- The paper's main contribution is the development of SPF, a zero-shot UAV navigation framework that uses frozen VLMs to annotate 2D waypoints, geometrically lifting them to generate 3D control commands.
- It employs adaptive step-size scaling and a closed-loop control methodology to achieve high success rates (over 92%) and efficient navigation in both simulation and real-world experiments.
- Robust generalization and obstacle avoidance are demonstrated through ablation studies, confirming the efficacy of structured 2D waypoint prompting and adaptive control in diverse environments.
See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
Introduction and Motivation
The paper introduces See, Point, Fly (SPF), a training-free framework for aerial vision-and-language navigation (AVLN) that leverages frozen vision-LLMs (VLMs) to control unmanned aerial vehicles (UAVs) in a zero-shot manner. SPF reframes the action prediction problem in AVLN as a 2D spatial grounding task, where the VLM is prompted to annotate 2D waypoints on the input image, which are then geometrically lifted to 3D displacement vectors for UAV control. This approach circumvents the limitations of prior methods that treat action prediction as a text generation task, which are ill-suited for high-precision, real-time control and generalization to novel environments or instructions.
SPF is designed to operate in closed-loop, enabling UAVs to follow dynamic targets and adapt to dynamic environments without any task-specific training or policy optimization. The framework is evaluated extensively in both high-fidelity simulation and real-world settings, demonstrating substantial improvements over state-of-the-art baselines in terms of success rate and efficiency.

Figure 1: Zero-shot language-guided UAV control in dynamic and complex environments, with all waypoints generated directly by the vision-LLM without task-specific training.
Methodology
System Architecture
SPF consists of three main components: (1) VLM-based obstacle-aware action planning, (2) adaptive travel distance scaling, and (3) a reactive control loop for execution. The pipeline operates as follows:
- Perception and Planning: At each timestep, the UAV captures an egocentric RGB image and receives a free-form language instruction. The frozen VLM is prompted with this input and outputs a structured JSON containing a 2D waypoint (pixel coordinates) and a discrete depth cue, as well as any detected obstacle bounding boxes.
- 2D-to-3D Lifting: The predicted 2D waypoint and depth cue are unprojected via the pinhole camera model into a 3D displacement vector in the UAV's body frame. This vector is decomposed into low-level control primitives (yaw, pitch, throttle).
- Adaptive Step-Size Controller: The discrete depth cue is mapped to an adaptive step size using a nonlinear scaling function, allowing the UAV to take larger strides in open space and smaller, more cautious steps near obstacles or targets.
- Closed-Loop Execution: The control primitives are converted into velocity-duration pairs and sent to the UAV in a closed-loop, enabling continuous replanning and robust adaptation to dynamic environments.

Figure 2: Pipeline overview: camera frame and user instructions are processed by a frozen VLM, which outputs a 2D waypoint and obstacle boxes; these are converted to low-level velocity commands for UAV control in a closed-loop.
Control Geometry and Policy Mapping
The transformation from image-space waypoints to 3D actions is formalized as follows. Given a 2D waypoint (u,v) and an adaptive step size dadj, the 3D displacement vector (Sx,Sy,Sz) is computed as:
Sx=u⋅dadj⋅tan(α),Sy=dadj,Sz=v⋅dadj⋅tan(β)
where α and β are the camera's horizontal and vertical half field-of-view angles. The resulting vector is decomposed into yaw, pitch, and throttle commands for the UAV.
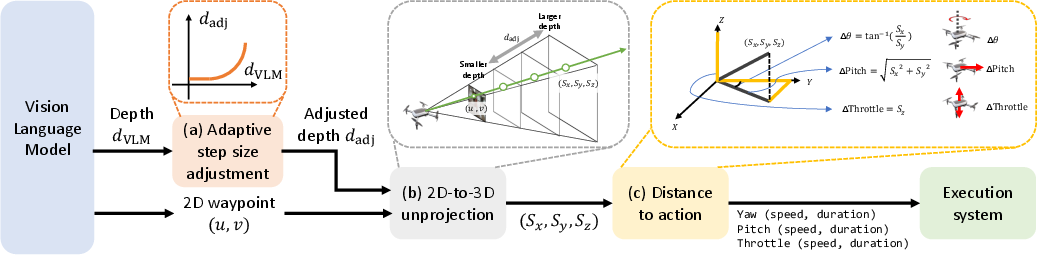
Figure 3: Control-geometry details: VLM predicts a 2D waypoint and depth cue, which are adaptively scaled and unprojected to 3D displacement, then mapped to control primitives.
Obstacle Avoidance and Generalization
Obstacle avoidance is achieved by constraining the VLM to generate waypoints that do not intersect with detected object bounding boxes. Notably, SPF generates these bounding boxes directly from the VLM in a single pass, enabling zero-shot generalization to arbitrary objects and reducing system latency compared to external detectors.
Experimental Results
Simulation and Real-World Evaluation
SPF is evaluated on the DRL simulator and a real-world DJI Tello EDU platform across 23 simulated and 11 real-world tasks, spanning navigation, obstacle avoidance, long-horizon planning, reasoning, search, and follow categories. Performance is measured by success rate (SR) and completion time.
SPF achieves a 93.9% success rate in simulation and 92.7% in real-world experiments, outperforming TypeFly (0.9% sim, 23.6% real) and PIVOT (28.7% sim, 5.5% real) by large margins. SPF also demonstrates superior efficiency, with significantly reduced completion times, especially in complex scenarios.



Figure 4: Qualitative comparison of flight trajectories in simulation; SPF produces smoother, more direct paths and higher task completion than baselines.
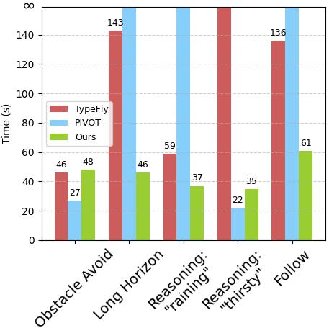
Figure 5: Real-world flight trajectories; SPF consistently reaches targets and avoids obstacles, while baselines often fail or deviate.
Ablation Studies
Ablation experiments confirm the critical role of structured 2D waypoint prompting and adaptive step-size scaling. Plain VLM text generation achieves only 7% SR, while PIVOT (visual prompting) reaches 40%. SPF with 2D waypoint labeling achieves up to 100% SR with strong VLMs (Gemini 2.5 Pro, GPT-4.1), and 87–93% with lighter models, demonstrating robustness across VLM backbones.
The adaptive step-size controller halves completion times and improves or maintains success rates compared to fixed-step baselines, confirming its efficacy for efficient navigation.



Figure 6: Visual examples of real-world scenarios for long-horizon and reasoning tasks used in the ablation study of the adaptive step-size controller.
Implementation Considerations
- Latency: The end-to-end system operates at 0.3–1 Hz for VLM inference and 10 Hz for low-level control, with total latency of 1.5–3 seconds, primarily due to VLM processing.
- Hardware: The approach is lightweight and hardware-agnostic, demonstrated on commodity UAVs without external depth sensors or specialized detectors.
- Generalization: SPF is model-agnostic and works with a range of VLMs, including Gemini, GPT-4.1, Claude, and Llama 4, with only minor performance degradation on less capable models.
- Limitations: VLM hallucinations, imprecise grounding for small/distant targets, prompt sensitivity, and VLM inference latency limit reactivity to highly dynamic obstacles. The adaptive step heuristic provides only implicit depth, which can be imprecise.
Theoretical and Practical Implications
SPF demonstrates that high-level spatial reasoning and language understanding can be effectively outsourced to large, frozen VLMs, while low-level control is handled by lightweight geometric controllers. This decoupling enables robust zero-shot generalization to novel environments and instructions, sidestepping the need for task-specific data collection and policy optimization. The structured 2D waypoint grounding approach is shown to be superior to text-based or skill-library-based action prediction, both in precision and generalization.
The results suggest that VLMs, when properly prompted and integrated with geometric controllers, can serve as universal perception and planning modules for embodied agents, including UAVs. This has significant implications for the deployment of autonomous aerial systems in unstructured, real-world environments, where data scarcity and task diversity are major challenges.
Future Directions
Key avenues for future research include:
- Reducing VLM inference latency for improved reactivity to dynamic obstacles.
- Enhancing perception robustness and grounding precision, especially for small or distant targets.
- Exploring VLM fine-tuning or adaptation for improved spatial reasoning and control.
- Developing more sophisticated exploration and search strategies.
- Integrating additional sensory modalities (e.g., inertial, depth) for improved safety and reliability.
Conclusion
SPF establishes a new state of the art for zero-shot, language-guided UAV navigation by reframing action prediction as a 2D spatial grounding problem and leveraging frozen VLMs for high-level reasoning. The framework achieves high success rates and efficiency across diverse tasks and environments, outperforming prior baselines by substantial margins. SPF's model-agnostic, training-free design and strong empirical results highlight the potential of VLM-driven control architectures for universal, scalable, and robust embodied AI.