- The paper presents the SHINE framework that unlocks FLUX’s innate priors for physically plausible image composition using a training-free approach.
- It introduces novel methods like Manifold-Steered Anchor loss, Degradation-Suppression Guidance, and Adaptive Background Blending to improve subject fidelity and background integration.
- Experimental results on the ComplexCompo benchmark demonstrate superior performance in realistic conditions, highlighting the framework’s potential for diverse diffusion models.
Physically Plausible Image Composition with FLUX: The SHINE Framework
Introduction and Motivation
Image composition—seamlessly inserting a user-specified object into a new scene—remains a challenging task for generative models, particularly under complex lighting, high-resolution backgrounds, and diverse scene conditions. While large-scale text-to-image diffusion models such as FLUX, SDXL, and Stable Diffusion 3.5 encode strong physical and resolution priors, existing approaches for image composition often fail to exploit these capabilities, especially in the presence of intricate shadows, water reflections, or non-standard resolutions. The primary bottlenecks are the reliance on latent inversion (which locks object pose and orientation) and fragile attention surgery (which is hyperparameter-sensitive and unstable).
The paper introduces SHINE, a training-free, model-agnostic framework that leverages the compositional priors of modern diffusion models for physically plausible image composition. SHINE is built on three core innovations: Manifold-Steered Anchor (MSA) loss, Degradation-Suppression Guidance (DSG), and Adaptive Background Blending (ABB). The framework is evaluated on a new benchmark, ComplexCompo, which features high-resolution, diverse, and physically challenging scenarios.

Figure 1: SHINE enables seamless integration of subjects into complex scenes, including low-light, intricate shadows, and water reflections.
Limitations of Existing Approaches
Prior training-based methods fine-tune diffusion models on synthetic triplets (object, scene, composite), but these datasets are typically low-quality, leading to poor handling of lighting and resolution. Training-free methods, while more flexible, depend on image inversion and attention manipulation, which introduce pose rigidity and instability, respectively. Notably, the base models themselves (e.g., FLUX) do not exhibit these artifacts, indicating that the underlying physical priors are present but not effectively utilized.

Figure 2: Advanced multimodal models struggle with backlighting, shadows, and water surfaces, failing to achieve physically plausible compositions.
SHINE Framework: Methodology
Non-Inversion Latent Preparation
SHINE abandons inversion-based initialization. Instead, it uses a vision-LLM (VLM) to caption the subject, inpaints the background using this caption, and then perturbs the inpainted image with Gaussian noise to obtain the initial noisy latent. This approach decouples the inserted object's pose from the reference image, allowing for contextually appropriate placement.
Manifold-Steered Anchor (MSA) Loss
MSA loss leverages pretrained customization adapters (e.g., IP-Adapter, InstantCharacter) to guide the noisy latent toward a faithful representation of the reference subject, while preserving the structural integrity of the background. The loss aligns the velocity prediction of the adapter-augmented model with that of the base model on the original latent, effectively projecting the composition onto the learned data manifold of the generative model.
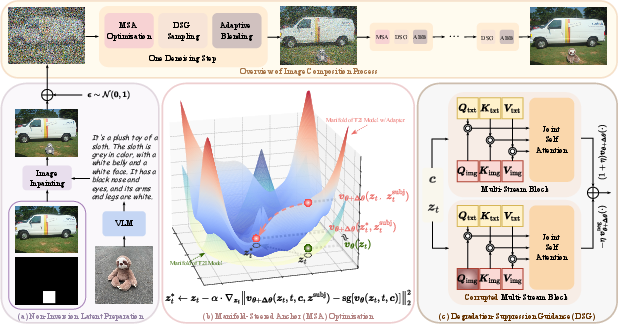
Figure 3: SHINE framework overview. (a) Noisy latent creation via inpainting and noise. (b) MSA loss steers latents for subject fidelity and background preservation. (c) DSG steers away from low-quality regions.
Degradation-Suppression Guidance (DSG)
DSG addresses the stochasticity of denoising, which can lead to oversaturated colors and identity drift. Inspired by negative prompting, DSG constructs a negative velocity by blurring the image query matrix (Qimg) in the self-attention mechanism of FLUX. This operation degrades perceptual quality while preserving structure, and is mathematically equivalent to blurring the self-attention weights. DSG then steers the denoising trajectory away from these low-quality regions.

Figure 4: Left: FLUX's robustness to negative prompts. Right: Only blurring Qimg yields controlled degradation without destroying structure.
Adaptive Background Blending (ABB)
Traditional blending with a user-provided mask introduces visible seams at the boundary. ABB replaces the rigid mask with a semantically precise mask derived from cross-attention maps, dilated and filtered for the largest connected component. This approach yields smoother transitions and better preserves the background, especially for irregularly shaped objects.

Figure 5: ABB eliminates visible seams compared to rectangular-mask blending, especially at object boundaries.
Experimental Evaluation
Benchmarks and Metrics
The authors introduce ComplexCompo, a benchmark with 300 composition pairs featuring diverse resolutions and challenging conditions (low lighting, strong illumination, shadows, reflections). Evaluation metrics include CLIP-I, DINOv2, IRF, DreamSim (for subject identity), ImageReward and VisionReward (for image quality), and LPIPS/SSIM (for background consistency). Notably, DreamSim is shown to better align with human perception than CLIP-I or DINOv2.
Quantitative and Qualitative Results
SHINE achieves state-of-the-art performance on both DreamEditBench and ComplexCompo, outperforming both training-based and training-free baselines on human-aligned metrics. The LoRA-based variant yields the highest subject identity consistency, while the adapter-based variant offers strong performance without test-time tuning. The method is robust to high-resolution and non-square backgrounds, and excels in physically challenging scenarios.

Figure 6: SHINE outperforms baselines in challenging scenarios, producing natural compositions under complex lighting and reflections.
Ablation Studies
Ablation experiments confirm that MSA loss is critical for subject identity, DSG improves image quality by avoiding low-quality regions, and ABB is essential for seamless boundary integration. Visual ablations further illustrate the impact of each component.

Figure 7: Ablation study: each component (MSA, DSG, ABB) contributes to improved realism and fidelity.
Analysis of Failure Modes and Metric Reliability
SHINE can inherit erroneous colors if the inpainting prompt is incorrect, highlighting the importance of accurate VLM captioning. The similarity between the inserted object and the reference is also bounded by the quality of the customization adapter. The paper demonstrates that commonly used identity metrics (CLIP-I, DINOv2) can be misleading, as they may reward copy-paste artifacts over physically plausible integration; DreamSim provides a more reliable assessment.

Figure 8: Failure case: incorrect inpainting prompt color propagates to the final composition.
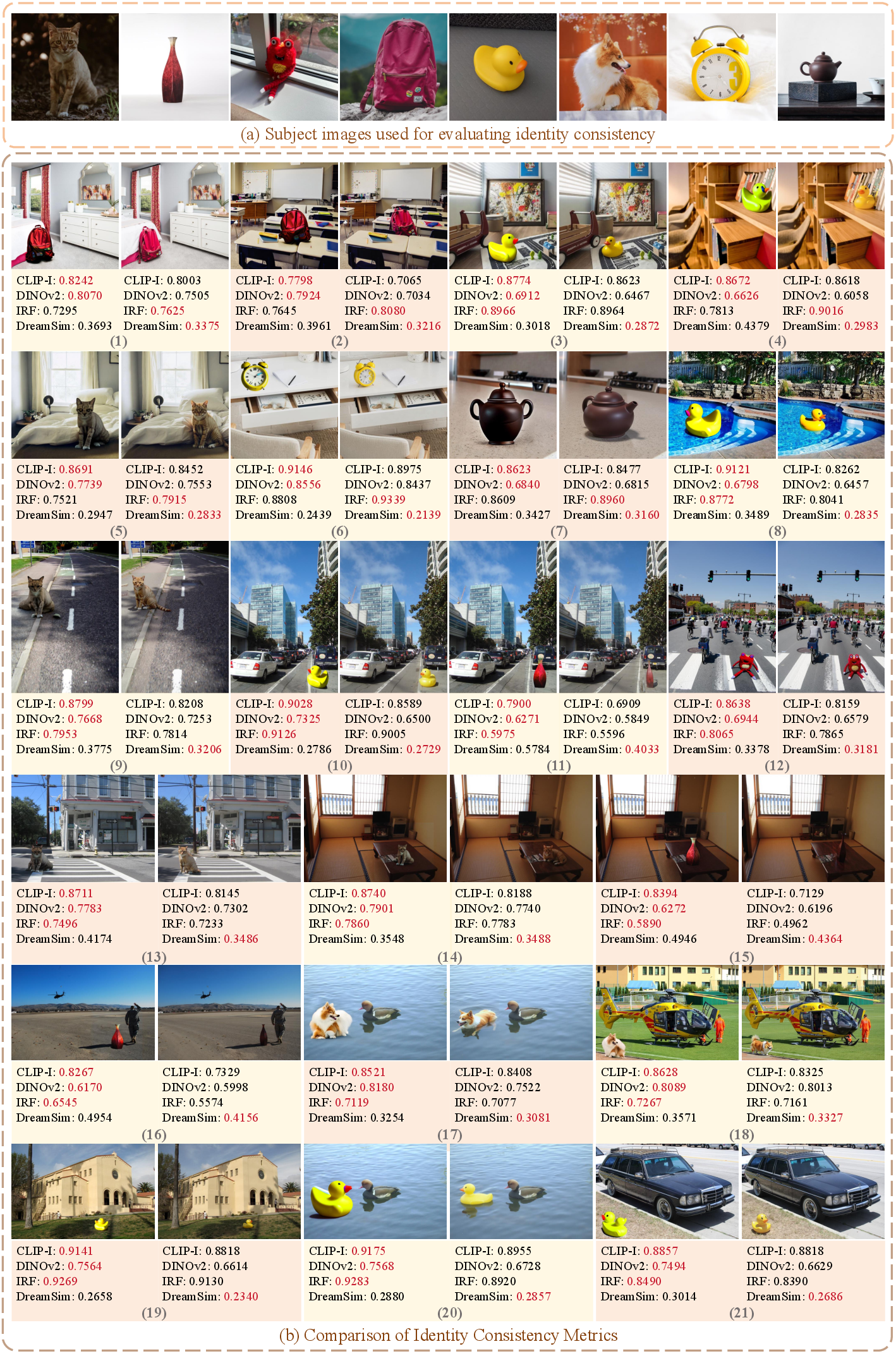
Figure 9: AnyDoor achieves higher CLIP-I/DINOv2/IRF scores despite less realistic results; DreamSim better reflects human judgment.
Implications and Future Directions
SHINE demonstrates that pretrained diffusion models such as FLUX already encode the necessary priors for physically plausible image composition, but require principled, training-free mechanisms to unlock these capabilities. The framework is model-agnostic and can be applied to other diffusion architectures (e.g., SDXL, PixArt). The introduction of ComplexCompo sets a new standard for evaluating compositional realism under real-world conditions.
Practically, SHINE enables high-fidelity, artifact-free object insertion in diverse scenarios without retraining or architectural modification. The approach is compatible with both open-domain adapters and per-concept LoRA, allowing for flexible trade-offs between generality and identity fidelity.
Theoretically, the work highlights the importance of manifold alignment and attention manipulation in controlling generative trajectories. The equivalence between query blurring and attention weight smoothing provides a new tool for controlled degradation in diffusion models.
Future research may focus on improving open-domain customization adapters, developing more reliable perceptual metrics, and extending the framework to video or 3D composition tasks. The findings also suggest that further advances in VLMs and inpainting models will directly benefit the quality and controllability of image composition.
Conclusion
The SHINE framework establishes that FLUX and similar diffusion models possess the latent capacity for physically plausible image composition, provided that their priors are properly harnessed. By integrating MSA loss, DSG, and ABB, SHINE achieves state-of-the-art results on challenging benchmarks, setting a new baseline for training-free, high-fidelity image composition. The work underscores the need for rigorous evaluation metrics and benchmarks, and opens avenues for further research in controllable, physically grounded generative modeling.