- The paper introduces a comprehensive framework for generating culturally grounded synthetic data using translation-based, backtranslation, and retrieval-augmented strategies.
- The paper demonstrates that combining native speaker evaluation with LLM-based assessments achieves high data quality and effectively narrows resource gaps in low-resource Indic languages.
- The paper reveals that context-aware, culturally sensitive synthetic data can boost generative task performance and improve instruction-following capabilities in multilingual AI models.
Synthetic Data for Multilingual, Multi-cultural AI: Empirical Insights from Indic Languages
Introduction and Motivation
The paper addresses the persistent challenge of building AI systems that are both multilingual and culturally grounded, with a particular focus on low-resource languages. It critiques the prevailing English-centric paradigm in data curation, fine-tuning, and evaluation, arguing that such practices perpetuate global power imbalances and fail to capture linguistic and cultural diversity. The authors propose synthetic data generation as a viable strategy to supplement scarce resources, but emphasize that its effectiveness in multilingual and multicultural contexts is underexplored. The work introduces a comprehensive framework for synthetic data generation, quality assessment, and downstream evaluation, instantiated through the creation of the Updesh dataset—9.5M instruction-following samples across 13 Indian languages.
Framework for Multilingual, Multicultural Synthetic Data Generation
The framework delineates key factors for effective synthetic data generation:
- Base Model Capability: Selection of LLMs with demonstrated proficiency in target languages, considering licensing, cost, and openness.
- Seed Data Selection: Prioritization of tasks with cultural relevance and linguistic diversity, involving native speakers in the process.
- Data Generation Strategies: Comparison of translation-based, backtranslation, and retrieval-augmented generation. The latter leverages native language Wikipedia content to ensure cultural and linguistic grounding.
- Quality Metrics: Multi-dimensional evaluation including language correctness, linguistic acceptability, cultural appropriateness, and safety/bias.
- Downstream Evaluation: Use of diverse, non-translated benchmarks covering all target languages and domains, with attention to benchmark contamination.
- Native Speaker Involvement: Ensuring consent, privacy, and data sovereignty, with native speakers engaged in both seed selection and evaluation.
Updesh Dataset Construction
Updesh comprises two complementary subsets:
- Reasoning Data: Translation of high-quality reasoning datasets (OrcaAgent-Instruct, OrcaMath) into 13 Indic languages using Llama-3.1-405B-Instruct, with rigorous quality filtering.
- Open-Domain Generative Data: Generation of culturally contextualized data using Qwen3-235B-A22B, grounded in Wikipedia content. The process involves multi-phase LLM inference for tasks such as multi-hop QA, creative writing, and multi-turn dialogue, with explicit curation of cultural artifacts.
Automated filtering (IndicLID, repetition ratio) ensures high data integrity, with drop rates below 2% for most subsets. Notably, the dataset emphasizes long-context and multi-turn capabilities, addressing a gap in existing resources.
Data Quality Analysis
Quality assessment combines LLM-based evaluation (GPT-4o) and human annotation by native speakers, using stratified sampling and detailed rubrics across multiple dimensions (instruction adherence, fluency, narrative coherence, answer adequacy, persona consistency, etc.). Human evaluators assigned only 0.27% zero scores across 10,000 assessments, indicating high overall quality.
Inter-annotator agreement analysis reveals substantial variance across metrics:
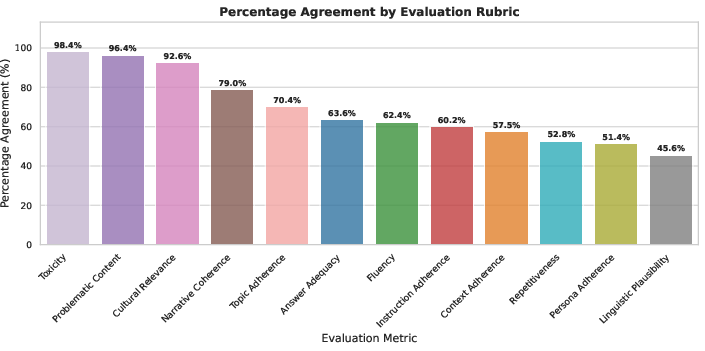
Figure 1: Human LLM-judge agreement across evaluation metrics, revealing differences across dimensions.
Agreement is robust for objective criteria (toxicity, problematic content), but deteriorates for culturally and linguistically nuanced assessments (linguistic plausibility, persona consistency in long dialogues). This highlights limitations of current LLM-judges in evaluating culturally sensitive content.
Distributional analysis of LLM and human scores across tasks and languages further elucidates these trends:
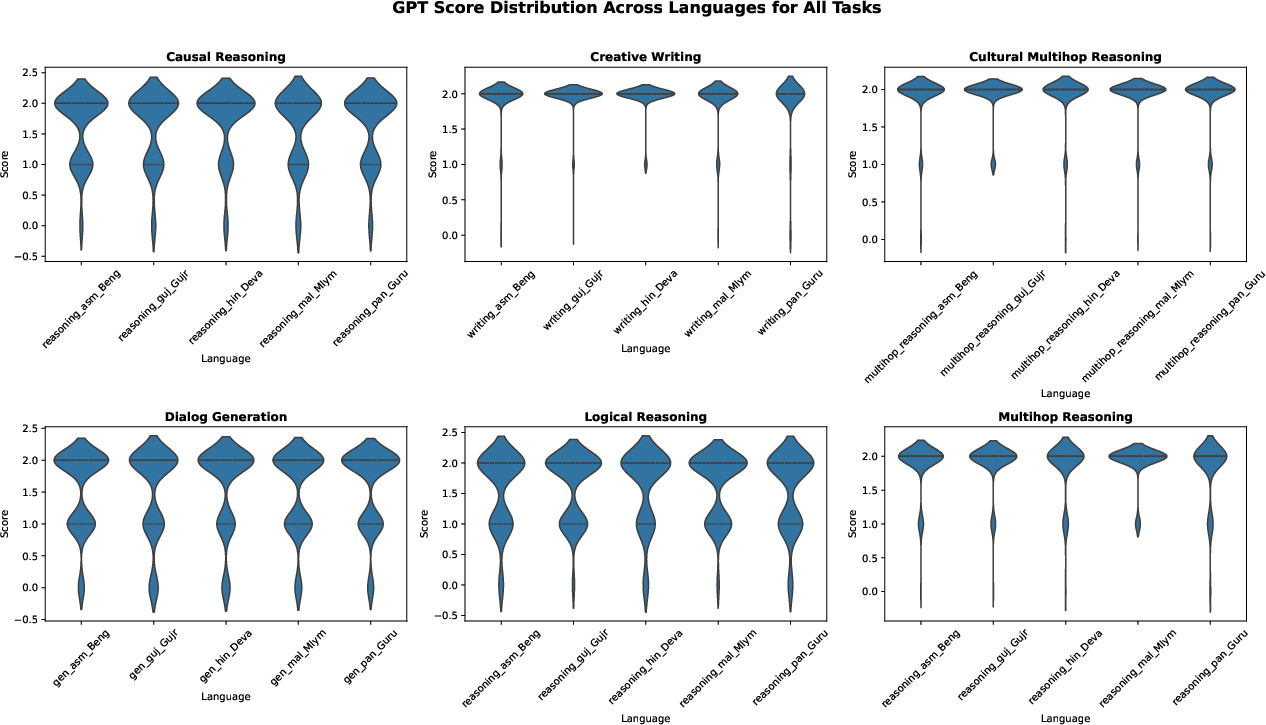
Figure 2: LLM evaluations across 5 synthetically generated tasks.
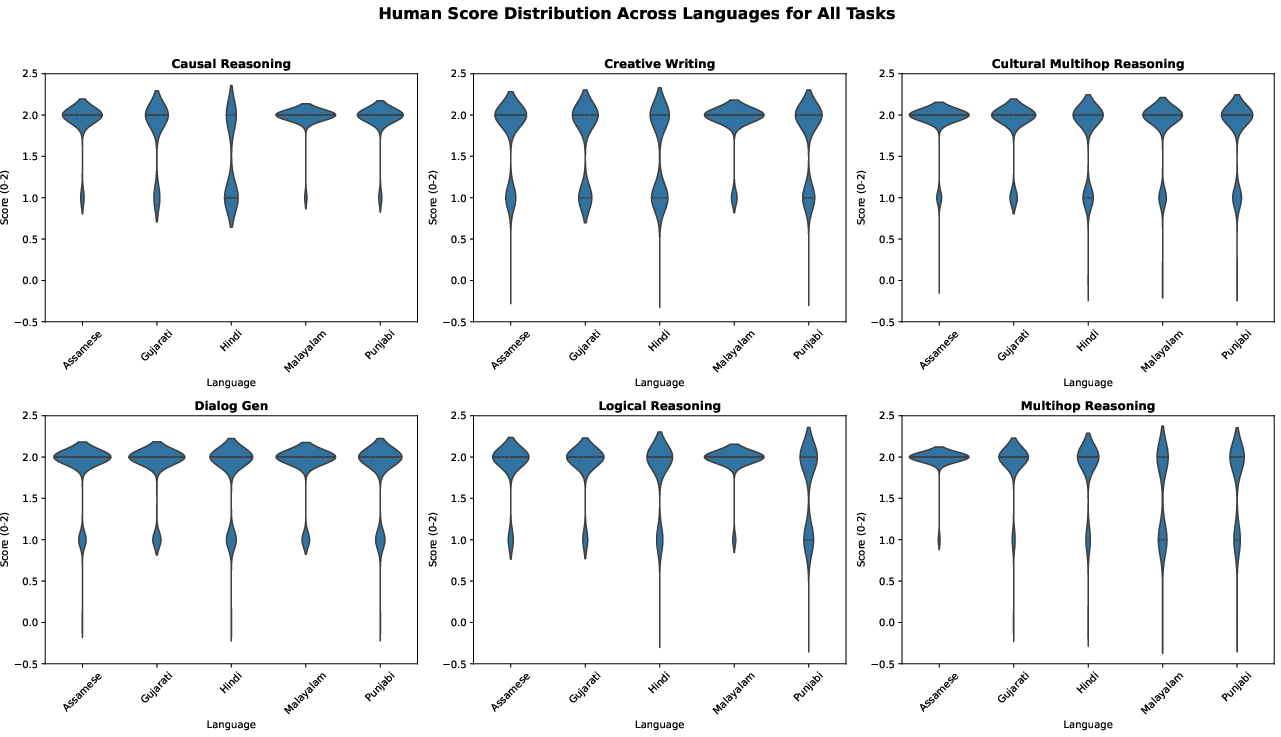
Figure 3: Expert human evaluations across 5 synthetically generated tasks.
Confusion matrices and agreement analysis per task/language provide granular insights into areas of disagreement:
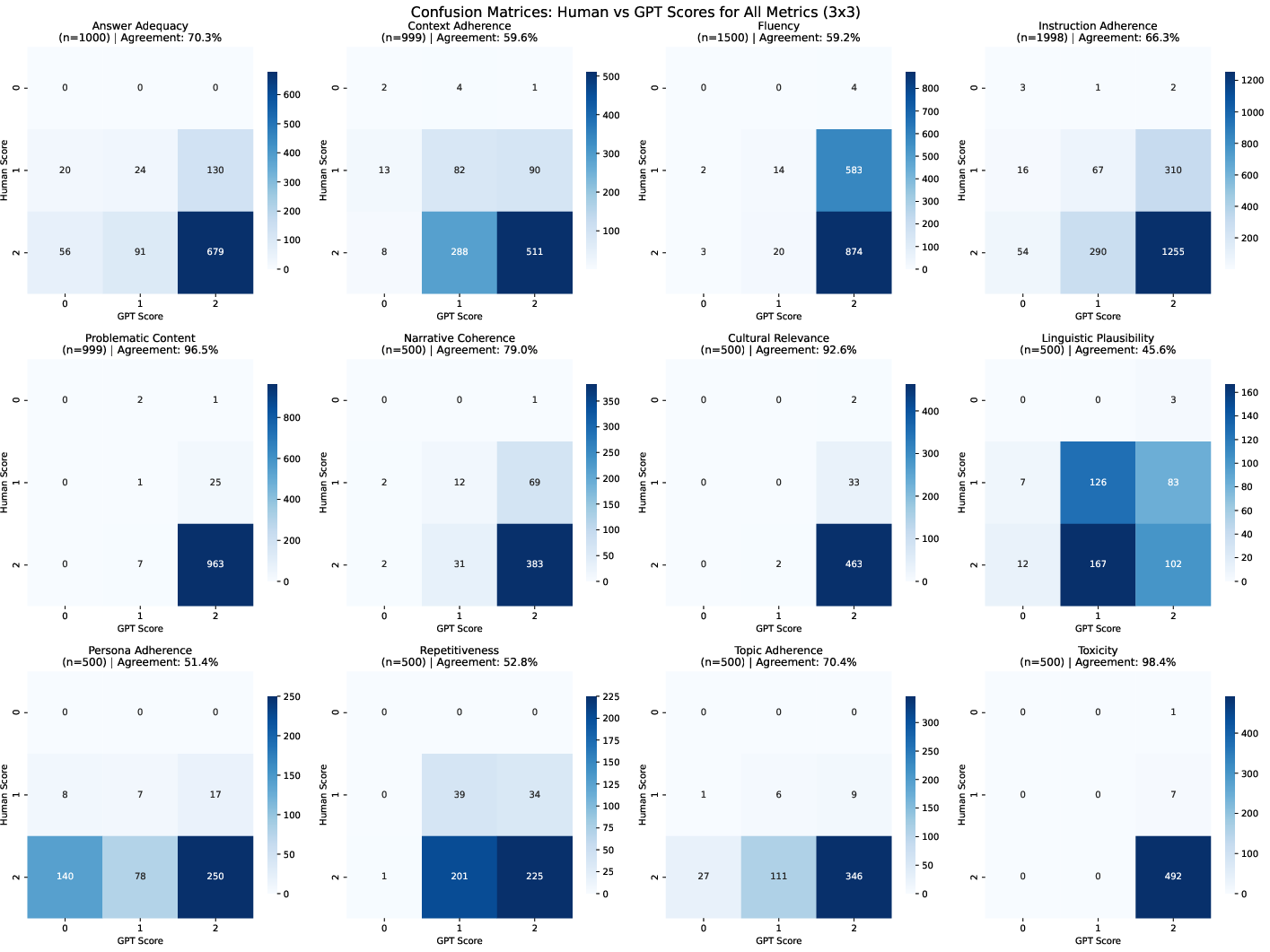
Figure 4: Confusion matrices showing agreement between human and LLM evaluators.
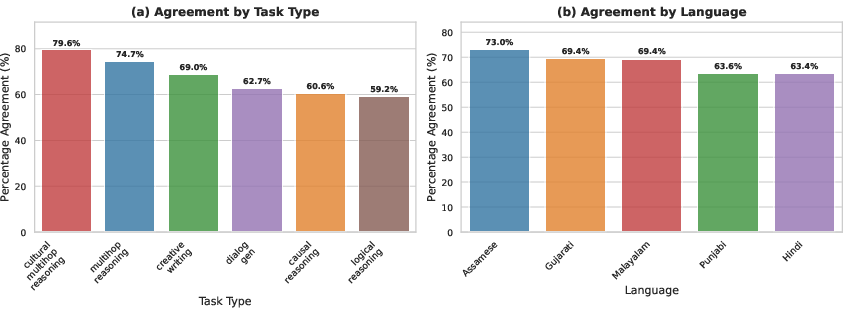
Figure 5: Agreement between human and LLM evaluators per task and language respectively.
Downstream Task Evaluation
Fine-tuning experiments were conducted on Llama-3.1-8B and Phi4-14B, comparing Updesh against Aya-Collection, IndicAlign, and Bactrian-X baselines. Evaluation spans NLU (multiple-choice), NLG (translation, summarization), and instruction-following (IFEval, IFBench) tasks, using both native and translated benchmarks.
Updesh yields significant improvements on NLG tasks, with Llama-Updesh and Phi4-Updesh achieving the highest ChrF scores across translation and summarization. NLU results are more nuanced: Phi4-Updesh attains best overall scores on several benchmarks (MMLU-I, MILU, BoolQ-I, BeleBele, INCL, GlobalMMLU), but no single configuration dominates across all NLU tasks.
Language-wise analysis demonstrates that Updesh delivers the largest relative gains in low- and mid-resource languages, effectively narrowing the gap to high-resource languages:
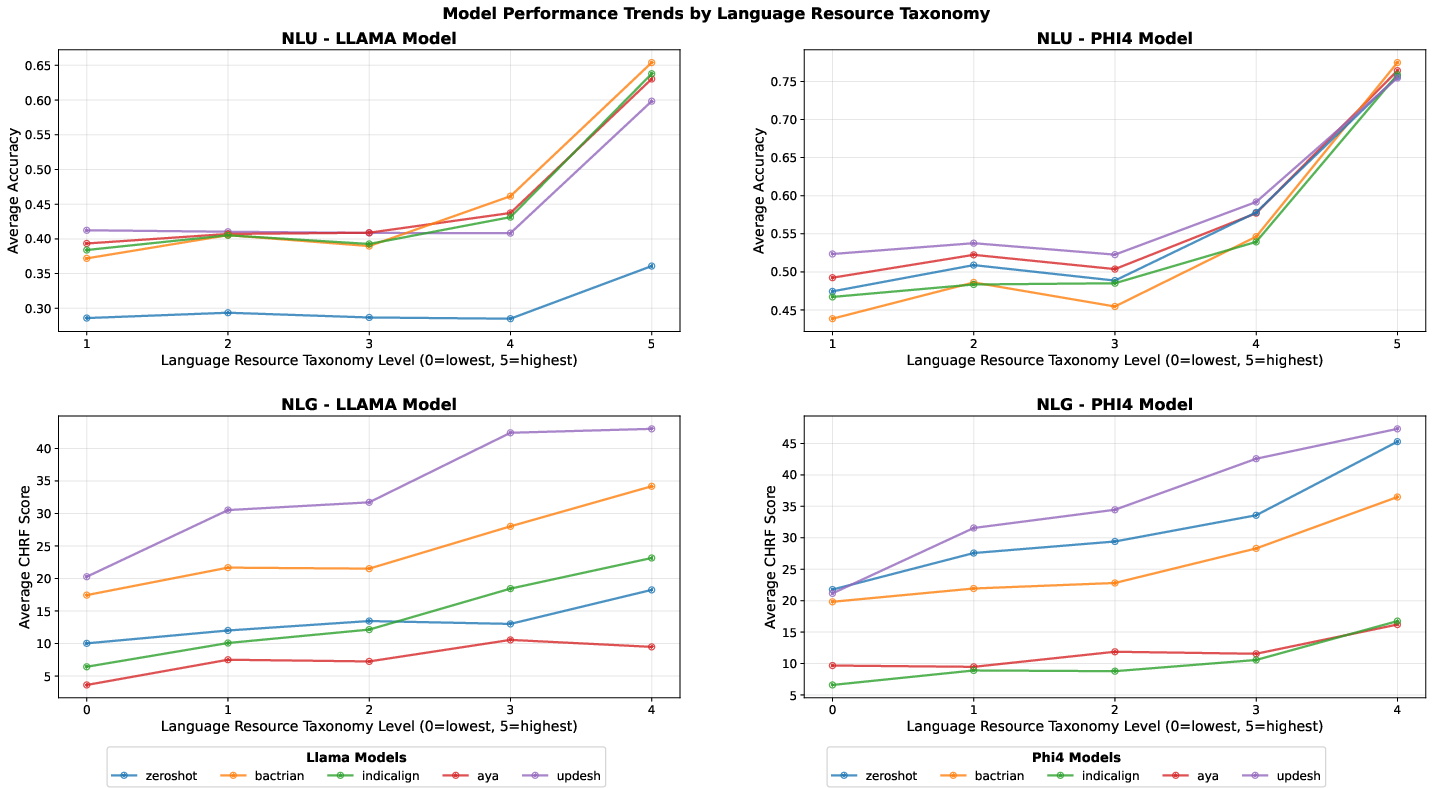
Figure 6: NLU and NLG task performance grouped by language–resource class taxonomy from Joshi et al. (2020). Updesh yields the largest relative gains in low/mid-resource languages.
Instruction-Following Capabilities
On instruction-following benchmarks, Updesh provides robust performance with minimal catastrophic forgetting, especially for Phi4. Fine-tuning generally degrades Llama's performance, but Updesh shows smaller drops compared to other baselines. The results underscore the importance of training data format and distributional alignment with downstream tasks.
Discussion
- Quality Evaluation: LLM-based evaluators are insufficient for nuanced multilingual and multicultural quality assessment, necessitating scalable human-in-the-loop protocols.
- Task-Type Sensitivity: Updesh-trained models excel in NLG tasks due to long-context, generative training data, while NLU gains are attenuated by format mismatches.
- Distributional Mismatch: The composition shift in Updesh (long-form, multi-step, generative) amplifies NLG gains but limits NLU improvements, highlighting the need for task-aligned data curation.
- Resource Gap Bridging: Updesh demonstrates that context-aware, culturally grounded synthetic data can effectively bridge resource gaps, especially in low-resource languages.
Ethical Considerations
The paper details institutional oversight, annotator demographics, and rigorous quality assurance protocols. Native speakers were involved in annotation, with explicit attention to privacy, consent, and data sovereignty.
Conclusion
This work provides a comprehensive empirical study of synthetic data generation for multilingual, multicultural AI, with a focus on Indic languages. The Updesh dataset, constructed via a bottom-up, culturally grounded pipeline, demonstrates that synthetic data can substantially improve generative task performance and reduce resource disparities. However, the results indicate that no single strategy is universally optimal; effective multilingual AI development requires multi-faceted, context-aware data curation and evaluation methodologies. The public release of Updesh and associated protocols will facilitate transparent, reproducible research in this domain.