- The paper introduces the AgentFail dataset and taxonomy to systematically diagnose failures in LLM-driven agentic systems.
- The benchmark demonstrates that structured taxonomy guidance boosts diagnostic accuracy from 8.3%-13.0% to 24.1%-33.6%.
- It highlights design principles like modular prompt design and explicit validation to build more robust multi-agent systems.
The paper "Diagnosing Failure Root Causes in Platform-Orchestrated Agentic Systems: Dataset, Taxonomy, and Benchmark" (2509.23735) presents a comprehensive study into failure diagnostics for LLM-driven agentic systems. The research introduces a dataset, taxonomy, and benchmark aimed at improving the reliability of such systems. This essay will explore the key components of the study, discussing the dataset, the taxonomy of failure root causes, the benchmarking approach for root cause identification, and implications for future developments.
The AgentFail Dataset
The study begins by introducing the "AgentFail" dataset, composed of 307 failure logs from various platform-orchestrated agentic systems. These systems are built using low-code platforms that enable rapid development and deployment of multi-agent solutions without requiring extensive programming expertise. The dataset includes detailed annotations linking each failure with its root cause, derived through a combination of automated logging and expert analysis.
System Selection and Data Collection
Agentic systems in the study span a variety of task categories, such as software development, information retrieval, and task planning. The data collection process involved controlled runs and community-contributed logs. These logs capture the full conversational trace of failed tasks, the system workflows, and expert annotations identifying the root cause of each failure.

Figure 1: Failure Root Cause Taxonomy.
Taxonomy of Failure Root Causes
The paper develops a comprehensive taxonomy of failure root causes, categorized into agent-level, workflow-level, and platform-level failures (Figure 1). This taxonomy aids in the fine-grained identification of failures, providing a structured approach to diagnose and address the root causes of system failures:
- Agent-Level Failures: These include issues like response format errors, knowledge limitations, and prompt design defects, primarily stemming from the underlying LLMs.
- Workflow-Level Failures: These pertain to issues in coordination among agents, such as missing input validation and unreasonable node dependencies.
- Platform-Level Failures: These are attributed to the underlying platform infrastructure, including network fluctuations and service unavailability.
The taxonomy serves as a guide for LLMs in automated root cause detection, enhancing their diagnostic accuracy.
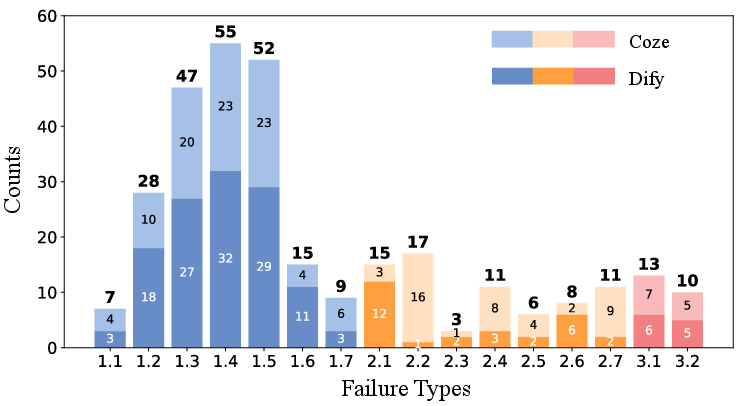
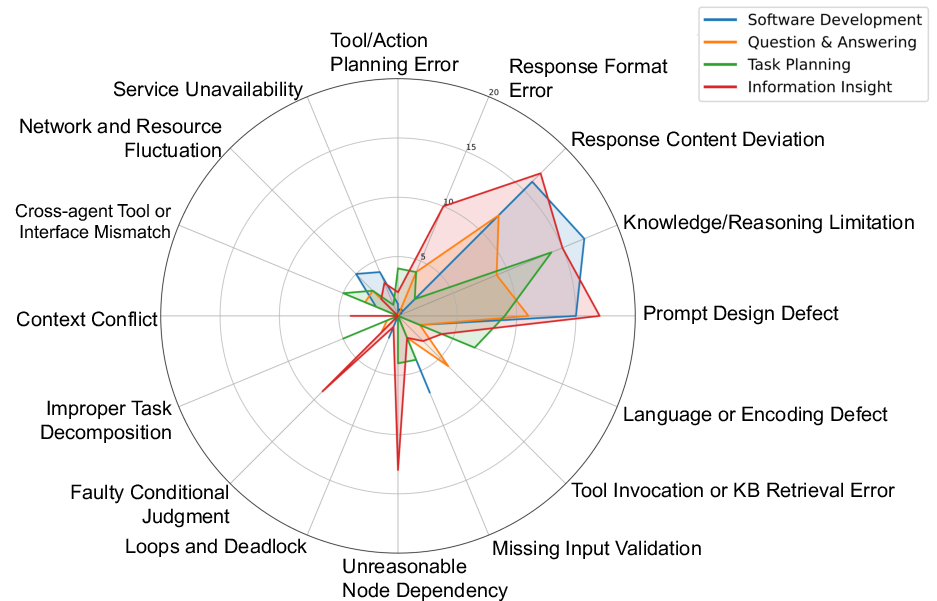
Figure 2: Statistics of failure root cause per category.
Root Cause Distribution and Analysis
The statistical analysis of the dataset, illustrated in Figure 2, reveals that agent-level failures dominate, particularly knowledge limitations and prompt design defects. Workflow-level failures, although less frequent, present critical bottlenecks, with input validation and node dependencies being common issues. Platform-level failures, while less common, can be particularly destructive when they occur.
Benchmark for Root Cause Identification
Leveraging the dataset and taxonomy, the study implements a benchmark to evaluate the effectiveness of using LLMs for automated root cause identification. Various LLMs, including gpt-4o, LLaMA, and DeepSeek, were tested under two scenarios: with and without the taxonomy guidance.
Methodologies Employed
- All-at-Once: LLMs are provided with the full failure log and tasked with identifying the root cause in one go.
- Step-by-Step: LLMs examine each segment of the log sequentially until the root cause is identified.
- Binary Search: This method divides the log into segments, recursively narrowing down to the section containing the root cause.
The inclusion of the taxonomy improved the LLMs' accuracy from approximately 8.3%-13.0% to about 24.1%-33.6%, illustrating the taxonomy's substantial utility in enhancing automated diagnostics.
Implications and Future Directions
The paper concludes with several guidelines aimed at improving the reliability of platform-orchestrated agentic systems. Key recommendations include:
- Clear role specification and modular prompt design to reduce planning errors.
- Incorporating explicit validation to prevent cascading errors.
- Implementing comprehensive checks and fallback mechanisms.
- Adopting progressive workflow designs to build more robust systems.
The study underscores the importance of addressing failure root causes at multiple levels to enhance the robustness of agentic systems. Future developments could explore deeper integration of automated diagnostic tools within these platforms, leveraging the findings to build more resilient multi-agent frameworks.
Conclusion
This research provides insightful contributions to the domain of agentic systems by systematically categorizing and diagnosing failure root causes using a novel dataset and taxonomy. The benchmark results demonstrate the potential for using structured guidance to improve LLM-based diagnostics. The findings offer practical guidelines and lay the groundwork for future innovations that enhance the reliability and efficiency of platform-orchestrated agentic systems.

