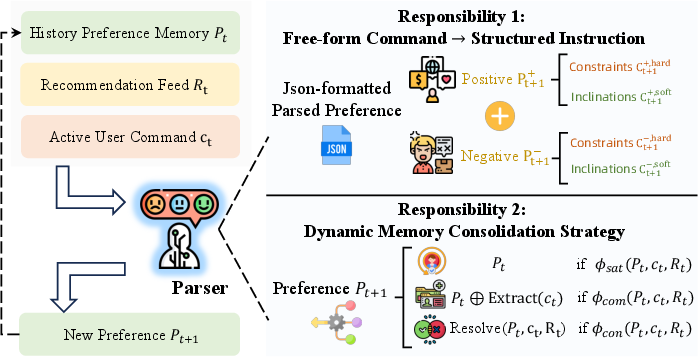
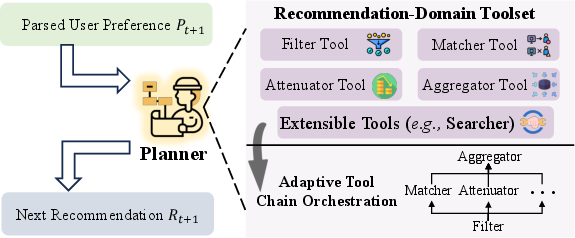
- The paper introduces RecBot, an interactive recommendation agent that leverages active natural language commands to model nuanced user preferences and adjust policies in real time.
- RecBot employs a dual-agent architecture with parser and planner agents, integrating dynamic memory consolidation and modular tool chains for precise recommendation updates.
- Empirical evaluations show RecBot outperforms traditional approaches on multiple datasets, boosting user satisfaction and business metrics.
Interactive Recommendation Agent with Active User Commands: Technical Summary and Implications
Motivation and Paradigm Shift
Traditional recommender systems are fundamentally limited by their reliance on passive, coarse-grained feedback mechanisms (e.g., clicks, likes/dislikes), which fail to capture the nuanced motivations and intentions underlying user behavior. This results in ambiguous preference modeling, indiscriminate attribution of item characteristics, and persistent misalignment between user intent and system interpretation. The paper introduces the Interactive Recommendation Feed (IRF) paradigm, which enables users to issue free-form natural language commands directly within mainstream recommendation feeds, thereby transforming the interaction from passive consumption to active, user-driven control.
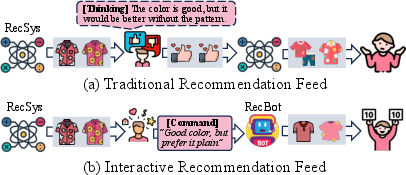
Figure 1: Comparison between traditional and novel interactive recommendation feeds. IRF enables direct, free-form natural language commands for real-time policy adjustment.
RecBot Framework: Architecture and Components
The RecBot framework operationalizes IRF via a dual-agent architecture:
The toolset design is extensible, supporting seamless integration of additional modules (e.g., searcher tools for trending topics) via standardized interfaces, consistent with Model Context Protocol (MCP) principles.
Multi-Agent Optimization and Deployment
RecBot employs simulation-augmented knowledge distillation to transfer reasoning capabilities from closed-source teacher LLMs (e.g., GPT-4.1) to cost-effective open-source student models (e.g., Qwen3-14B). Synthetic user-system interaction trajectories are generated via role-playing, enabling diverse, realistic training data for both parser and planner agents. The unified optimization objective minimizes negative log-likelihood over mixed agent-specific datasets, supporting efficient online inference and scalable deployment.
Empirical Evaluation
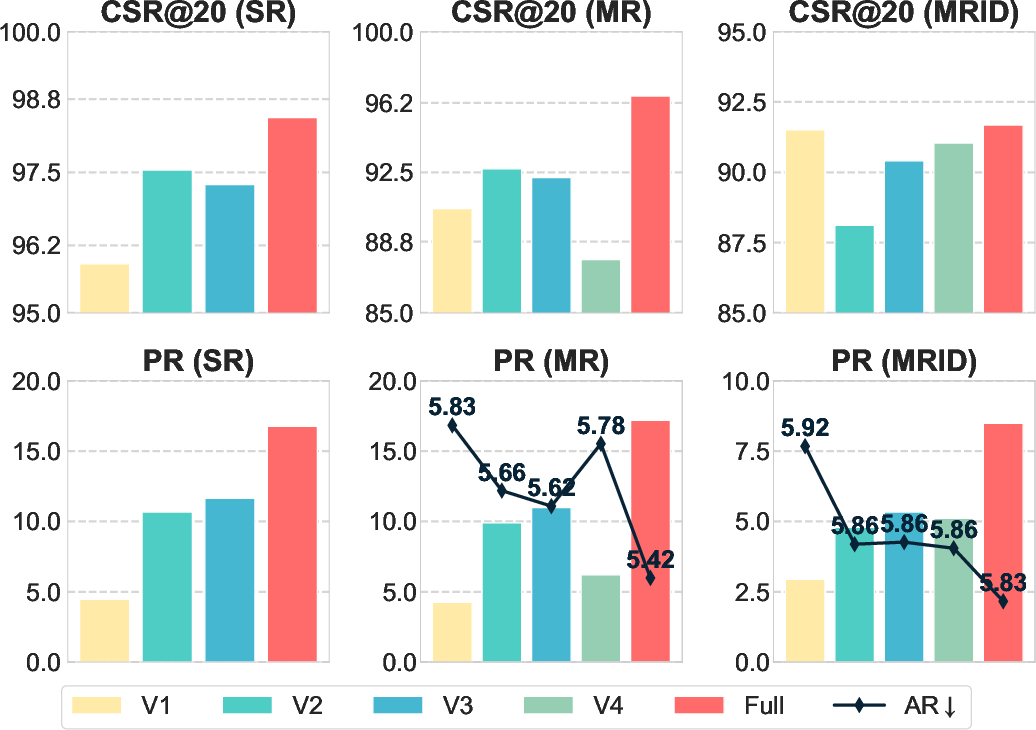
Offline Experiments
RecBot is evaluated on Amazon, MovieLens, and Taobao datasets across single-round, multi-round, and multi-round with interest drift scenarios. Metrics include Recall@N, NDCG@N, Condition Satisfaction Rate (CSR@N), Pass Rate (PR), and Average Rounds (AR).
Online Experiments
A three-month A/B test on a large-scale e-commerce platform demonstrates:
- User Experience: 0.71% reduction in Negative Feedback Frequency (NFF), 0.88% increase in Exposed Item Category Diversity (EICD), and 1.44% increase in Clicked Item Category Diversity (CICD).
- Business Impact: 1.28% increase in Add-to-Cart (ATC) and 1.40% increase in Gross Merchandise Volume (GMV).
- User Group Analysis: Consistent NFF reductions across user segments, with optimal improvements for users with moderate historical negative feedback.
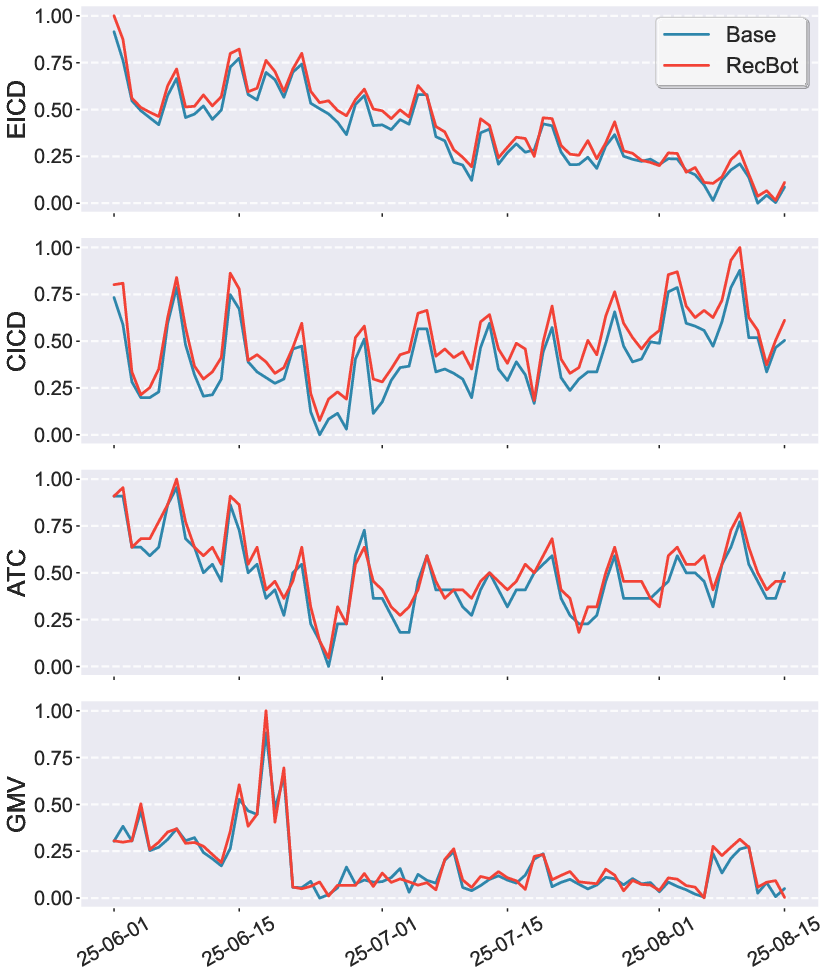
Figure 5: Online performance curves during three-month A/B testing, showing RecBot's improvements over baseline.
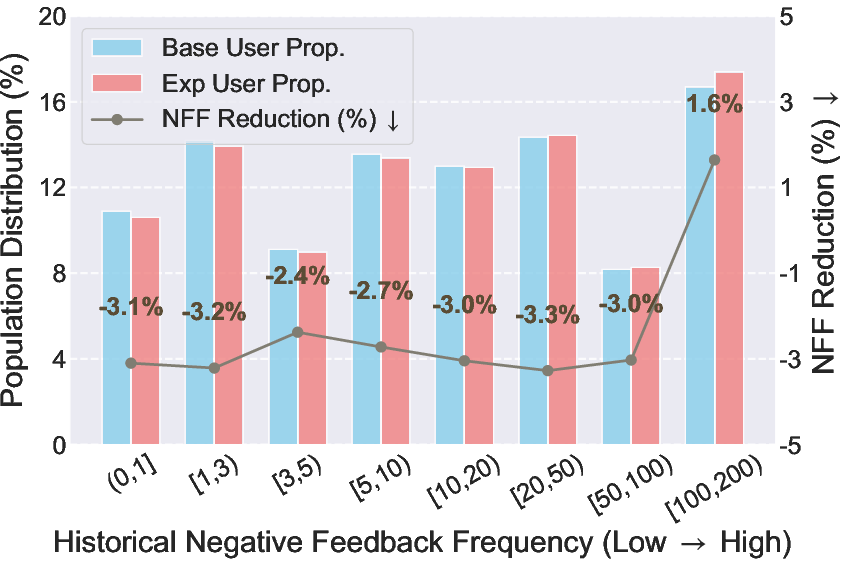
Figure 6: Online performance improvements across user groups split by historical negative feedback frequency.
- Command Fulfillment: 88.9% success rate in satisfying user commands (human evaluation), 87.5% (LLM-Judge), with 96.5% consistency between methods.
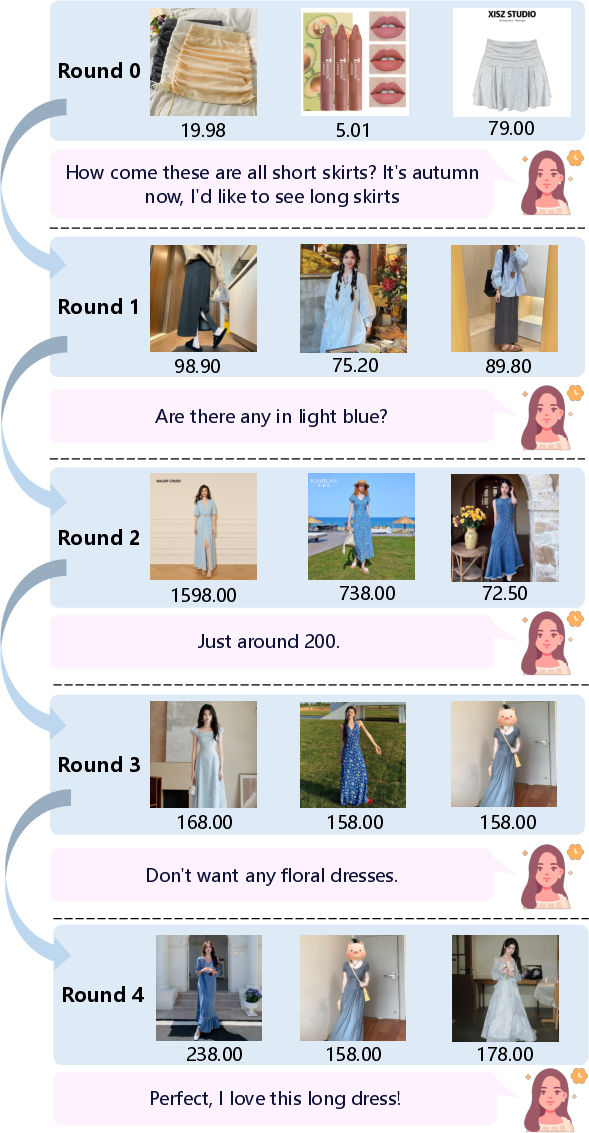
Figure 7: Case study of RecBot on production platform, demonstrating multi-round command fulfillment and adaptive policy adjustment.
Theoretical and Practical Implications
The IRF paradigm and RecBot framework represent a significant advancement in interactive recommendation, enabling direct, fine-grained user control over recommendation policies via natural language. The explicit modeling of both positive and negative preferences, dynamic memory consolidation, and modular tool orchestration collectively address the limitations of passive feedback and ambiguous preference inference. The simulation-augmented distillation approach provides a scalable pathway for deploying high-performing, cost-effective agents in production environments.
From a theoretical perspective, the results challenge the assumption that larger teacher models are always superior, highlighting the potential for student models to achieve or exceed teacher performance via targeted knowledge transfer. The modular agentic architecture aligns with emerging trends in agentic AI and tool-based reasoning, suggesting future directions in self-evolving, lifelong interactive agents.
Future Directions
Key avenues for further research include:
- Online learning mechanisms for continuous agent evolution via real-time user feedback.
- Enhanced personalized reasoning and explanatory capabilities.
- Integration of proactive anticipation modules for next-generation interactive recommender systems.
- Exploration of agentic reinforced evolution and multi-agent collaboration for improved adaptability and robustness.
Conclusion
The Interactive Recommendation Feed paradigm and RecBot framework address fundamental limitations in recommender systems by enabling user-controllable, command-aware recommendation experiences. Extensive empirical validation demonstrates substantial improvements in user satisfaction, content diversity, and business outcomes. The modular, multi-agent architecture and simulation-augmented optimization provide a robust foundation for scalable, production-ready interactive recommendation systems, with broad implications for the future of agentic AI in personalized content delivery.