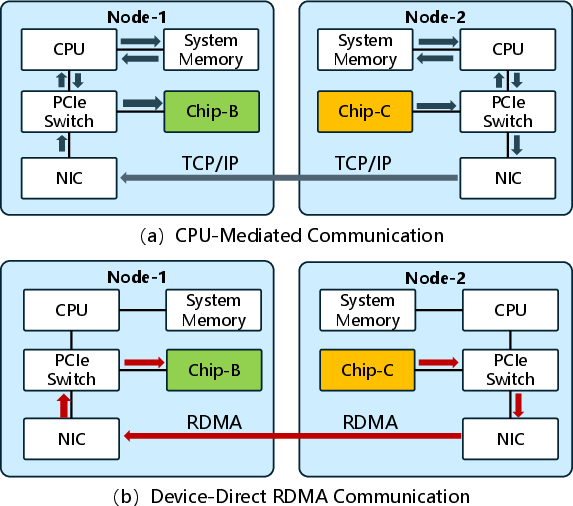
Figure 4: Device-direct RDMA communication versus CPU-mediated TCP, with the former substantially reducing latency and transfer path complexity.
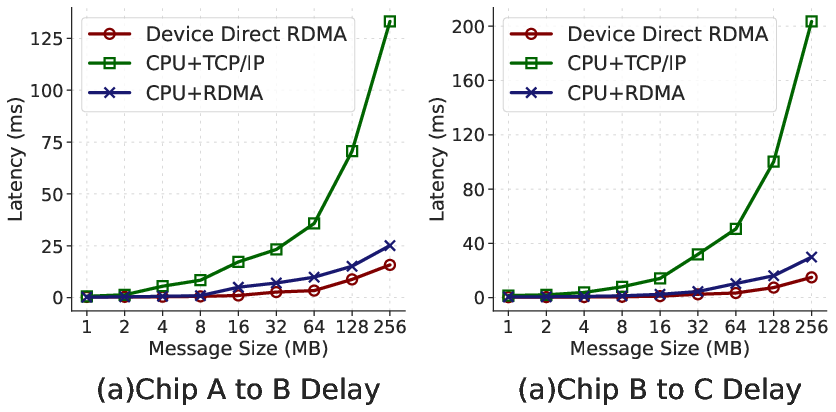
Figure 5: Empirical comparison of cross-chip communication latency across strategies, with device-direct RDMA outperforming TCP.
DiTorch incorporates modules for offline and real-time precision evaluation, execution profiling, and overflow detection. Rigorous operator alignment tests on Chips A, B, C, and D against the NVIDIA A100 demonstrated Mean Relative Error (MRE) below 1.5% across all chips, ensuring numerically stable and consistent training.
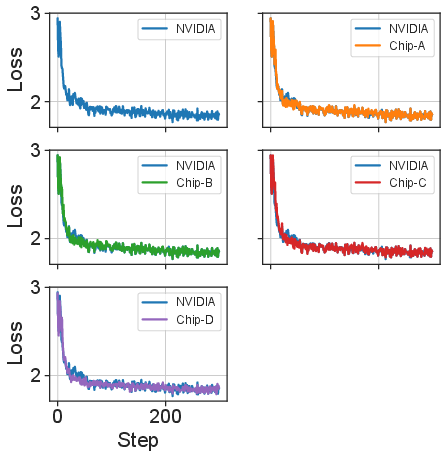
Figure 6: Loss curve alignment across Chips A, B, C, D and NVIDIA A100 over 300 iterations, confirming precision congruence.
HeteroPP: Distributed Parallelism on Hyper-Heterogeneous Chips
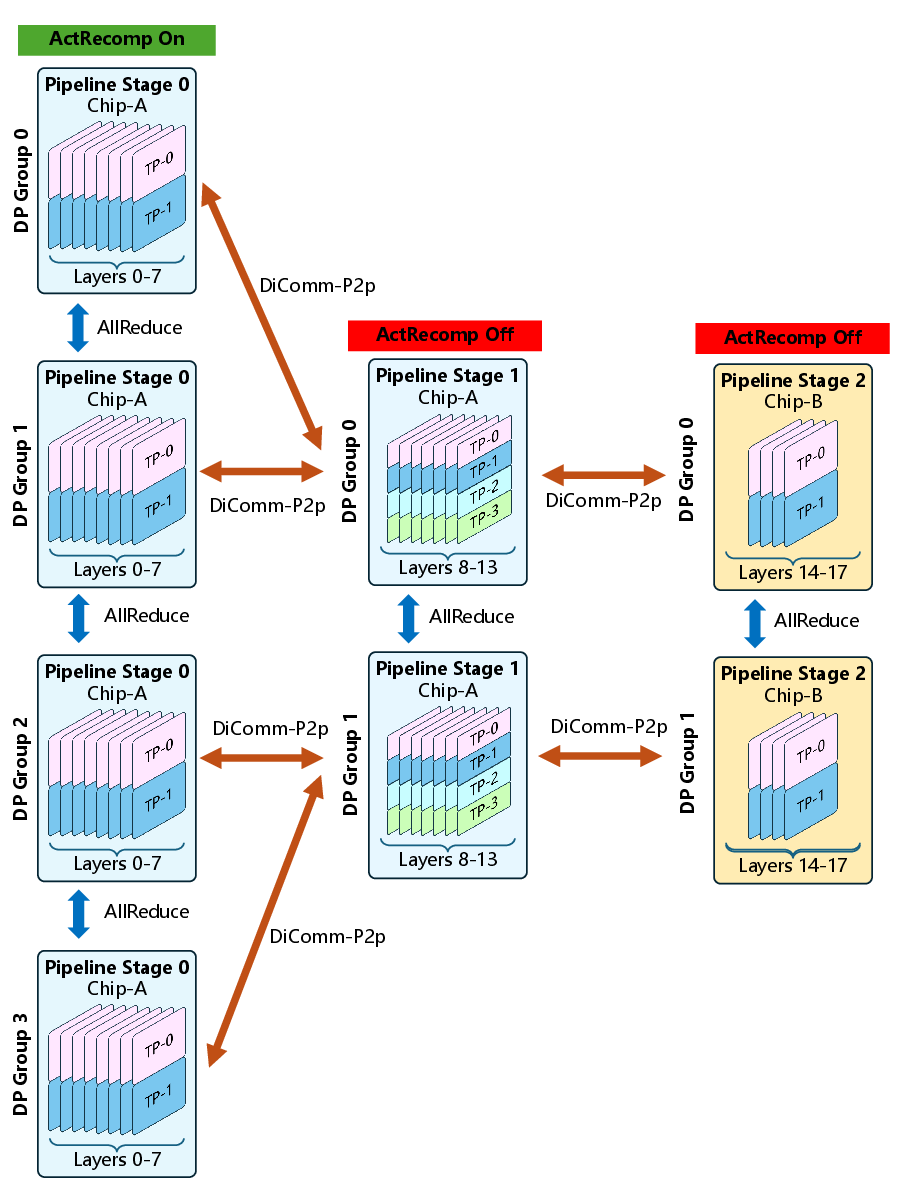
Pipeline parallelism is extended and tailored for hyper-heterogeneous clusters via the HeteroPP framework. Each stage comprises homogeneous chip nodes, with mapping order dictated by descending memory capacity. The framework enables:
HeteroAuto: Automated Parallel Strategy Search
HeteroAuto implements a cost-model-based depth-first search (DFS) approach for optimizing parallel strategy configurations. The search space spans pipeline stage allocations, tensor/data parallel degrees, layer distribution, and recomputation status per chip type. The cost model estimates iteration time with detailed profiling of chip capacities and communication characteristics, subject to memory safety constraints.
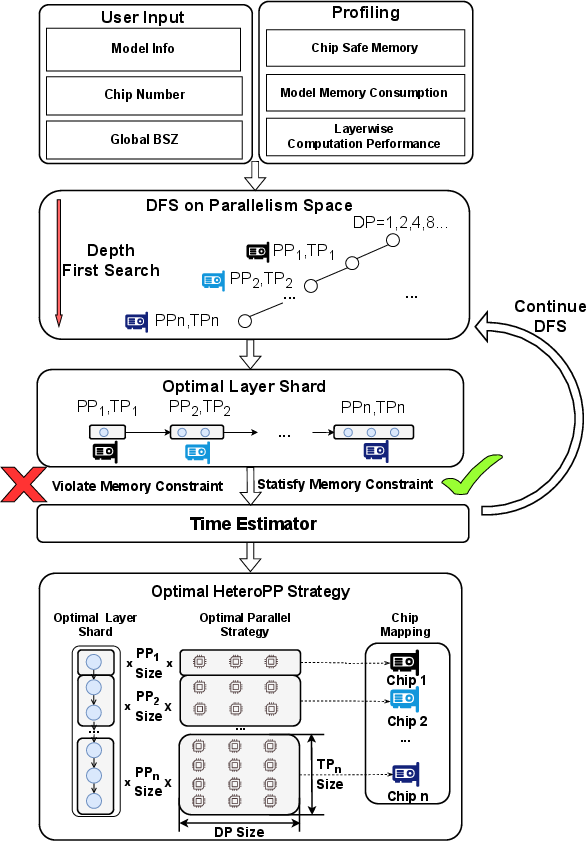
Figure 8: HeteroAuto workflow, representing the strategy search process for heterogeneous parallelism.
Topology-Aware Communication and Activation Resharding
To further optimize inter-stage communication, activation resharding adopts a topology-aware method, leveraging affinity NIC assignments within chip servers and combining send/recv with all-gather operations. This maximizes available bandwidth and minimizes cross-node transfer volume, especially beneficial in environments with heterogeneous NIC/PCIe configurations.
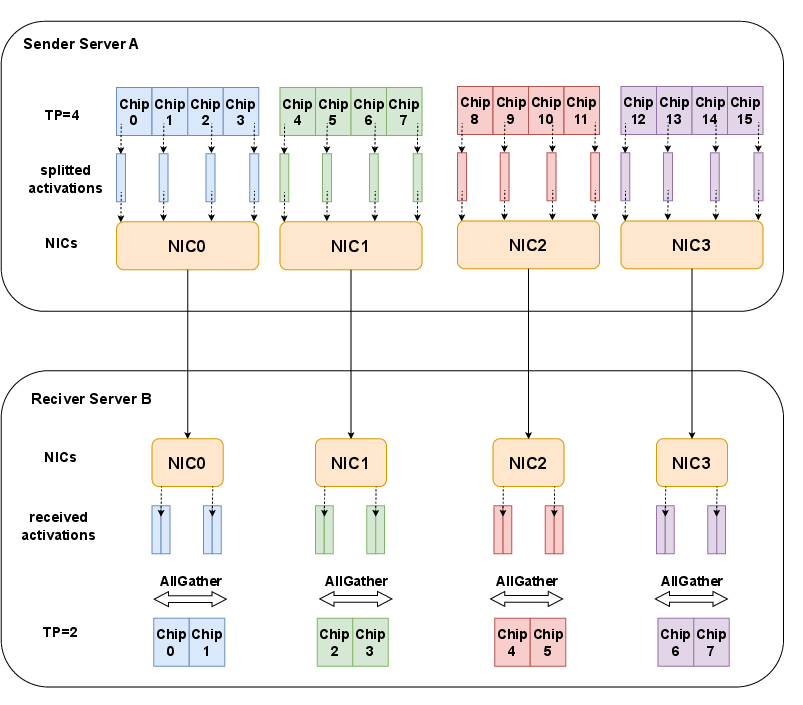
Figure 9: Illustration of topology-aware activation resharding between servers with inhomogeneous TP sizes and NIC affinities.
Empirical Evaluations and Results
Experiments were conducted on clusters with up to 1,024 chips spanning four architectures, training a 100B-parameter model. Chips with higher compute power but lower memory (e.g., Chip-D) were efficiently integrated, with stage allocation favoring memory-rich chips for early pipeline stages. Training throughput (tokens per chip per second, TGS) was evaluated for both homogeneous and heterogeneous settings.
- HeteroSpeedupRatio reached 109.03% (Exp-A-2; 768 chips, 3 types) and 104.29% (Exp-B-2; 1024 chips, 4 types) relative to the sum of individual baseline throughputs, indicating superlinear speedup.
- Strategy search overhead was negligible: 0.62 s (Exp-A), 5.48 s (Exp-B), 12.29 s (Exp-C) on a single-threaded CPU.
- Device-direct RDMA communication yielded substantial gains over CPU-mediated TCP, especially in small-scale settings.
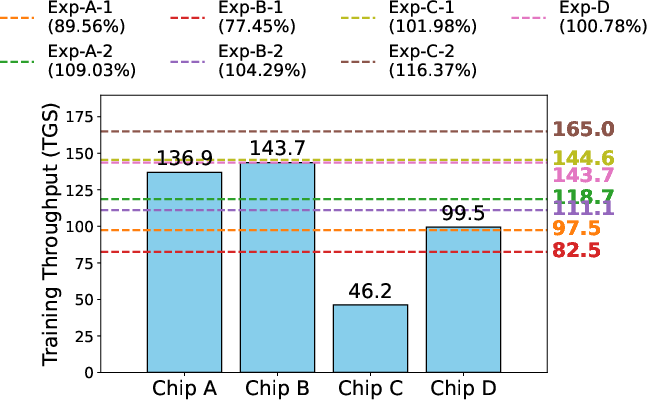
Figure 10: Training throughput benchmarking for homogeneous and heterogeneous setups, with HeteroSpeedupRatio exceeding baseline in superlinear regimes.
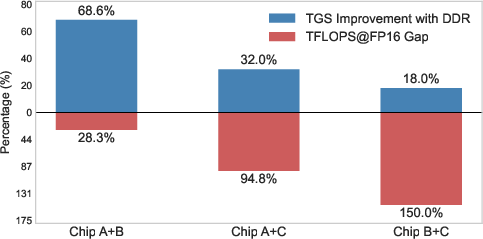
Figure 11: End-to-end small-scale training comparison with/without device-direct RDMA, highlighting communication method impact.
Implications and Prospects
The H2 framework sets a precedent for efficient LLM training on massively diverse hardware pools, demonstrating both practical and theoretical significance:
- Practically, H2 enables organizations to utilize legacy and new chips jointly, maximizing resource efficiency and reducing idle costs.
- Theoretically, H2's modular operator alignment and auto-parallel search design provide a template for general-purpose distributed training on arbitrary hardware.
- Superlinear speedup claims underscore the potential for hyper-heterogeneous resource pooling to outperform homogeneous high-end setups.
- The negligible search overhead and PyTorch compatibility facilitate real-world deployment.
- Topology-aware communication designs may inspire further research into cross-hardware optimization at the OS/network stack level.
Future research directions may include extending the framework to incorporate even greater architectural diversity (e.g., ASICs, FPGAs), adaptive real-time strategy reconfiguration, and tighter integration with hardware schedulers for dynamic load balancing.
Conclusion
The paper proposes H2, a unified framework for scalable and efficient LLM training in hyper-heterogeneous environments exceeding 1,000 chips. Through DiTorch's operator/runtime abstraction, DiComm's device-direct RDMA, HeteroPP's pipeline parallelism mapping, HeteroAuto's auto-strategy search, and topology-aware communication optimization, H2 achieves numerically robust and high-throughput multi-chip training. Empirical evaluations demonstrate superlinear efficiency gains, minimal search overhead, and seamless integration of heterogeneous resources, establishing H2 as a robust approach for efficient large-scale distributed LLM training (2505.17548).