- The paper demonstrates that language models pretraining on simplified texts reduce perplexity losses, especially in smaller models.
- It employs Llama 3.1 to generate simplified versions of texts while preserving core semantic content for effective comparison.
- The findings suggest that text complexity impacts zero-shot and fine-tuned task performance differently, informing data curation strategies.
Rethinking the Role of Text Complexity in LLM Pretraining
Introduction and Research Questions
The importance of data quality and size in model pretraining has been recognized, yet the impact of text complexity remains underexplored. This paper investigates whether pretrained models require complex texts to learn effective representations or if simpler texts suffice. The authors seek to answer three primary questions: how text complexity affects language modeling across model sizes, whether useful representations can be derived from simpler texts, and how text complexity influences downstream performance on language understanding tasks. To address these questions, human-written texts were simplified using a LLM, after which models of varying sizes (28M–500M parameters) were pretrained independently on both original and simplified datasets.
Methodology
The simplified corpus was created by prompting Llama 3.1 to generate more straightforward versions of human-written texts while preserving core content. The corpus metrics reveal that the simplified texts feature reduced lexical diversity and syntactic complexity while maintaining semantic similarity to the originals (Figure 1).
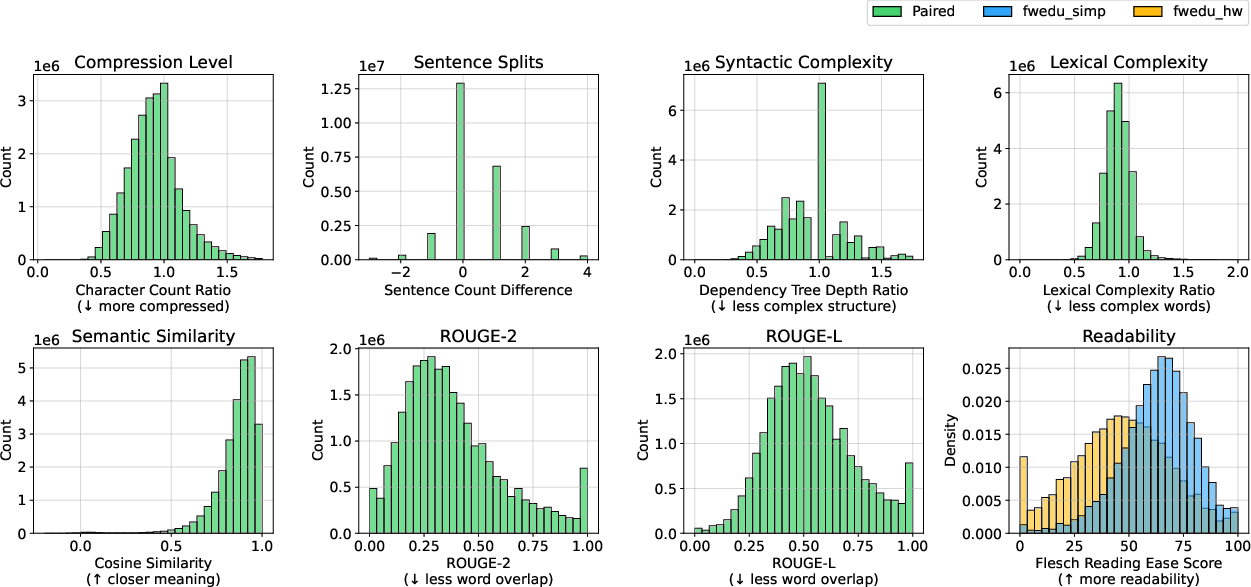
Figure 1: Corpus Features distribution indicates that simplified texts are shorter, use simpler structures, and maintain semantic similarity to original texts, highlighting systematic differences in readability.
LLMs were pretrained from scratch and later evaluated through fine-tuning and zero-shot testing. The fine-tuning involved tasks from GLUE and SuperGLUE, while zero-shot tests examined linguistic knowledge, entity tracking, and commonsense reasoning.
Results
The study showed that model performance on language modeling tasks is sensitive to the interaction between model capacity and text complexity. Smaller models experienced less performance degradation on simpler texts, which suggests that such models benefit from the reduced complexity (Figure 2).
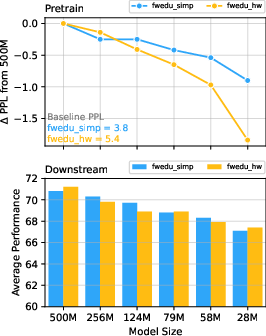
Figure 2: Perplexity degradation is more pronounced for models trained on human-written texts as size decreases, indicating smaller models manage lower-complexity texts better.
For fine-tuned language understanding tasks, text complexity showed minimal impact, with both human-written and simplified text trainings achieving comparable results. However, in zero-shot scenarios, differences emerged: simpler texts augmented performance on tasks focused on linguistic knowledge, while more complex texts favored tasks needing world knowledge and entity tracking.
Implications and Future Directions
These findings imply that data diversity affects model performance variably, depending on whether the task is concerned with linguistic versatility or domain-specific knowledge. For practitioners, this suggests that curation strategies should align with intended applications, where fine-tuned models may overlook surface variation without detriment, while zero-shot configurations might necessitate it. In synthetic data generation, variety must extend beyond mere surface-level differences to encompass topical and knowledge diversity, ensuring comprehensive model understanding across tasks.
Future research should explore multi-dimensional optimization of dataset diversity to harness broader performance benefits, balancing between computational efficiency and performance gains across diverse task spectrums. Further, studies should investigate simplifying large-scale datasets in ways that meticulously preserve semantic content while ensuring computational and dimensional efficiency.
Conclusion
The paper revisits the role of text complexity in LLM pretraining and concludes that surfacing-level complexity has minimal influence on downstream tasks performance, particularly when evaluated through traditional NLP tasks like those in GLUE and SuperGLUE. Simpler text structures benefit smaller models in terms of efficiency and, in zero-shot contexts, may enhance linguistic knowledge tasks, although sophisticated textual data remains crucial for tasks demanding comprehensive world knowledge and sophisticated reasoning. Thus, the study provides new insights into when and how to adjust data complexity relative to model capacity and task requirements.

