MAPO: Mixed Advantage Policy Optimization
Abstract: Recent advances in reinforcement learning for foundation models, such as Group Relative Policy Optimization (GRPO), have significantly improved the performance of foundation models on reasoning tasks. Notably, the advantage function serves as a central mechanism in GRPO for ranking the trajectory importance. However, existing explorations encounter both advantage reversion and advantage mirror problems, which hinder the reasonable advantage allocation across different query samples. In this work, we propose an easy but effective GRPO strategy, Mixed Advantage Policy Optimization (MAPO). We reveal that the trajectory appears with different certainty and propose the advantage percent deviation for samples with high-certainty trajectories. Furthermore, we dynamically reweight the advantage function for samples with varying trajectory certainty, thereby adaptively configuring the advantage function to account for sample-specific characteristics. Comparison with related state-of-the-art methods, along with ablation studies on different advantage variants, validates the effectiveness of our approach.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train large AI models (called foundation models) to “think” better when solving problems, like math puzzles or understanding emotions in images. The authors focus on a popular training method called GRPO (Group Relative Policy Optimization), and they propose a simple upgrade named MAPO (Mixed Advantage Policy Optimization) to fix some common issues and make the models more accurate and stable.
What questions did the researchers ask?
To make the explanation clearer, here are the main questions the paper tries to answer:
- How can we improve the way GRPO ranks and rewards the model’s different solution attempts, especially when some questions are very easy or very hard?
- How can we adjust this ranking method so it adapts to each question’s level of “certainty” (whether the model’s attempts are consistently right or wrong)?
- Can this new method make models think more reliably and perform better across different tasks and datasets?
How does their method work?
First, a few simple ideas you need to know:
- Foundation models: Big AI systems that can understand language and images, and can solve problems by producing step-by-step reasoning.
- GRPO: A training method where, for each question, the model creates a group of possible answers (called “trajectories”). Each answer gets a reward (like a score), and the model learns to prefer the better ones.
- Advantage function: Think of it like a ranking score for each answer. Higher advantage means, “This answer was better than average—do more like this!”
The problem with the usual advantage function
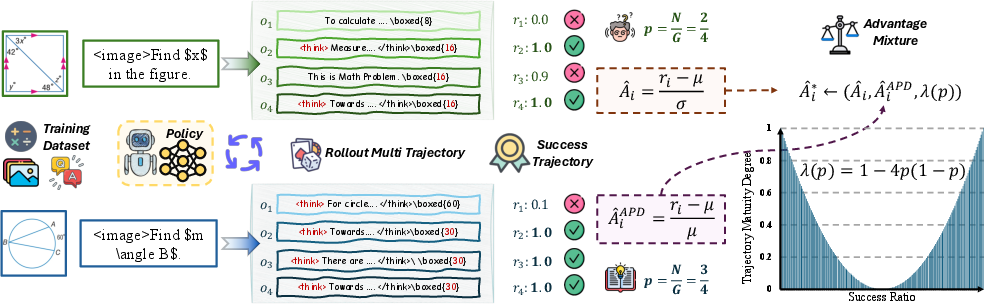
The standard GRPO advantage is like this: take each answer’s reward, subtract the group’s average reward, and divide by how spread out the rewards are (the “standard deviation”). In plain terms, it’s measuring how far above/below average an answer is.
The authors noticed two issues:
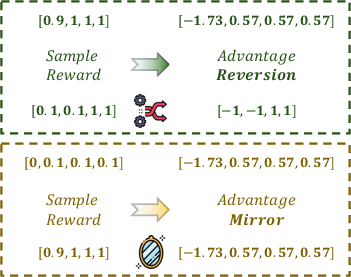
- Advantage reversion: For questions where all attempts are very similar (either mostly correct or mostly incorrect), the “spread” is tiny. Dividing by a tiny number can make small differences look huge, which can unfairly punish or reward answers.
- Advantage mirror: Very easy questions (almost all answers are correct) and very hard questions (almost none are correct) get treated too similarly, even though they’re very different situations. The method doesn’t reflect difficulty levels properly.
Their key idea: let the model adapt based on “trajectory certainty”
Certainty here means how often the model’s attempts succeed for a question.
- If almost all attempts succeed (very easy) or almost all fail (very hard), the question has high certainty: the outcome is consistent.
- If about half succeed and half fail, the question has low certainty: the outcome is mixed.
The authors estimate certainty by counting how many answers in the group are correct. If N out of G attempts are successful, then the certainty is related to the ratio p = N/G.
MAPO: Two parts that work together
To fix the problems, the authors mix two ways of calculating advantage:
- Advantage Percent Deviation (APD): Instead of dividing by the spread (standard deviation), they divide by the average reward. In simple terms, they measure differences as percentages of the average. This is more stable when the spread is tiny and avoids over-penalizing or over-rewarding answers on very consistent questions.
- Trajectory Certainty Reweight (TCR): They smoothly switch between the standard method and APD based on how certain the question is. When the question is uncertain (mixed outcomes), they rely more on the standard method (which uses spread). When the question is very certain (easy or hard), they rely more on APD (which uses percentages of the average).
You can think of it like a smart coach:
- If the class is split—some students get it, some don’t—the coach looks carefully at how far each student is from the average (standard method).
- If the class is very consistent—either almost everyone gets it or almost nobody does—the coach compares students in terms of percentage difference from the average (APD), which is fairer and more stable.
What did they find?
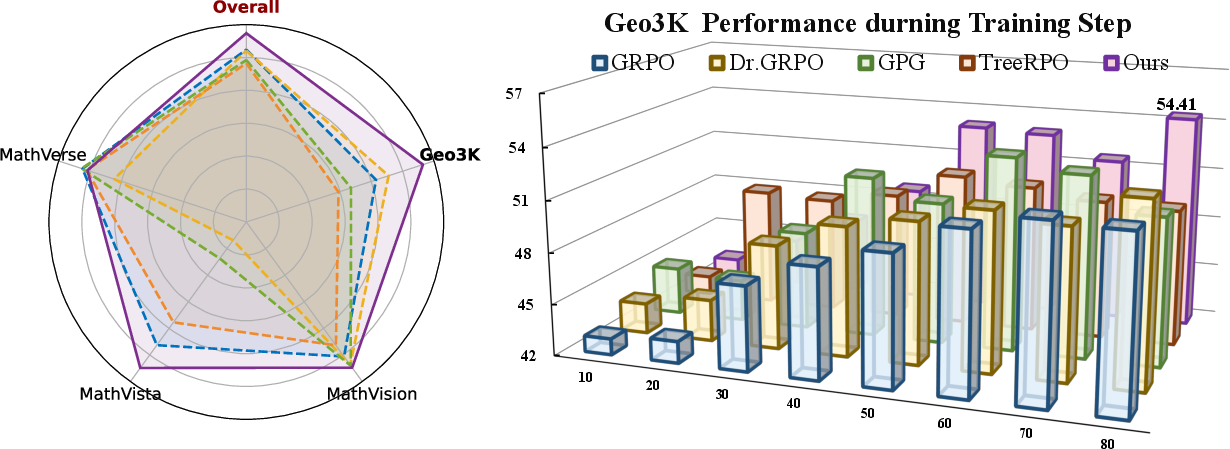
The researchers tested MAPO on two kinds of tasks:
- Math reasoning (Geo3K for training; MathVision, MathVista, MathVerse for testing)
- Emotion recognition in images (EmoSet for training; WEBEmo and Emotion6 for testing)
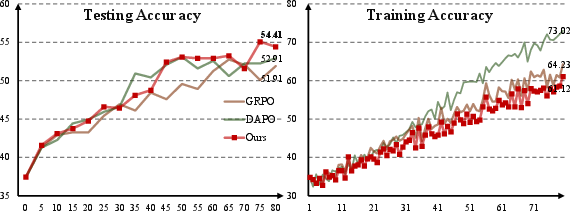
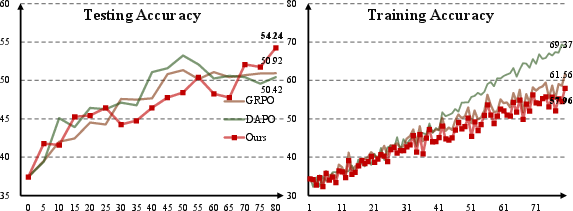
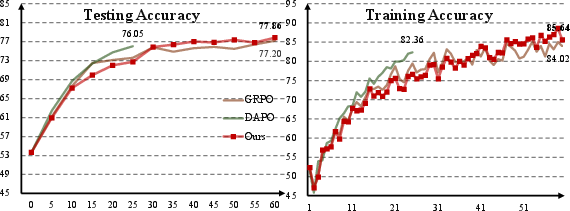
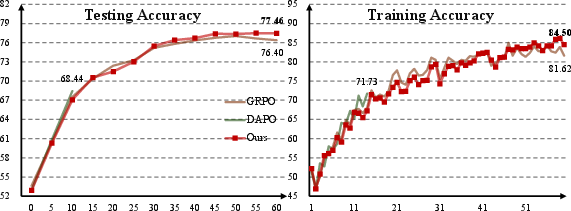
They used a strong open-source model (Qwen2.5-VL-7B-VL-Instruct) and compared MAPO against standard GRPO and a variant called DAPO.
Main results:
- MAPO made the model more accurate overall and more stable during training.
- For math tasks, MAPO increased average accuracy compared to GRPO (for example, from about 49.85% to 51.26% in one setup).
- For emotion tasks, MAPO also nudged accuracy up (for example, from about 66.18% to 66.77%).
- MAPO worked well with different numbers of model attempts per question (both G = 8 and G = 12).
These improvements are meaningful because they come from a method that’s simple, doesn’t need extra reward models, and adapts to each question’s situation.
Why does it matter?
- Better reasoning: Models become more reliable at step-by-step thinking, which is important for math, science, and many practical tasks.
- Stability: The training is less likely to be thrown off by edge cases like very easy or very hard questions.
- No extra complexity: MAPO doesn’t add complicated parts or need extra “hyperparameters” (tuning knobs). It automatically adapts based on the certainty of each question.
In short, MAPO helps foundation models think more carefully and fairly across a wide range of problems.
Implications and impact
- For researchers and developers: MAPO offers a plug-in upgrade for GRPO that’s easy to adopt, reduces brittleness, and boosts generalization to new datasets.
- For future work: The idea of “trajectory certainty” could be used in other training methods, not just GRPO, to make AI learning more robust.
- Limitations to keep in mind: If the model is so weak that it almost never gets any attempt right, certainty becomes trivial (always “low success”), and the method might act like a single strategy. As models become stronger, MAPO’s adaptive mixing becomes more useful.
Key takeaways
- The paper fixes two common issues in GRPO advantage scoring: unfair penalties when rewards are tightly clustered (advantage reversion) and treating very easy and very hard questions too similarly (advantage mirror).
- MAPO mixes two advantage formulas—one based on spread, one based on percentage—using a certainty-aware weight.
- It improves accuracy and training stability on both math and emotion tasks without adding extra training complexity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers can address.
- Certainty estimation robustness: The certainty proxy (with ) assumes binary rewards and i.i.d. Bernoulli trials; its reliability under small rollout counts (e.g., ), correlated samples, or non-binary/continuous rewards is not analyzed. Evaluate variance, bias, and calibration of under realistic sampling regimes.
- Division-by-zero and numerical stability: APD uses . When (e.g., high-certainty failure cases) this is ill-defined. The paper does not specify stabilization (e.g., -clipping) or fallback logic. Characterize failure modes and implement robust safeguards for and .
- High-certainty failure case handling: TCR shifts weight to APD when is near 0 or 1. For , often approaches 0, making APD unstable. Design and test an alternative advantage form for high-certainty failure regimes.
- Generalization beyond binary, verifiable rewards: The approach assumes success is “correct on all reward metrics” (yielding ). Extending MAPO to tasks with continuous/soft rewards (e.g., IoU, BLEU, partial credit) requires (i) a definition of “success” or a new certainty measure, and (ii) a principled way to compute . Provide thresholding or continuous-certainty formulations and validate them.
- Sensitivity to reward design and weights: The reward is a weighted sum of format and accuracy with . There is no sensitivity analysis for or for alternative reward mixes. Quantify how MAPO behaves under different reward compositions and task-specific reward functions.
- Choice of certainty weighting function: is ad hoc. There is no comparison to alternative schedules (e.g., temperature-scaled, asymmetric, data-driven, or learned mappings). Explore design space and justify the functional form with theory or empirical selection.
- Theoretical guarantees under full GRPO: The gradient ratio analysis assumes Bernoulli rewards and ignores clipping and KL regularization. Provide theory that incorporates PPO clipping, KL penalty, and non-binary rewards to assess stability and convergence of MAPO.
- Quantifying “advantage reversion” and “advantage mirror”: The paper motivates these phenomena qualitatively but offers no formal metrics or diagnostics. Define measurable criteria and report how MAPO reduces them across datasets and training stages.
- Reliability across sampling temperatures and decoding strategies: Certainty () depends on generation stochasticity (temperature, top-k/p). The paper does not study how decoding settings affect and MAPO’s performance. Systematically evaluate across sampling configurations.
- Estimation smoothing over training: is estimated per batch from a single group of rollouts. Investigate temporal smoothing (e.g., moving averages, Bayesian estimates, Kalman filtering) to reduce sampling noise in certainty estimation.
- Per-trajectory vs per-sample adaptation: TCR mixes advantages at the sample level. Explore trajectory-level or token-level adaptation (e.g., weighting advantages by per-trajectory reward variance) to better handle heterogeneous rollouts within a group.
- Handling degenerate groups (): The method does not specify behavior when all rewards in a group are identical (commonly filtered by DAPO/GPG). Provide a principled strategy for degenerate groups (e.g., resampling, gradient rescaling, certainty-aware fallback).
- Interaction with KL regularization: MAPO’s effects under varying KL coefficients and reference models are not analyzed. Study how MAPO interacts with (KL strength), reference policy quality, and KL schedules.
- Entropy and exploration dynamics: The method aims to modulate emphasis by certainty but does not report effects on policy entropy, exploration/exploitation balance, or collapse prevention. Track entropy metrics and investigate exploration impacts.
- Scalability and generality: Experiments are limited to Qwen2.5-VL-7B, ~2.1k training samples, and two domains (math, emotion). Validate MAPO on larger models (≥70B), text-only reasoning (e.g., GSM8K, LogiQA), code, scientific QA, and multilingual settings.
- Statistical reliability: Results are reported without multiple seeds or statistical significance testing. Provide variance across seeds, confidence intervals, and robustness checks (e.g., different initializations, datasets splits).
- Breadth of baselines: Empirical comparisons omit several relevant GRPO variants (e.g., SEED-GRPO, KRPO, TreeRPO in full-scale studies) and PPO-style learned critics. Include broader baselines to contextualize MAPO’s gains.
- Computational overhead and training stability: While MAPO is “architecture-free,” the paper does not quantify runtime, memory overhead, or training stability (e.g., gradient norms, divergence incidents). Report and compare wall-clock, GPU-hours, and failure rates.
- Dynamic rollout schedules: Only are tested. Examine sensitivity to over a wider range and dynamic schedules (e.g., adaptive based on certainty or training stage).
- Integration with process-level rewards: MAPO operates on terminal rewards; its compatibility with stepwise thinking rewards (e.g., step consistency, hint rewards) is not evaluated. Test MAPO with process-level reward models and hybrid RL signals.
- Certainty asymmetry between “too easy” and “too hard”: APD is intended to distinguish extremes, but its practical behavior under vs is not deeply analyzed. Probe asymmetries and propose tailored handling if needed.
- Reproducibility details: Key training hyperparameters (e.g., PPO clip , learning rates, KL schedules, sampling temperature) and implementation choices (e.g., epsilon stabilizers) are insufficiently specified for reproduction. Release detailed configs/code and ablation on these settings.
- OOD generalization characterization: While OOD datasets are used, the paper does not analyze which aspects of MAPO drive OOD gains (e.g., certainty distribution shifts, reward dispersion). Provide diagnostics linking certainty profiles to OOD performance.
- Potential to learn : Investigate learning the mixing function (e.g., small network conditioned on reward statistics) or meta-optimizing it, to replace hand-crafted and adapt across tasks/datasets.
- Success criterion design: “Success if correct on all reward metrics” may be overly strict for tasks with partial credit or soft constraints. Explore alternative success criteria and assess their impact on and MAPO.
- Safety/robustness in practice: Formalize safeguards (clipping, bounds, normalization) to ensure MAPO does not produce outlier advantages that destabilize training, and evaluate their necessity/impact empirically.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling by teams already using GRPO/RFT-style reinforcement learning for foundation model post-training and tasks with verifiable rewards.
- Certainty-aware GRPO post-training to improve reasoning stability and accuracy in foundation models (Software/AI)
- What: Replace GRPO’s fixed advantage with MAPO’s APD + TCR to reduce advantage reversion/mirror and stabilize updates.
- Where: RL post-training pipelines for LLMs/MLLMs (e.g., TRLX, DeepSpeed-Chat, vLLM fine-tuning).
- Tools/Workflows: A MAPO plugin/module that computes trajectory certainty p=N/G per prompt, switches to APD for high-certainty samples, and logs certainty metrics; integrate with rule-based rewards (format + accuracy).
- Assumptions/Dependencies: Requires verifiable rewards and multi-rollout sampling per prompt; gains are most pronounced on tasks with discrete correctness (e.g., math, classification); APD division by μ needs safeguards when μ≈0.
- Multimodal math/diagram reasoning for tutoring and technical support (Education, Enterprise software)
- What: Improved chain-of-thought reliability for geometry, charts, and diagrams; better out-of-domain generalization (as shown on MathVision/MathVista/MathVerse).
- Where: Educational tutors, engineering support tools, enterprise document Q&A.
- Tools/Workflows: RL-tuned MLLM tutors using MAPO over geometry/problem-solving datasets; verifiable numeric or multiple-choice answers.
- Assumptions/Dependencies: Requires high-quality, labeled math/diagram datasets and rule-based reward design; supervision for safe/accurate explanations.
- Sentiment and emotion understanding in content moderation and marketing (Media/Advertising, Safety)
- What: More robust emotion classification and reasoning across domains (validated on EmoSet/WEBEmo/Emotion6).
- Where: Moderation pipelines, brand sentiment tracking, ad targeting, customer feedback analysis.
- Tools/Workflows: MLLM + MAPO RL tuning with format/accuracy rewards for emotion labels; multimodal inputs (images + text).
- Assumptions/Dependencies: Clearly defined label taxonomies and verifiable metrics; careful evaluation for bias/fairness.
- LLMOps training diagnostics using trajectory certainty (MLOps/DevOps)
- What: Use p=N/G and λ(p)=1−4p(1−p) as training health indicators to detect entropy collapse, over-easy prompts, and data drift.
- Where: Model monitoring dashboards and training controllers.
- Tools/Workflows: Certainty-aware dashboards, auto-curation to prefer prompts near p≈0.5 for signal-rich updates, and adaptive rollout scheduling.
- Assumptions/Dependencies: Instrumentation to compute and log per-prompt certainty; applicable when prompts produce multiple trajectories per batch.
- Cost-effective RL post-training without extra critics (AI startups/Platform teams)
- What: Eliminate learned reward critics and reduce hyperparameter tuning by leveraging MAPO’s rule-based, certainty-aware advantage.
- Where: Small teams fine-tuning models for niche reasoning tasks.
- Tools/Workflows: MAPO-enabled GRPO pipelines with off-the-shelf reward rules; fewer knobs to tune, quicker iteration cycles.
- Assumptions/Dependencies: Tasks must support rule-based verification; compute budget must allow multiple rollouts.
- Curriculum-aware sampling for faster learning (Academia/Research)
- What: Exploit certainty to prioritize prompts that maximize learning signal (around p≈0.5) while still emphasizing hard samples (p<0.5) as training matures.
- Tools/Workflows: Data schedulers using MAPO’s certainty λ(p) to shape sampling distribution dynamically.
- Assumptions/Dependencies: Sufficient prompt diversity; careful balance to avoid overfitting on mid-certainty prompts.
- Consumer reasoning assistants with more reliable step-by-step outputs (Daily life/Consumer apps)
- What: Improved reliability in math help, budgeting calculations, and visual reasoning (e.g., reading charts/receipts).
- Tools/Workflows: RL-tuned assistants using MAPO; user-facing verifiable tasks (checkable answers, test cases).
- Assumptions/Dependencies: Accurate reward rules; guardrails for safety and user privacy.
Long-Term Applications
These directions require further research, scaling, domain adaptation, safety evaluation, and/or standards development before broad deployment.
- Clinical and medical reasoning with verifiable tasks (Healthcare)
- What: Certainty-aware advantage for diagnostic support and medical question answering on tasks with rule-driven checks (e.g., guideline compliance, dosages).
- Potential Tools/Products: MAPO-based medical copilots; audit-friendly RL pipelines with explicit certainty metrics.
- Assumptions/Dependencies: Domain-specific, validated reward functions; rigorous safety, bias, and regulatory compliance; large-scale clinical datasets.
- Certainty-weighted advantage in embodied and continuous-control RL (Robotics/Autonomy)
- What: Adapt MAPO’s trajectory certainty concept to on-policy/continuous rewards (e.g., success rates or thresholded returns) to improve sample efficiency.
- Potential Tools/Products: Robotics RL libraries with certainty-aware advantage switchers; training monitors that track episode-level success probabilities.
- Assumptions/Dependencies: Robust mapping from continuous rewards to “certainty”; stable interpolation between variance-sensitive and mean-relative advantages; extensive benchmarking.
- Financial compliance and risk reasoning copilots (Finance/Legal)
- What: More reliable reasoning for regulatory Q&A, policy adherence, and audit trails using certainty-aware training and verifiable checks.
- Potential Tools/Products: Compliance copilots with RL-tuned reasoning; automated audit reports using certainty metrics.
- Assumptions/Dependencies: Formalizable reward rules for compliance tasks; domain datasets; human-in-the-loop validation.
- Engineering and energy planning assistants (Energy/Industrial engineering)
- What: Improved step-by-step calculations, safety checks, and procedure validation with verifiable outputs (e.g., unit consistency, tolerance ranges).
- Potential Tools/Products: Certainty-aware, RL-tuned engineering copilots for power systems, HVAC, structural design.
- Assumptions/Dependencies: Domain-accurate reward functions; high-quality labeled tasks; integration into existing engineering workflows.
- Standards and governance for transparent post-training with rule-based rewards (Policy/Governance)
- What: Best practices and tooling that favor verifiable, auditable RL training (no opaque critic), with certainty logs for oversight.
- Potential Tools/Products: Certification guidelines; audit tooling to track MAPO metrics and decisions.
- Assumptions/Dependencies: Community and regulatory acceptance; alignment testing; frameworks for reporting model training dynamics.
- AutoML for RL post-training: self-optimizing advantage selection (Software/AI platforms)
- What: Meta-controllers that learn when to emphasize variance-based vs. mean-relative advantages beyond the fixed λ(p), potentially task-dependent.
- Potential Tools/Products: Auto-tuners for advantage functions; learned schedulers that generalize across tasks.
- Assumptions/Dependencies: Large-scale experiments, diverse tasks, and robust generalization; safeguards against reward hacking.
- Scaling MAPO to larger models and open-ended tasks (Cross-sector)
- What: Extend certainty-aware advantage to mixed discrete/continuous or proxy rewards (e.g., rubric scoring, weak supervision) for complex reasoning.
- Potential Tools/Products: Hybrid reward formulations that keep MAPO’s adaptability while handling non-binary success; multimodal reasoning benchmarks at scale.
- Assumptions/Dependencies: New reward designs for open-ended outputs; compute for large rollouts; generalized proof-of-stability and safety analyses.
Glossary
- Advantage function: In policy gradient RL, a measure of how much better or worse a trajectory is compared to a baseline, guiding updates toward better behaviors. "the advantage function serves as a central mechanism for ranking the importance of trajectory candidates."
- Advantage Mirror: A failure mode where symmetric reward patterns receive mirrored advantages, making easy and hard cases look equivalent under normalization. "Similarly, as for Advantage Mirror, two reward batches that are symmetric around the center"
- Advantage Percent Deviation (APD): A mean-relative advantage formulation defined as (r_i − μ)/μ that emphasizes percentage deviation, improving stability when variance is small. "we introduce the Advantage Percent Deviation (APD), which replaces the advantage from standard z-score normalization to relative normalization."
- Advantage Reversion: A failure mode where small variance causes high-certainty samples to be over-penalized or over-rewarded relative to low-certainty ones. "Advantage Reversion: high-certainty samples may receive more differentiated advantage allocations than low-certainty ones."
- Auto-regressive: A generation paradigm where each token is produced conditioned on previously generated tokens. "perform various vision-language tasks in an auto-regressive manner."
- Bernoulli random variable: A binary random variable taking values in {0,1} with success probability p, used to model trajectory success. "We model the trajectory outcome as a Bernoulli random variable, "
- Binomial distribution: The distribution governing the number of successes in repeated Bernoulli trials, used for counts of successful trajectories. "the number of successes over repeated draws follows a binomial distribution"
- Chain-of-Thought (CoT): Explicit, step-by-step reasoning traces generated by models to solve problems. "long Chain of Thought (CoT) generation."
- Clipping (PPO clipping): Bounding the policy ratio in PPO’s surrogate objective to prevent destabilizing updates. "f_\epsilon(x, y) = \min(xy, \text{clip}(x, 1-\epsilon, 1 + \epsilon)y)"
- Data augmentation: Techniques that perturb inputs to expand and diversify training data for better generalization. "constructing the data augmentation technique for Multimodal LLM to enhance both the quantity and quality of training data."
- Direct Preference Optimization (DPO): A preference-based alignment objective that learns policies directly from comparisons without a learned reward model. "direct preference optimization"
- Dominance-preserving mixup: A specific augmentation that mixes samples while preserving dominant content or labels. "dominance-preserving mixup"
- Group Relative Policy Optimization (GRPO): A group-based RL method that samples multiple trajectories per prompt and computes relative advantages for policy updates. "Group Relative Policy Optimization (GRPO) is introduced as a popular reinforcement strategy."
- Intersection over Union (IoU): An overlap metric for comparing predicted and ground-truth regions, used here as a verifiable reward. "proposes the intersection over union reward for object detection."
- Kalman filter: A recursive estimator for latent states (e.g., mean/variance), used to stabilize advantage estimation. "introduces a lightweight Kalman filter approach for accurate advantage estimation."
- KL divergence: A measure of discrepancy between two probability distributions, often used as a regularizer in RL. ""
- KL regularization: Penalizing divergence from a reference policy to stabilize training and prevent policy drift. "ignoring clipping and KL regularization"
- Multimodal LLM (MLLM): An LLM augmented with visual encoders/tokens to process both images and text. "the development of Multimodal LLM (MLLM) systems"
- Noise annealing schedule: A procedure that adjusts noise magnitude over time to control difficulty or diversity during training/sampling. "leverages the noise annealing schedule to construct the noisy image text pairs."
- Proximal Policy Optimization (PPO): A policy gradient algorithm that uses a clipped surrogate objective for stable updates. "Group Relative Policy Optimization (GRPO) is a variant of Proximal Policy Optimization (PPO)"
- Rollout: A sampled trajectory (model output) used to compute rewards and advantages for RL updates. "Assume rollout number ."
- Semantic entropy: An uncertainty measure over output semantics used to reweight advantages or updates. "reweights the advantages based on the semantic entropy to measure the output uncertainty."
- Trajectory certainty: The degree of consistency of success across a group of sampled trajectories for a prompt, often linked to p(1−p). "we first define trajectory certainty within the sampling group."
- Trajectory Certainty Reweight (TCR): A certainty-aware mixing of advantage formulations (e.g., standard vs. APD) to adapt updates to sample difficulty. "we propose the Trajectory Certainty Reweight (TCR) to determine the sample advantage function based on trajectory certainty."
- Z-score normalization: Standardization by subtracting the mean and dividing by the standard deviation. "standard z-score normalization"
Collections
Sign up for free to add this paper to one or more collections.

