- The paper introduces a unified CRS framework that leverages deep learning and reinforcement learning for context-aware, personalized recommendations.
- It integrates advanced modules like NLU, dialogue management, and natural language generation to dynamically update user preferences.
- Experimental results on the Yelp dataset show improved performance with higher success rates and reduced dialogue turns compared to baseline methods.
Conversational Recommender System
Conversational Recommender Systems (CRS) are emerging as vital components in the integration of recommendation techniques with dialogue systems for personalized user interactions. This paper presents a framework for building such systems, employing deep learning and reinforcement learning to make informed recommendations based on user-dialogue context.
Introduction
With the proliferation of intelligent digital assistants, the integration of conversational systems into the recommendation domain is increasingly pertinent. The CRS unifies the core elements of dialogue systems with recommendation methods, enabling systems to cater to user preferences through interactive sessions efficiently.
The CRS framework comprises three main components: Natural Language Understanding (NLU), Dialogue Management (DM), and Natural Language Generation (NLG). The NLU module is tasked with processing user inputs to update dialogue states continually. The DM module leverages reinforcement learning to optimize decision-making, thus enhancing user satisfaction and system efficiency. The NLG module generates responses that align with user intentions and system goals.
System Architecture
The architecture of the CRS integrates belief tracking, recommendation systems, and deep policy networks to optimize interactions and recommendations.

Figure 1: The conversational recommender system overview.
- Belief Tracker: Utilizes deep belief networks to parse user utterances, maintaining a dynamic representation of user preferences as facet-value pairs. LSTM networks encode sequence data to capture the evolving dialogue state, influencing recommendation precision.
- Recommender System: Implements a Factorization Machine to process user-item interactions and dialogue states. This system ranks potential recommendations based on historical and contextual data, optimizing candidate selection through facet-value analysis.
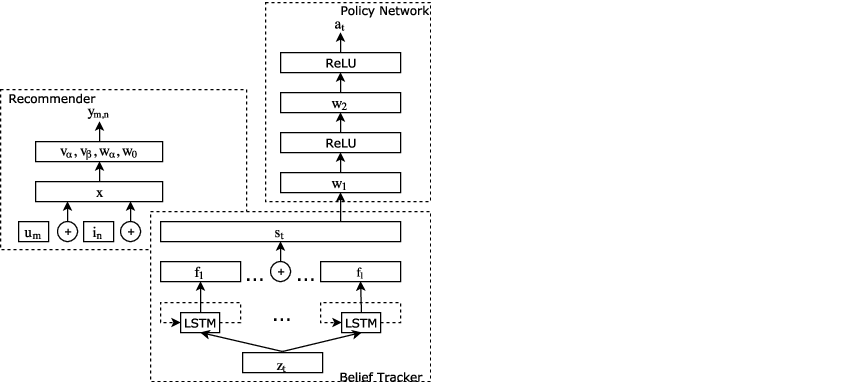
Figure 2: The structure of the proposed conversational recommender model. The bottom part is the belief tracker, the top left part is the recommendation model, and the top right part is the deep policy network.
- Deep Policy Network: Employs reinforcement learning (RL) techniques to determine optimal actions during dialogue sessions. The RL framework allows the system to adapt strategies that maximize long-term user engagement and conversion rates.
Experimental Setup
The paper explores both offline and online environments to evaluate system performance, utilizing simulated and real user data from customized datasets.
- Offline Experiments: Using the Yelp dataset, the system was evaluated on various aspects such as success rate, dialogue turn count, and recommendation accuracy. The RL-based approach outperformed traditional greedy methods, demonstrating enhanced robustness and adaptability to varied user interactions.
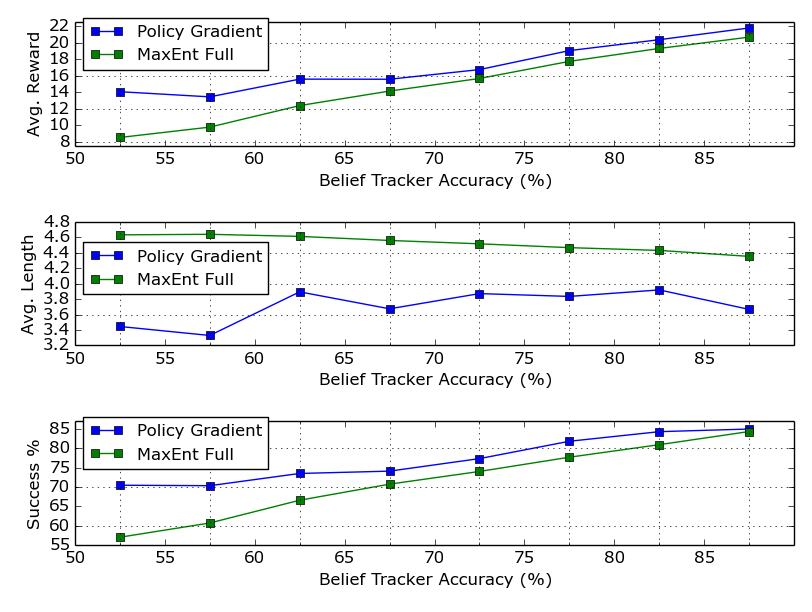
Figure 3: Model performances of three measures with different belief tracker accuracy.
- Recommendation Rewards: Three reward modeling strategies (Linear, NDCG, Cascade) were employed, with RL models consistently achieving higher metrics across different reward paradigms. This adaptability points to the system's potential in diverse commercial applications.
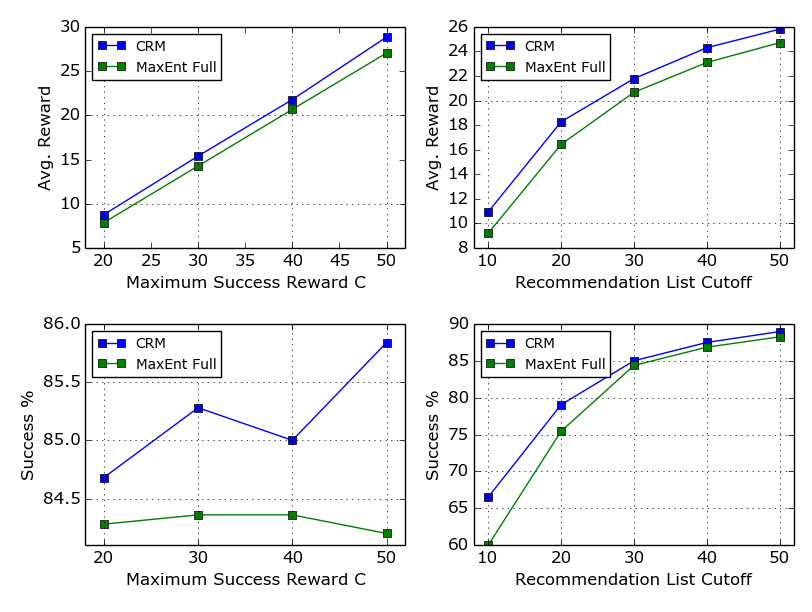
Figure 4: Comparison of CRM and the MaxEnt Full methods with different Maximum Success Reward C and stop threshold of the recommendation list.
- Online User Study: Real-world testing via crowdsourcing validated the system's efficacy in handling dynamic, natural language-based interactions, achieving significant success rates with lower computational overhead and improved user experience.
Conclusion
The CRS framework effectively combines dialogue systems and recommendation strategies, presenting a unified model capable of real-time personalized recommendations. Continuous learning and feedback loop integration enhance user interaction outcomes.
Future research should focus on expanding the action space to include more nuanced system responses, refining reward functions to account for multi-session interactions, and improving the belief tracker through advanced NLP techniques and models. This framework serves as a foundational step towards fully autonomous conversational agents in complex e-commerce and user-interaction domains.