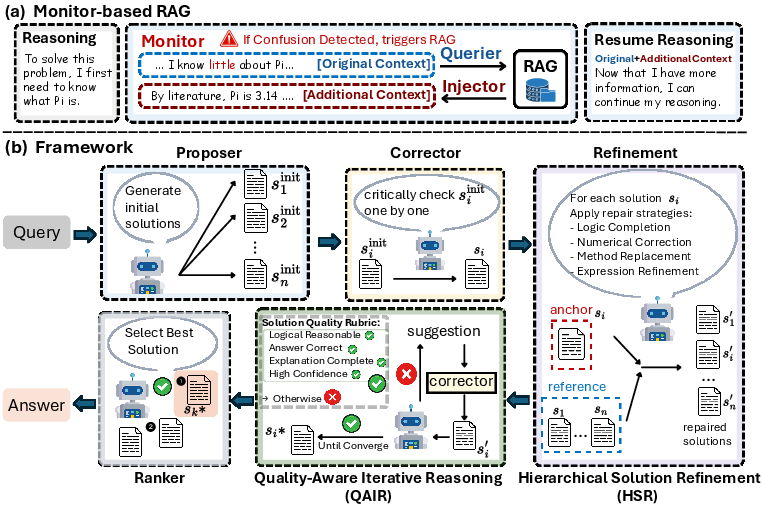
- The paper introduces a monitor-based RAG framework that dynamically refines candidate solutions during scientific reasoning.
- The framework achieved 48.3% accuracy on HLE Bio/Chem Gold, outperforming baselines by up to +18.1 points and reducing retrieval overhead by over 50%.
- It integrates Hierarchical Solution Refinement and Quality-Aware Iterative Reasoning to iteratively enhance logic, accuracy, and computational efficiency.
Adaptive Multi-Agent Refinement for Scientific Reasoning
Introduction
The paper "Eigen-1: Adaptive Multi-Agent Refinement with Monitor-Based RAG for Scientific Reasoning" presents a structured multi-agent framework that leverages Monitor-based Retrieval-Augmented Generation (RAG) to address challenges faced by LLMs in scientific reasoning. The primary issues identified by the authors are the fragmentation of reasoning through explicit retrieval and the inefficiencies introduced by uniform candidate aggregation in multi-agent setups.
Monitor-Based RAG
The proposed framework, Eigen-1, incorporates Monitor-based RAG, which functions seamlessly at the token level to detect reasoning insufficiencies. This setup implicitly augments the reasoning process by generating contextual queries and injecting retrieved evidence with minimal disruption.
- Implicit Retrieval: Unlike traditional RAG paradigms that pause the reasoning process for external retrieval, the Monitor-based RAG operates continuously, preserving the flow.
- Experimental Evidence: It achieves a 48.3% accuracy on the Humanity's Last Exam (HLE) Bio/Chem Gold, outperforming the best LLM by considerable margins and reducing retrieval overhead by over 50%.
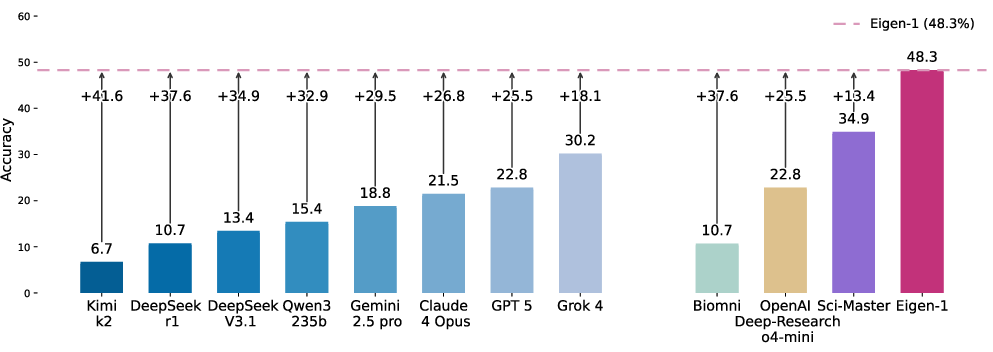
Figure 1: HLE Bio/Chem Gold overall accuracy. On the 149-problem split, our system attains 48.3% accuracy, exceeding the strongest agent baseline by +13.4 points and leading frontier LLMs by up to +18.1 points.
Hierarchical Solution Refinement
The Hierarchical Solution Refinement (HSR) framework rotates each candidate solution as an anchor to be refined by its peers, facilitating structured, cross-solution improvement.
- Anchor-Reference Paradigm: Each candidate solution is treated as an anchor while peers provide reference-based improvements, preventing premature consensus and enhancing the final solution.
- Mechanism: Targeted improvements include logic completion and numerical correction, among others. HSR moves beyond simple averaging, allowing solutions to converge based on quality.
Quality-Aware Iterative Reasoning
Quality-Aware Iterative Reasoning (QAIR) evaluates intermediate solution quality and iteratively refines candidates using quality-driven metrics.
Experimental Results
- Data and Metrics: Experiments were conducted on diverse benchmarks including SuperGPQA and TRQA, confirming robustness across domains.
- Key Findings: The framework reduced the "tool tax" from retrieval by a substantial margin and significantly improved reasoning efficiency and accuracy.
- Error Analysis: It highlighted two major overlapping failure modes—reasoning process errors and knowledge gaps—each addressed by the framework's components.
Implications and Future Work
The integration of implicit augmentation and structured refinement paves the way for optimized reasoning frameworks capable of more natural knowledge integration, critical for domains requiring complex problem-solving.
- Future Directions: While focused on scientific reasoning, these principles could generalize to other high-stakes areas involving multistep logical inference and dynamic knowledge needs.
Conclusion
Eigen-1's innovations in the integration of external knowledge reveal pathways to enhance reasoning performance and efficiency through structured agent frameworks and adaptive refinement processes. Further exploration will aim to extend this model's applicability to broader domains in AI-driven scientific inquiry.