- The paper introduces GSFix3D, distilling a fine-tuned diffusion model into a 3D Gaussian Splatting framework to robustly repair artifacts.
- It employs dual-input conditioning with mesh and 3DGS renderings plus random mask augmentation to enhance inpainting in under-constrained regions.
- Experimental results demonstrate up to 5 dB PSNR gains, validating the method's effectiveness across challenging benchmarks and real-world scenarios.
Diffusion-Guided Repair of Novel Views in Gaussian Splatting: The GSFix3D Framework
Introduction and Motivation
The GSFix3D framework addresses a persistent challenge in 3D Gaussian Splatting (3DGS): the generation of artifact-free, photorealistic renderings from novel viewpoints, especially in regions with sparse observations or incomplete geometry. While 3DGS offers explicit, differentiable scene representations and fast rendering, its reliance on dense input views leads to visible artifacts—holes, floaters, and unnatural geometry—when extrapolating to under-constrained regions. Existing generative diffusion models, such as Stable Diffusion, possess strong priors for plausible image synthesis but lack scene-specific consistency and are not directly applicable to 3D repair tasks. GSFix3D bridges this gap by distilling the generative power of diffusion models into the 3DGS pipeline, enabling robust artifact removal and inpainting for novel view synthesis.
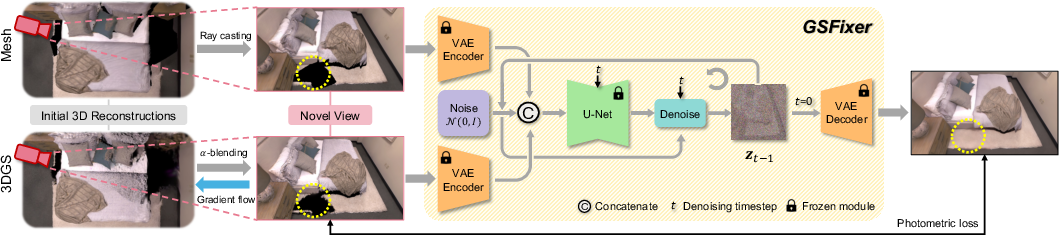
Figure 1: System overview of the proposed GSFix3D framework for novel view repair. Given initial 3D reconstructions in the form of mesh and 3DGS, we render novel views and use them as conditional inputs to GSFixer. Through a reverse diffusion process, GSFixer generates repaired images with artifacts removed and missing regions inpainted. These outputs are then distilled back into 3D by optimizing the 3DGS representation using photometric loss.
Methodology
Customized Fine-Tuning Protocol
GSFix3D introduces GSFixer, a latent diffusion model fine-tuned for scene-adaptive novel view repair. The fine-tuning protocol leverages both mesh and 3DGS renderings as conditional inputs, exploiting their complementary strengths: mesh reconstructions provide coherent geometry in under-constrained regions, while 3DGS excels in photorealistic appearance near well-observed areas. The conditional distribution modeled is p(Igt∣Imesh,Igs), where Igt is the ground truth RGB image, Imesh is the mesh rendering, and Igs is the 3DGS rendering.
The architecture adapts a pretrained Stable Diffusion v2 U-Net, expanding its input channels to accommodate concatenated mesh and 3DGS latent codes. The first layer weights are duplicated and normalized to preserve initialization statistics, ensuring stable adaptation.
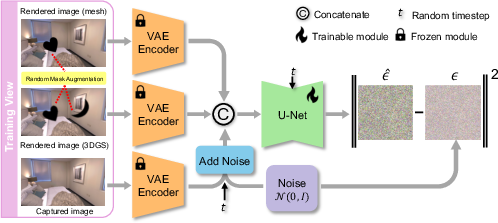
Figure 2: Illustration of the customized fine-tuning protocol for adapting a pretrained diffusion model into GSFixer, enabling it to handle diverse artifact types and missing regions.
Data Augmentation for Inpainting
To address the lack of missing regions in training data, GSFix3D employs a random mask augmentation strategy. Semantic masks derived from real-world object annotations are randomly applied to mesh and 3DGS renderings, simulating occlusions and under-constrained regions. Gaussian blur is used to approximate soft boundaries typical of 3DGS artifacts. This augmentation is critical for enabling GSFixer to generalize inpainting capabilities to real novel views.
Inference and 3D Distillation
At inference, GSFixer receives mesh and 3DGS renderings from novel viewpoints, encodes them into the latent space, and performs iterative denoising using a DDIM schedule. The output is a repaired image with artifacts removed and missing regions plausibly filled. These enhanced images are then used to optimize the underlying 3DGS representation via photometric and SSIM loss, with adaptive density control to populate previously empty regions. The repaired views and poses are appended to the training set for further multi-view optimization, improving global consistency.
Experimental Results
Quantitative and Qualitative Evaluation
GSFix3D and GSFixer are evaluated on ScanNet++ and Replica benchmarks, comparing against DIFIX and DIFIX-ref, as well as SplaTAM, RTG-SLAM, and GSFusion reconstructions. GSFixer consistently outperforms baselines in PSNR, SSIM, and LPIPS, with up to 5 dB PSNR gain in challenging settings. The dual-input configuration (mesh+3DGS) yields further improvements over single-input variants, validated by ablation studies.
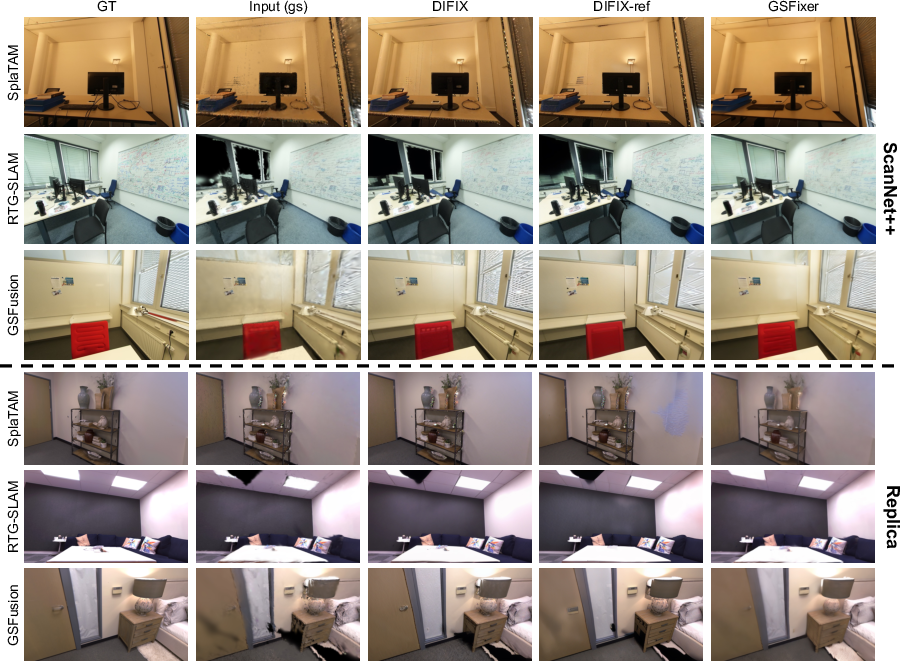
Figure 3: Qualitative comparisons of diffusion-based repair methods on the ScanNet++ and Replica datasets. All examples use only 3DGS reconstructions as the input source. GSFixer effectively removes artifacts and fills in large holes, where both DIFIX and DIFIX-ref fail to produce satisfactory results.

Figure 4: Qualitative comparison between GSFixer and GSFix3D on the ScanNet++ and Replica datasets. Both mesh and 3DGS reconstructions from GSFusion are used as input sources. The 2D visual improvements from GSFixer are effectively distilled into the 3D space by GSFix3D.
Real-World Robustness
GSFix3D demonstrates resilience to pose errors in real-world data, as shown on self-collected ship sequences and outdoor scenes. The method effectively removes shadow-like floaters and repairs broken geometries, even when initial reconstructions are degraded by inaccurate poses.

Figure 5: Novel view repair on self-collected ship data. The method is robust to pose errors, effectively removing shadow-like floaters.
Ablation Studies
Ablations confirm the necessity of dual-input conditioning and random mask augmentation. Dual-input models consistently outperform single-input variants, leveraging complementary cues to resolve artifacts. Mask augmentation is essential for inpainting large missing regions, as evidenced by improved quantitative metrics and visual fidelity.

Figure 6: Qualitative ablation of input image conditions on the ScanNet++ and Replica datasets. Artifacts present in single-input settings are effectively mitigated with the dual-input configuration.

Figure 7: Qualitative ablation of random mask augmentation on the Replica dataset. The differences in inpainting quality highlight the improved ability to fill large missing regions when augmentation is used.
Implementation Considerations
- Computational Requirements: Fine-tuning GSFixer requires only a few hours per scene on a single consumer GPU (24GB VRAM), with pretraining on small synthetic datasets. DIFIX-finetune, by contrast, demands significantly more memory and curation.
- Data Requirements: No large-scale real noisy-clean image pairs are needed; only the captured RGB images and corresponding reconstructions suffice.
- Integration: GSFixer is plug-and-play, compatible with various 3DGS pipelines (SplaTAM, RTG-SLAM, GSFusion), and can be extended to other explicit 3D representations.
- Scalability: The framework supports efficient inference (4 DDIM steps) and multi-view optimization, making it suitable for real-time or large-scale applications.
Implications and Future Directions
GSFix3D demonstrates that diffusion models, when properly adapted and conditioned, can be effectively integrated into explicit 3D reconstruction pipelines for robust artifact removal and inpainting. The dual-input design and mask augmentation are critical for generalization and high-fidelity repair. The framework's minimal data and compute requirements make it practical for deployment in consumer-grade and field robotics scenarios.
Future research may explore:
- Extending the approach to unbounded or outdoor scenes with more complex occlusions.
- Incorporating temporal consistency for video-based SLAM and dynamic scene repair.
- Adapting the protocol for other generative backbones or multi-modal conditioning (e.g., LiDAR, thermal).
- Investigating self-supervised or online adaptation for lifelong mapping.
Conclusion
GSFix3D sets a new standard for novel view repair in 3DGS reconstructions, combining efficient scene-adaptive fine-tuning, dual-input conditioning, and robust inpainting via random mask augmentation. The resulting GSFixer model consistently outperforms prior diffusion-based methods across diverse benchmarks and real-world scenarios, requiring only minimal fine-tuning and no large-scale curated datasets. The framework's adaptability, efficiency, and robustness position it as a practical solution for high-fidelity 3D reconstruction and novel view synthesis in both research and applied domains.