UserRL: Training Interactive User-Centric Agent via Reinforcement Learning
Abstract: Reinforcement learning (RL) has shown promise in training agentic models that move beyond static benchmarks to engage in dynamic, multi-turn interactions. Yet, the ultimate value of such agents lies in their ability to assist users, a setting where diversity and dynamics of user interaction pose challenges. In this work, we propose UserRL, a unified framework for training and evaluating user-centric abilities through standardized gym environments paired with simulated users. We systematically vary turn-level reward assignment and trajectory-level score calculation to analyze how different formulations affect learning under the GRPO algorithm. Our experiments across Qwen3 models reveal three key findings: (i) SFT cold start is critical for unlocking initial interaction ability and enabling sustained RL improvements; (ii) deliberate trajectory scoring yields more efficient and effective multi-turn interactions; and (iii) while stronger simulated users (e.g., GPT-4o) facilitates training, open-source simulators (e.g., Qwen3-32B) remain a cost-effective and transferable option. Together, these results highlight that careful design of reward shaping and user simulation choice is as crucial as model scale, and establish UserRL as a practical pathway for developing robust user-centric agentic models. All codes and data are public for future research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces UserRL, a way to train AI assistants to be truly helpful to people by practicing realistic, multi-turn conversations. Instead of just testing AIs on fixed quizzes, UserRL creates “gym” environments where the AI can talk with simulated users, ask questions, use tools, and solve tasks step by step—more like a real chat with a person.
What the researchers wanted to find out
The authors focused on simple, practical questions:
- How do we teach an AI to handle diverse, changing user needs during a conversation?
- What’s the best way to give the AI “points” (rewards) during multi-step interactions?
- Should we score each turn equally, or reward turns that lead to success later?
- Does giving the AI a warm-up with examples (called SFT cold start) make RL training work better?
- Do stronger simulated users (like GPT-4o) help training more than cheaper ones (like Qwen3-32B)?
- Can models trained in these gyms talk more efficiently and effectively?
- Do these training choices matter more than just making the AI bigger?
How they did it (in everyday terms)
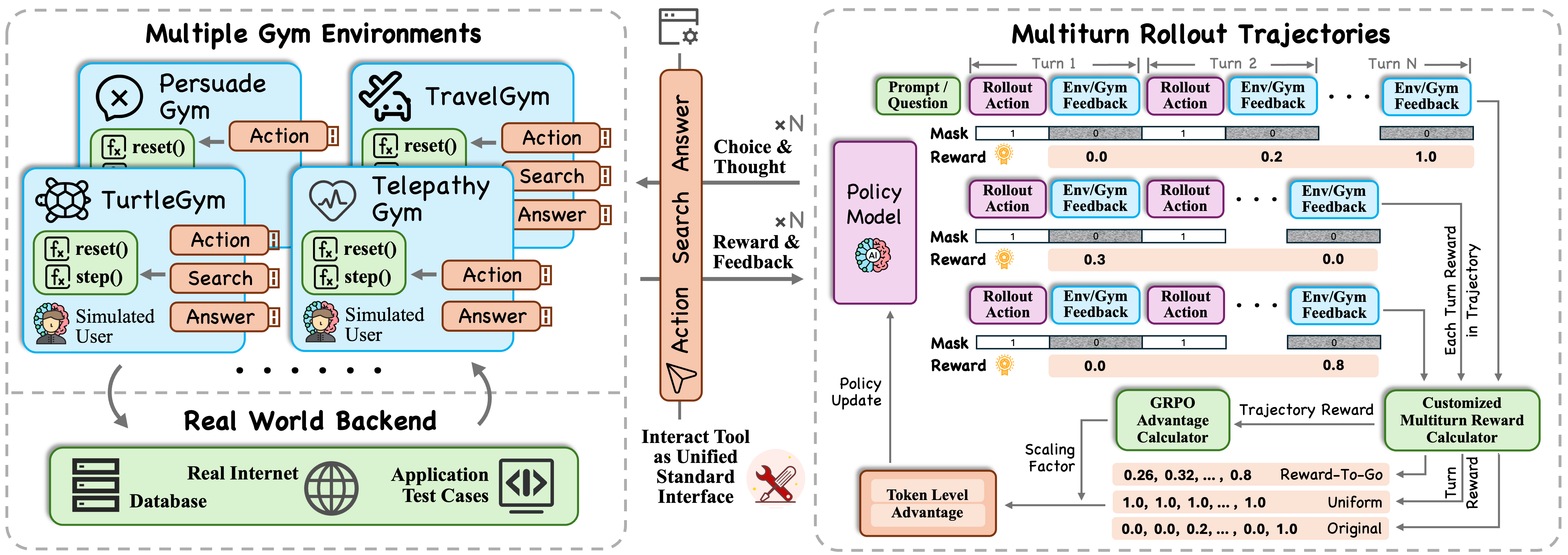
Think of training the AI like coaching a player through levels of a game. Each “level” is a gym environment with a particular skill:
- The paper builds 8 gyms that test different abilities, such as:
- Understanding vague intent (IntentGym)
- Reasoning through puzzles (TurtleGym)
- Persuasion (PersuadeGym)
- Guessing a hidden object with clues (TelepathyGym)
- Finding a hidden rule in numbers (FunctionGym)
- Planning travel using user preferences (TravelGym)
- Using tools to complete tasks (TauGym)
- Searching the web and answering questions (SearchGym)
All gyms use a simple tool interface with three actions:
- Action: talk to the user (like asking a clarifying question)
- Search: look things up (like using a search engine)
- Answer: give a final solution or guess
During training:
- The AI has multi-turn conversations. Each turn is like a move in the game.
- The gym gives rewards: small points for useful steps, bigger points if the final answer is correct.
- The full conversation is a “trajectory” (the series of states, actions, and rewards).
Because conversations have many steps, the team tested different ways to assign rewards:
- Equalized: give each turn a similar credit (simple and stable).
- Reward-to-Go (R2G): give a turn credit based on the future rewards it helps unlock (like rewarding early setup moves that lead to later wins).
- Exponential Mapping: gently boost small positive steps so they still count.
They also tried different ways to score the entire conversation:
- Sum: just add all the turn rewards.
- R2G at the trajectory level: favor strategies that make progress earlier.
The core training method is a modern reinforcement learning approach (GRPO), which compares groups of attempts to the same query and pushes the AI toward the better ones. Before RL, they give the model a warm-up with examples (SFT cold start), so it starts with basic conversation skills.
They trained open-source Qwen3 models (sizes like 4B and 8B) using simulated users. They mainly used a cost-effective simulator (Qwen3-32B) and sometimes a stronger one (GPT-4o) to see the difference.
What they found and why it matters
Here are the key results and why they’re important:
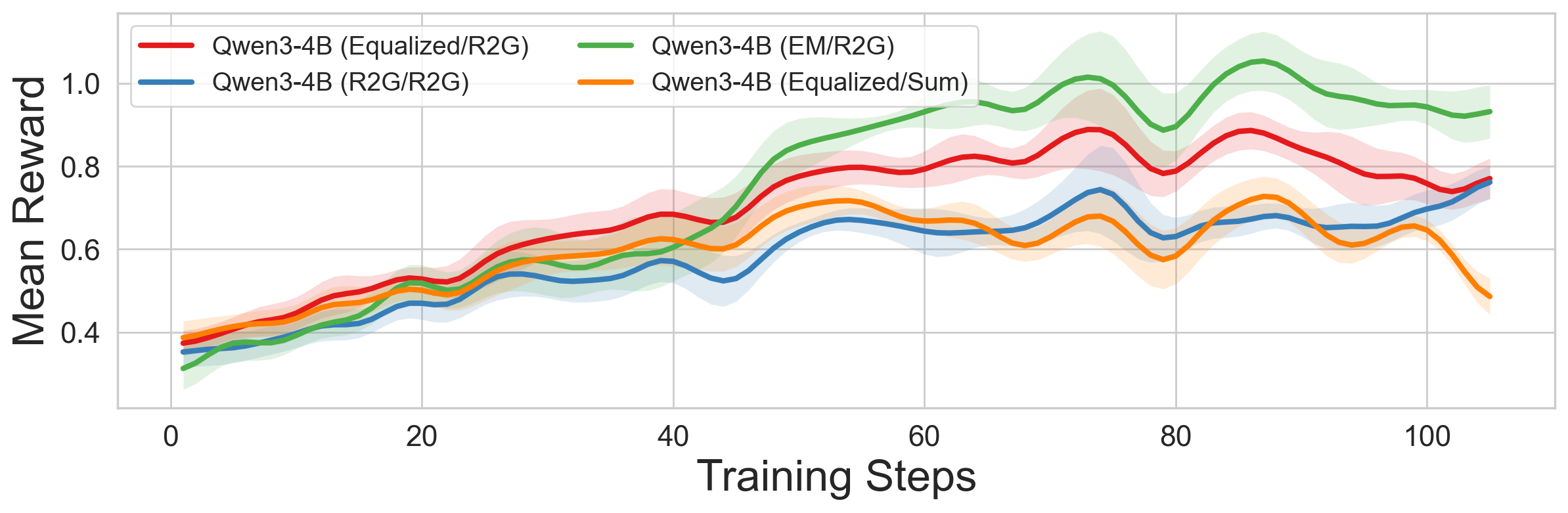
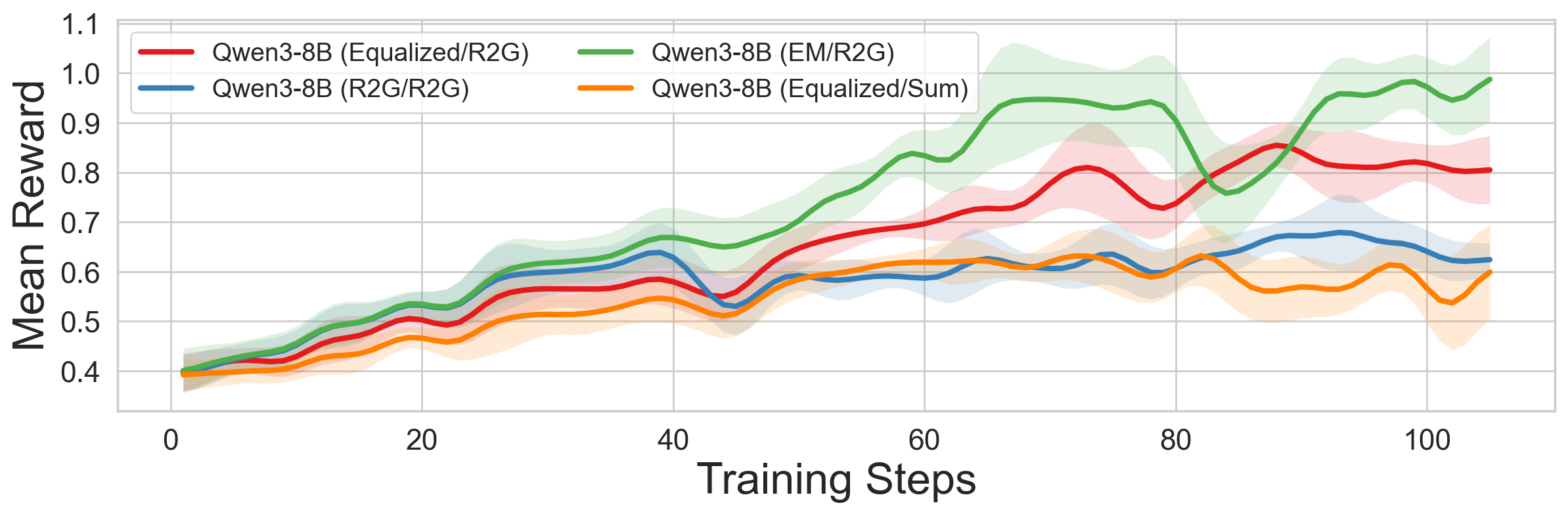
- Equalized/R2G works best across models
- Using equal turn rewards plus Reward-to-Go for the whole conversation consistently gave the best performance.
- Why it matters: Scoring the conversation smartly (not just summing rewards) helps the AI learn to use early turns to set up success later.
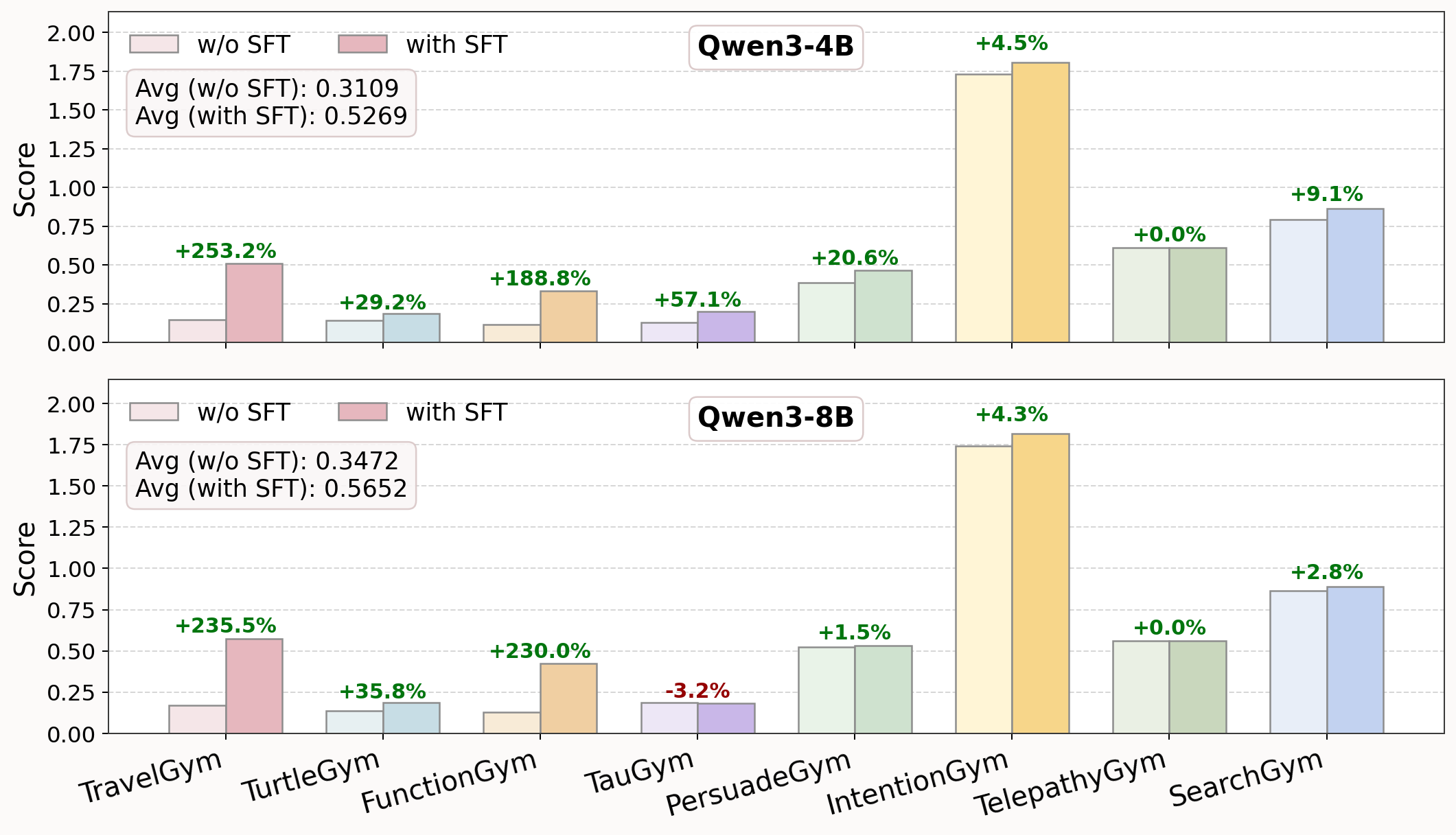
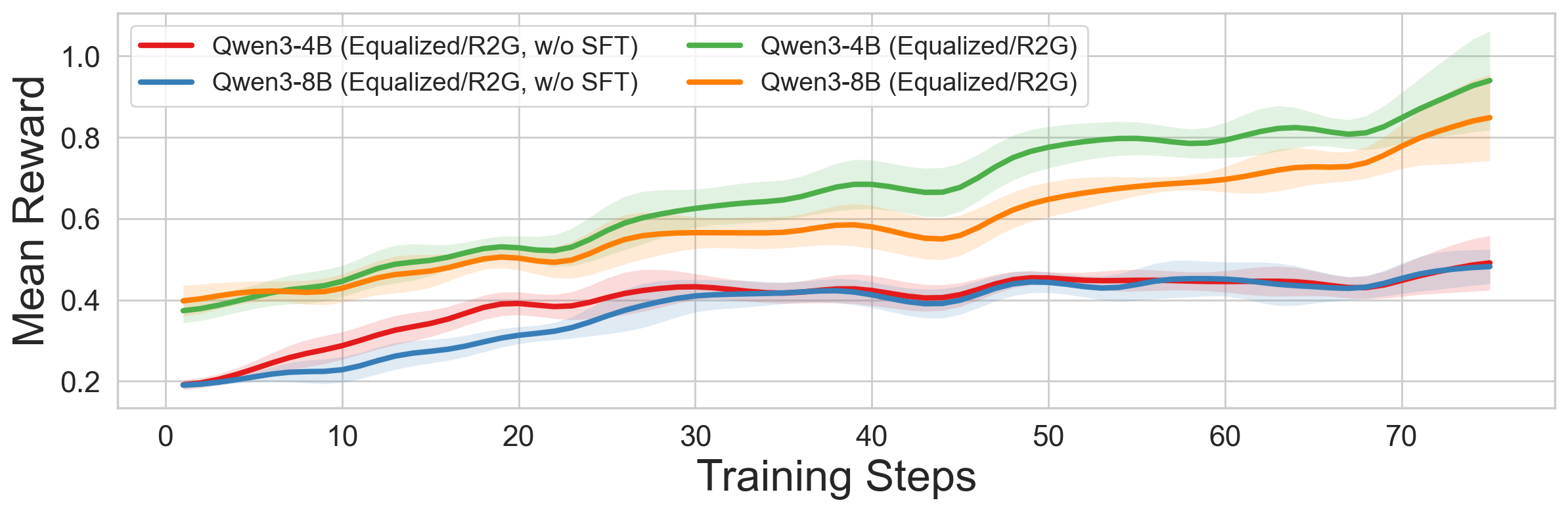
- SFT cold start is crucial
- Warming up the model with supervised examples before RL prevented training from stalling and often doubled performance.
- Why it matters: Examples first, practice second—just like learning any skill—leads to stable and strong improvements.
- Trajectory-level scoring matters more than fancy per-turn tricks
- How you score the entire conversation influences learning more than delicate per-turn reward tweaks.
- Why it matters: Focus on how to judge the whole interaction, not micromanaging every step.
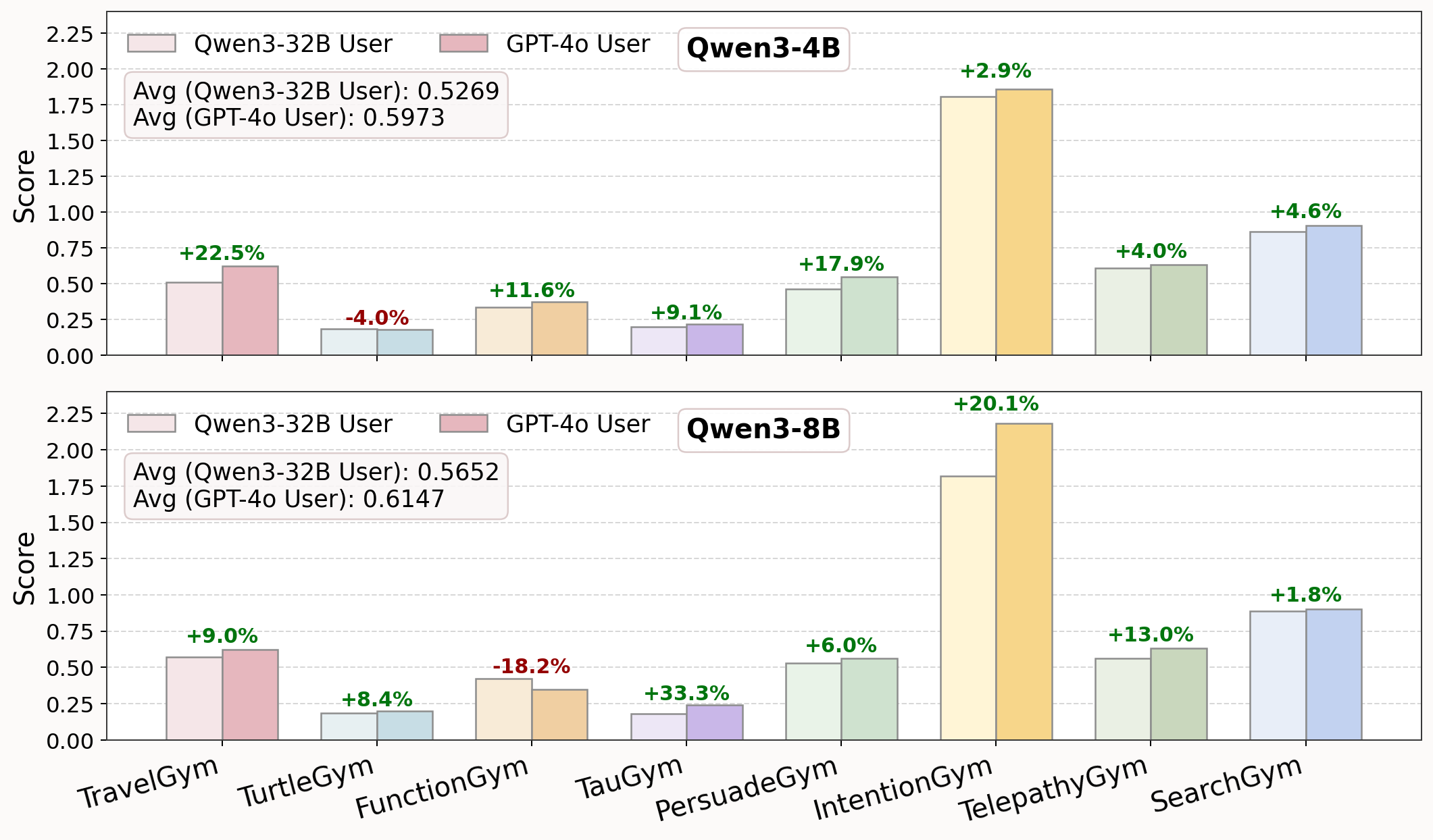
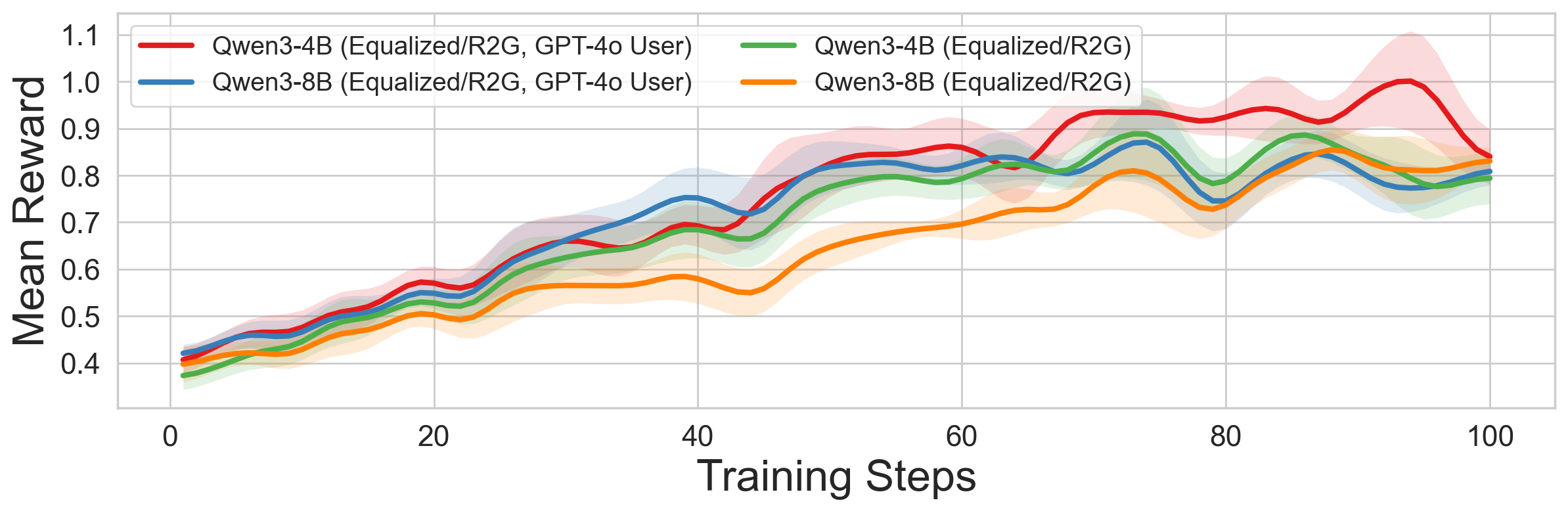
- Stronger simulated users help, but cheaper ones still work
- Training with GPT-4o improved results slightly and faster, but training with Qwen3-32B was still effective and far cheaper.
- Why it matters: Teams can use affordable simulators and still get good results, which makes this approach practical.
- Trained open-source models can beat closed-source models on some interactive tasks
- After gym-based RL, Qwen3-8B outperformed big-name models (like Gemini-2.5-Pro and GPT-4o) in several user-facing gyms.
- Why it matters: Careful training can matter more than brand or size, especially for multi-turn, user-centric skills.
- Bigger raw models don’t help much without interaction training
- Simply scaling model size didn’t improve performance on these gyms unless the model was trained for interactive skills.
- Why it matters: It’s not just about size; it’s about teaching the right skills.
- R2G improved interaction efficiency
- Models trained with R2G tended to make useful progress earlier in fewer turns (not just longer chats).
- Why it matters: Real users prefer quick, helpful interactions. Rewarding early progress leads to better user experiences.
- Real humans helped models perform even better
- When real people replaced simulated users in testing, the models did better. Humans naturally give richer hints and cooperate.
- Why it matters: Designing assistants to collaborate can unlock better outcomes than strict “yes/no” style interactions.
What this means for the future
UserRL shows a practical way to train AIs that truly help people: build realistic, multi-turn practice environments, score the whole conversation wisely, and start training with examples. The authors also point out areas to improve:
- Better turn-level rewards: Simple heuristics sometimes miss the real value of a turn (e.g., a brilliant early question). Future work should design smarter, possibly learned reward signals.
- Better user simulations: Simulators should reflect diverse personalities, strategies, and styles while keeping evaluation fair and consistent.
- Balance effectiveness and efficiency: Great assistants both understand the user well and don’t waste time. Training should reward accuracy and conciseness.
Bottom line: If you want AI assistants that ask good questions, adapt to changing goals, use tools properly, and give helpful answers fast, you need the right training setup—not just a bigger model. UserRL provides that setup, and the team has released their code and data to help others build on it.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Upon reviewing the paper "UserRL: Training Interactive User-Centric Agent via Reinforcement Learning," several gaps, limitations, and unresolved questions emerge, which future researchers could address:
- User Simulation Realism: The paper uses LLMs like Qwen3-32B and GPT-4o as simulated users. While these models provide dynamic feedback, the realism of these simulations compared to actual user interactions is not thoroughly validated. How accurate are these simulated interactions compared to real-world user behavior?
- Turn-level Reward Accuracy: Turn-level reward shaping techniques like Exponential Mapping (EM) and Reward-to-Go (R2G) attempt to estimate the value of intermediate actions. However, they might inadequately capture the nuanced contributions of each turn to the final outcome. How can turn-level rewards be designed to better reflect the strategic importance of individual actions across different environments?
- Trajectory-level Score Calculation: The paper illustrates that trajectory-level scoring (Sum vs. Reward-to-Go) impacts performance significantly. While current methods like R2G promote early rewards, they might not fully capture the complexity of all tasks. Is there a more comprehensive strategy to aggregate user-centric feedback that balances efficiency and effectiveness?
- Diversity in User Profiles: The current simulation profiles may not encompass the full spectrum of real-world user behaviors. How can we integrate more diverse and realistic user profiles into simulated environments to ensure model robustness across varied real-world scenarios?
- Scalability and Cost of Training: Using larger models like GPT-4o during training proved beneficial but is also cost-intensive. What are the trade-offs in cost versus performance when employing high-fidelity simulated users versus more economical, open-source alternatives?
- Balance between Interaction Rigor and Flexibility: The paper discusses the balance between rule-based task completion tracking and dynamic LLM responses. This approach might limit naturalness. How can we design a simulation framework that better balances the need for rigorous evaluation with flexible interaction patterns?
- Evaluation Metrics: Effective Turns and Time-Weighted Performance are introduced as metrics, yet they may inherently conflict. How can these metrics be refined to better capture the dual goals of effectiveness and efficiency in user interactions?
- Algorithm Stability and Out-of-the-box Performance: While SFT cold start improves stability, raw models tend to plateau or collapse early in training. Are there alternative strategies or setups that could enhance the inherent stability and performance of RL algorithms without initial SFT?
This list serves as a roadmap for future investigation and enhancement within the domain of interactive, user-centric agent development using reinforcement learning.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can apply the paper’s findings and artifacts today, along with sector tags and key dependencies to consider.
- Boldly clarify user intent in assistants
- Sector: software, customer support, government services
- What to build: Deploy “clarify-first” multi-turn workflows (from IntentGym) in chat assistants that ask focused, minimal questions to resolve ambiguity before acting.
- How: Adopt the Action/Search/Answer interface; fine-tune existing 4B–8B models with SFT cold start + Equalized turn-level rewards + trajectory Reward-to-Go (R2G).
- Dependencies: High-quality SFT traces; tool-API access; basic guardrails for safe questioning.
- Assumptions: User cooperation and tolerance for 1–3 clarifying turns; domain prompts reflect live tasks.
- Travel planning copilots with better preference elicitation
- Sector: travel, consumer apps
- What to build: Personal travel booking agents (from TravelGym) that interactively elicit must-have vs. nice-to-have preferences and propose options.
- How: Train on TravelGym; plug into OTA/booking APIs; track Time-Weighted Performance as a live KPI to reduce “back-and-forth.”
- Dependencies: Reliable inventory/search APIs; preference schema; logging for reward calculation.
- Assumptions: Simulated-user-trained behaviors transfer to real users; latency acceptable for multi-turn flows.
- Tool-using task agents that complete forms and procedures
- Sector: enterprise productivity, IT operations, HR/finance ops
- What to build: Agents that query users for missing details, call tools, and complete tasks (from TauGym).
- How: Adopt standardized interface to enforce structured tool calls; use Equalized/R2G scoring to reward early, enabling turns.
- Dependencies: Tool invocation safety; deterministic validators to compute rewards; access control and auditing.
- Assumptions: Tasks can be decomposed to multi-turn dialogues + verifiable operations.
- Ethical persuasion for retention and resolution
- Sector: customer success, billing, subscriptions
- What to build: Agents that present pros/cons and propose compromise plans to reduce churn (from PersuadeGym), with explicit policy constraints.
- How: Train on arguments structured around user-provided goals; embed safety filters and compliance prompts.
- Dependencies: Policy and legal review; aligned reward signals (e.g., user attitude change as a proxy).
- Assumptions: Persuasion intent is disclosed and bounded; measurable, ethical outcomes.
- Creative reasoning and “twist discovery” in knowledge curation
- Sector: media, entertainment, knowledge management
- What to build: Agents that probe for missing context and synthesize narratives (from TurtleGym).
- How: Multi-turn questioning templates; trajectory R2G scoring to value early pruning questions.
- Dependencies: Content policies; evaluation rubrics for creativity; human review loops.
- Assumptions: Open-ended tasks can still use incremental rewards tied to story progress.
- Hypothesis testing for rapid information narrowing
- Sector: research, support triage, product troubleshooting
- What to build: “Twenty-questions” style agents (from TelepathyGym) for fault isolation or entity identification.
- How: Train to prioritize high-information-gain questions; measure Effective Turns to ensure concise probing.
- Dependencies: Domain knowledge bases; observable end-state or validator; user-provided hints.
- Assumptions: Users provide cooperative, incremental cues (the paper finds real users often do).
- Programmatic web search and answer verification
- Sector: search, knowledge work
- What to build: Search copilots that justify claims with retrieved evidence (from SearchGym).
- How: Use Search tool; enforce Answer only when confidence passes threshold; use trajectory R2G to reward early, useful retrieval.
- Dependencies: Search API; citation verification; latency budgets.
- Assumptions: Retrieval quality sufficient; answers can be graded via EM/Exact Match or rubric.
- Pattern and rule induction for operations/data cleaning
- Sector: data operations, finance operations, QA
- What to build: Agents that infer hidden mappings or business rules from examples (from FunctionGym).
- How: Structured example-collection via Action; final Answer validates rule correctness.
- Dependencies: Ground-truth validators; representative examples; input sanitation.
- Assumptions: Mapping tasks admit verifiable tests; interactions remain within turn limits.
- A practical RL training recipe for interactive agents
- Sector: ML platforms, applied research groups
- What to build: A “UserRL training harness” with SFT cold start + Equalized turn-level signals + trajectory R2G scoring, using open-source simulators (e.g., Qwen3-32B) for cost.
- How: Implement group-wise advantage normalization (GRPO-style), 8 rollouts per query, cap at ~16 turns; measure Effective Turns and Time-Weighted Performance.
- Dependencies: Compute budget; reproducible gym states; VERL or equivalent RL infra.
- Assumptions: Removing KL helps exploration without unacceptable drift; safety filters in loop.
- Benchmarking and A/B testing of agent interaction quality
- Sector: academia, industry R&D, product analytics
- What to build: A standardized evaluation harness across Intent/Travel/Tau/Persuade/Telepathy/Search gyms for pre-launch A/B tests of agent flows.
- How: Adopt the standardized tool interface and metrics; monitor efficiency-effectiveness trade-offs.
- Dependencies: CI pipelines; logging; privacy-preserving dataset handling.
- Assumptions: Gym scores correlate with live KPIs (conversion, resolution time, CSAT).
Long-Term Applications
These opportunities require further research, scaling, or policy development before routine deployment.
- Learned turn-level reward models that capture “useful” questions
- Sector: ML research, software platforms
- What to build: Reward models that infer turn utility from context, beyond simple heuristics (EM/R2G), tuned per environment.
- Dependencies: Human preference data, offline feedback logs, counterfactual evaluation.
- Assumptions: Turn utility can be reliably labeled or inferred; avoids reward gaming.
- Personalized user simulators with diverse profiles
- Sector: education, healthcare intake, finance advisory
- What to build: Simulator libraries with parameterized goals, styles, and constraints to match real user heterogeneity.
- Dependencies: Synthetic persona generation with guardrails; fairness auditing; profile coverage metrics.
- Assumptions: Sim-to-real transfer improves with profile diversity; privacy-preserving synthesis.
- On-policy human-in-the-loop RL for live assistants
- Sector: customer service, enterprise software, public services
- What to build: Safe reinforcement learning pipelines that incorporate real-time human feedback within multi-turn interactions.
- Dependencies: Risk controls, rollback mechanisms, differential privacy; human QA staffing.
- Assumptions: Feedback can be captured without degrading user experience; safety and compliance satisfied.
- Regulation-ready persuasion frameworks
- Sector: policy, legal compliance, regulated industries
- What to build: Standardized guidelines and audit trails for ethical persuasion (e.g., disclosure, opt-in, prohibited topics).
- Dependencies: Policy standards bodies; auditable logs mapping turns to rewards; external oversight.
- Assumptions: Consensus on boundaries of acceptable persuasion; enforceable compliance checks.
- Cross-domain tool-use orchestration at scale
- Sector: robotics, DevOps, procurement, healthcare ops
- What to build: Agents that chain tools across domains, optimizing turn efficiency and safety when stakes are higher.
- Dependencies: Reliable tool schemas; rollback/transactionality; formal verification for high-risk actions.
- Assumptions: Verifiers exist for outcomes; users accept structured dialogues in critical workflows.
- Curriculum RL across gyms for generalist interaction skills
- Sector: academia, foundation model labs
- What to build: Multi-gym curricula that sequence capability acquisition (intent → search → tool use → strategy).
- Dependencies: Automated curriculum schedulers; transfer measurement; catastrophic forgetting defenses.
- Assumptions: Skills transfer positively; trajectory-level scoring scales to multi-gym curricula.
- Robust evaluation standards that reduce benchmark leakage
- Sector: academic benchmarking, standards organizations
- What to build: Standardized, tool-mediated multi-turn benchmarks with leakage-resistant protocols and mixed real/sim users.
- Dependencies: Community datasets; sequestered test sets; reproducible simulators with versioning.
- Assumptions: Community adoption; stable, transparent scoring.
- Safety-first exploration strategies for interactive RL
- Sector: safety research, high-stakes domains (healthcare, finance)
- What to build: Constrained RL or risk-sensitive objectives layered onto UserRL so exploration never violates safety norms.
- Dependencies: Safe action sets; risk estimators; red-team simulators.
- Assumptions: Constraints can be codified in the tool interface and reward shaping.
- Multimodal user-centric agents
- Sector: education, accessibility, field service
- What to build: Agents that gather clarifications via speech, vision, or forms, optimized with trajectory-level scoring.
- Dependencies: VLMs/ASR; multimodal tool interface; evaluators that score non-text turns.
- Assumptions: Turn rewards generalize to multimodal signals; latency remains acceptable.
- Marketplace of validated user simulators
- Sector: ML tooling ecosystem
- What to build: A hub where teams share, version, and certify simulators for specific domains with documented biases and coverage.
- Dependencies: Documentation standards; simulator validation suites; licensing models.
- Assumptions: Simulator quality correlates with downstream agent robustness; IP and privacy respected.
Notes on Assumptions and Dependencies Across Applications
- SFT cold start is often necessary to avoid RL plateaus; SFT data quality strongly impacts outcomes.
- Trajectory-level R2G scoring is a decisive lever; turn-level shaping helps but is secondary.
- Open-source simulated users (e.g., Qwen3-32B) are cost-effective and transfer reasonably; stronger simulators (e.g., GPT-4o) can accelerate training but raise costs.
- Standardized tool interfaces (Action/Search/Answer) improve rigor and reproducibility but may reduce “naturalness”; expect some performance drop vs. free-form chat.
- Metrics should balance efficiency (Time-Weighted Performance) and effectiveness (task completion), as excessive questioning harms UX.
- Safety, compliance, and privacy are cross-cutting dependencies, especially in persuasion, healthcare, and finance contexts.
Glossary
- Adaptive Interaction: Refers to the ability of agents to dynamically adjust their actions in response to evolving user inputs or conditions. Example: "The most capable agent is one that can understand, adapt to, and actively support the user throughout the task."
- Agentic Models: Models specifically designed to act as autonomous agents, often characterized by their ability to make decisions and perform actions in a variety of settings. Example: "Reinforcement learning (RL) has emerged as a powerful approach for training agentic LLMs."
- GRPO Algorithm: An advanced reinforcement learning algorithm that operates on group-based trajectory scoring. Example: "Our experiments across Qwen3 models reveal three key findings... analyze how different formulations affect learning under the GRPO algorithm."
- Reward Shaping: The process of designing reward functions in reinforcement learning to guide the model toward desired behaviors. Example: "These results highlight that careful design of reward shaping and user simulation choice is as crucial as model scale..."
- SFT Cold Start: Refers to initializing a reinforcement learning model with supervised fine-tuning before applying reinforcement learning strategies. Example: "SFT cold start is critical for unlocking initial interaction ability and enabling sustained RL improvements."
- Trajectory Scoring: The technique of evaluating a sequence of actions taken by agents in reinforcement learning. Example: "We systematically vary turn-level reward assignment and trajectory-level score calculation..."
- User-Centric Agent: An agent designed with a focus on effectively interacting with and supporting users through dynamic and personalized engagement. Example: "Yet, the ultimate value of such agents lies in their ability to assist users, a setting where diversity and dynamics of user interaction pose challenges."
- UserRL: A proposed framework for training agents specifically to improve user interaction capabilities via reinforcement learning. Example: "In this work, we propose UserRL, a unified framework for training and evaluating user-centric abilities..."
- Tool-Using Agents: Agents equipped with the capability to use external tools as part of their decision-making and problem-solving process. Example: "Many real tasks demand sequences of tool calls, intermediate reasoning steps, and iterative refinements..."
- Multi-Turn Interaction: An interaction style in reinforcement learning where the agent engages in various distinct interaction steps or turns to solve tasks or assist users. Example: "Multi-turn rollout is not optional but necessary: many real tasks demand sequences of tool calls..."
Collections
Sign up for free to add this paper to one or more collections.

