- The paper introduces the DAWN framework, unifying diffusion-based pixel motion planning with language-conditioned robotic control.
- It employs a two-stage architecture with a Motion Director that predicts dense pixel motions and an Action Expert that generates low-level robot actions.
- Experimental results on CALVIN, MetaWorld, and real-world tasks validate its data efficiency, robustness, and state-of-the-art performance.
Pixel Motion Diffusion for Robot Control: The DAWN Framework
Introduction
The paper introduces DAWN (Diffusion is All We Need), a unified, two-stage diffusion-based framework for language-conditioned robotic manipulation. DAWN leverages structured pixel motion as an explicit, interpretable intermediate representation, bridging high-level motion intent and low-level robot action. Both the high-level (Motion Director) and low-level (Action Expert) controllers are instantiated as diffusion models, enabling end-to-end training and modularity. The approach is evaluated on the CALVIN and MetaWorld simulation benchmarks, as well as real-world single-arm and bimanual manipulation tasks, demonstrating state-of-the-art performance and strong data efficiency.
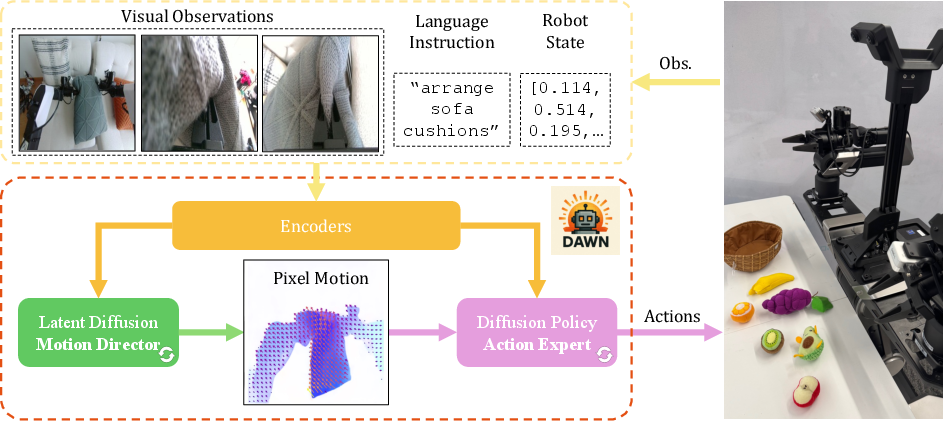
Figure 1: Overview of DAWN with two major diffusion modules. First, observations are encoded into conditional embeddings; Based on that, a latent diffusion Motion Director generates a pixel motion representation, which the diffusion policy Action Expert uses to create robot actions.
Methodology
Two-Stage Diffusion Architecture
DAWN decomposes visuomotor control into two stages:
- Motion Director: A latent diffusion model predicts dense pixel motion fields from current visual observations and language instructions. This module operates in the latent space of a pretrained VAE, conditioned on both static and gripper camera views, as well as the instruction embedding. The output is a three-channel image encoding horizontal and vertical pixel displacements, providing a structured and interpretable representation of desired scene dynamics.
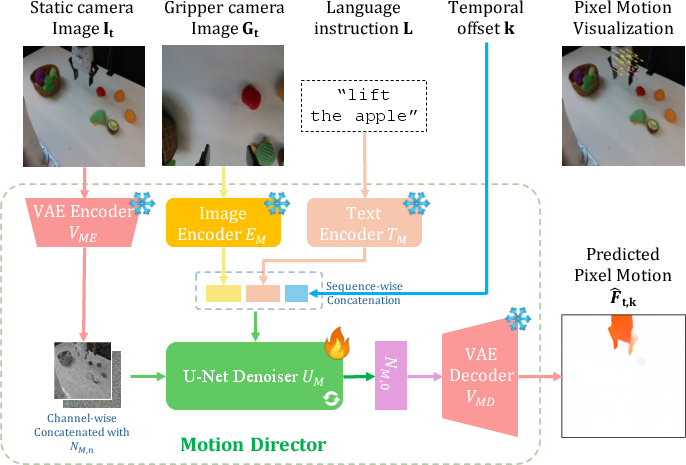
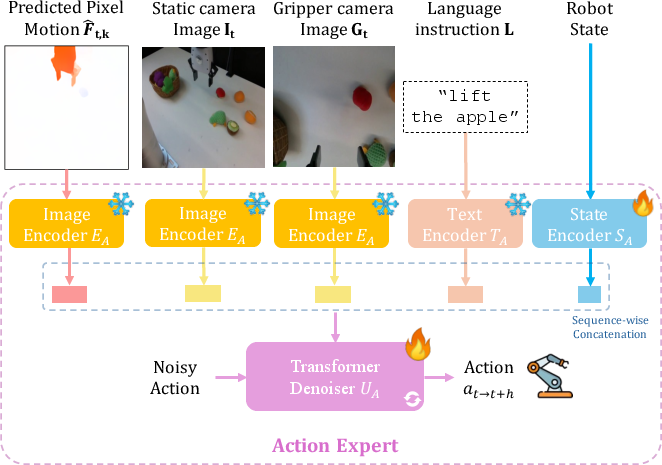
Figure 2: Architecture of Motion Director. The model encodes the static camera view and denoises it with a U-Net, conditioned on the gripper view, language instruction with a temporal offset. The output is decoded into predicted pixel motions, providing interpretable motion representations.
- Action Expert: A diffusion policy transformer generates low-level robot actions, conditioned on the predicted pixel motion, current visual observations, language instruction, and robot state. The architecture employs a multimodal encoder stack (visual, text, state) and a denoising transformer, with cross-attention to all modalities at each diffusion step.
Both modules are trained with mean squared error noise estimation losses. During training, ground-truth pixel motions are computed using RAFT optical flow between frames. The modular design allows for parallel training and independent upgrades of each component.
Training and Inference
- Motion Director is initialized from a pretrained latent diffusion model (e.g., Stable Diffusion), with additional conditioning layers for the gripper view and language input.
- Action Expert uses a pretrained ConvNeXt-S (DINOv3) visual encoder and T5-small text encoder, with randomly initialized state encoder and policy head.
- At inference, observations are encoded, Motion Director generates a pixel motion plan, and Action Expert produces a sequence of executable actions. The process is repeated in a closed-loop fashion.
Experimental Results
CALVIN Benchmark
DAWN achieves state-of-the-art results on the CALVIN ABC→D long-horizon manipulation benchmark, both with and without external robotic data. Notably, DAWN matches or surpasses larger VLA models despite using fewer parameters and less data. The explicit pixel motion interface is shown to be critical: ablations removing pixel motion or gripper view conditioning result in significant performance drops.
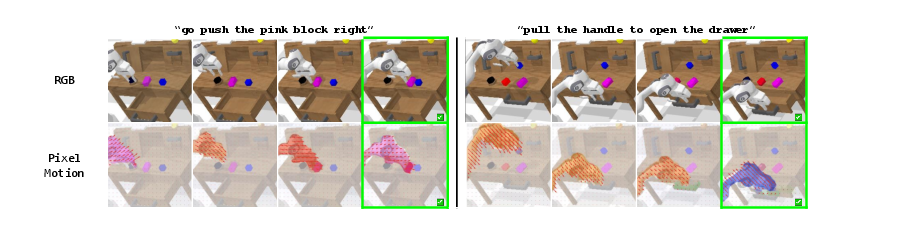
Figure 3: CALVIN rollout examples. Two example rollouts of DAWN in CALVIN environment. The first row is the sequence of RGB images, and the second row is the visualization of the corresponding pixel motions predicted by Motion Director.
On 11 challenging MetaWorld tasks, DAWN outperforms prior pixel/point trajectory and VLA baselines, especially on semantically similar but visually distinct tasks (e.g., open-door vs. close-door). The results highlight the benefits of scalable language-video pretraining and the action-expert design for improved semantic and state awareness.
Real-World Single-Arm Manipulation
DAWN demonstrates robust sim-to-real transfer with minimal finetuning on a 1k-episode real-world dataset. Compared to strong baselines (Diffusion Policy, π0, VPP), DAWN achieves higher success rates in object-specific lift-and-place tasks and exhibits fewer semantic errors (e.g., picking the wrong object). The modular pixel motion interface is shown to be both interpretable and effective for real-world deployment.

Figure 4: Real world rollout examples. Given a task of ``lift the apple'', the first row shows the rollout image sequence by pi_0 with LoRA finetuned, which lifts the wrong object, kiwi. The second row shows a successful episode by our method in the same environment setting, and the third row is the visualization of the corresponding pixel motions predicted by Motion Director.
Bimanual Manipulation
DAWN is extended to bimanual settings using the Galaxea R1-Lite platform. The approach achieves lower mean squared error in action prediction compared to baselines, and qualitative results show accurate pixel motion predictions for complex tasks such as "arrange sofa cushions" and "chair push and place".

Figure 5: Galaxea pixel motion prediction examples. The first column shows the one test image sequence given the task of arrange sofa cushions''. The second column shows the test image sequence given the task ofchair push and place''. Each group shows the original head-camera observation and the visualizations of corresponding pixel motions predicted by Motion Director.
Ablation Studies
Ablations on the CALVIN benchmark confirm:
- Pixel motion as intermediate: Outperforms RGB goal conditioning and non-pretrained variants.
- Gripper view: Improves performance, especially for occlusion and fine-grained manipulation.
- Diffusion steps: Performance saturates at 25 steps; fewer steps degrade results.
Implementation Considerations
- Resource requirements: Training is feasible on 4×A6000 GPUs; Motion Director and Action Expert can be trained in parallel.
- Pretraining: Leveraging large-scale pretrained vision and LLMs is critical for data efficiency and transfer.
- Modularity: The explicit pixel motion interface allows independent upgrades and facilitates interpretability.
- Deployment: The approach is robust to domain shift and can be finetuned with limited real-world data.
Implications and Future Directions
DAWN demonstrates that the performance gap between multi-stage tracking pipelines and VLA/latent-feature hierarchies is not inherent to the framework, but rather due to underpowered high- and low-level components. By instantiating both stages with modern diffusion models and leveraging strong pretrained backbones, DAWN achieves high data efficiency, interpretability, and robust transfer. The results suggest that structured intermediate representations, such as pixel motion, are a practical and scalable path for generalist robot control.
Future work may explore:
- Scaling to more diverse and unstructured real-world environments.
- Integrating additional sensory modalities (e.g., depth, tactile).
- Further optimizing inference speed and sample efficiency.
- Extending to multi-agent and multi-task settings.
Conclusion
DAWN establishes a new state-of-the-art for language-conditioned robot control by unifying high-level motion planning and low-level action generation via diffusion models and explicit pixel motion. The framework is modular, interpretable, and data-efficient, with strong empirical results across simulation and real-world domains. The findings motivate renewed attention to structured intermediate representations and diffusion-based policies for scalable, robust, and generalizable robot learning.

