- The paper demonstrates that incorporating LLM-generated text simplification enhances fine-tuning and zero-shot performance over repeated exposure.
- It shows that curriculum learning through simple-to-complex ordering benefits smaller models, while interleaved schedules optimize larger models.
- The study underlines that strategic data scheduling can achieve superior representation with limited pretraining data, reducing resource demands.
Beyond Repetition: Text Simplification and Curriculum Learning for Data-Constrained Pretraining
Introduction
The paper "Beyond Repetition: Text Simplification and Curriculum Learning for Data-Constrained Pretraining" (2509.24356) explores LLM pretraining under data-constrained conditions. The authors focus on the effects of curriculum learning through text-complexity ordering and data augmentation via simplification. This investigation hinges on two primary questions: whether simplifying texts enhances representation quality beyond mere repetition of original data, and whether organizing training data by increasing complexity improves model performance. By utilizing a parallel corpus of both human-written and LLM-simplified paragraphs, their study assesses the efficacy of four distinct data schedules: repeated exposure, low-to-high complexity, high-to-low complexity, and an interleaved approach.
Methodology
The paper involves comprehensive experiments using models with 124M and 256M parameters. The models are pretrained on a developed corpus where each human-written paragraph is paired with a simplified variant. The researchers examined four training schedules—BASELINE, INTERLEAVED, SIMP→HW, and HW→SIMP—in order to identify the influence of text complexity ordering and simplified data presence. The training variables such as architecture, optimizer, tokenizer, and training steps were kept consistent across the experiments, ensuring that any observed performance differences are attributed purely to the data scheduling strategies.
Results and Analysis
Simplified Data and Performance: The introduction of simplified data was observed to improve both fine-tuning and zero-shot performance when compared to the baseline of repeated exposure to human-written texts. Notably, smaller models like the 124M parameter configuration benefited from a curriculum that begins with simpler texts, whereas larger models, at 256M parameters, showed enhanced performance with interleaved data schedules.
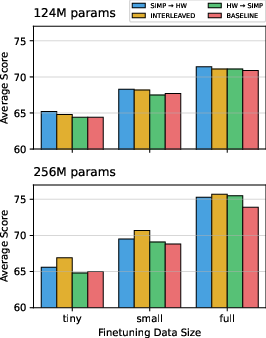
Figure 1: Average score on six language tasks by curriculum and fine-tuning data size.
The findings here emphasize the importance of utilizing LLM-generated simplifications, particularly in scenarios where the pretraining data is limited. The interleaved schedule significantly enhanced sample efficiency for the 256M model, affirming that balanced exposure optimizes learning in a resource-efficient manner.
Curriculum versus Interleaving: The results pointed out that smaller models gain more from a simple-to-complex presentation, a hallmark of curriculum learning, whereas larger models better absorb varied data when exposed to balanced, interleaved schedules. This nuance underscores the potential of tailored training schedules based on model capacity.
Implications and Future Directions
The research has practical implications for the design of pretraining strategies in scenarios where data acquisition is restricted by costs or availability. By leveraging text simplification and strategic data ordering, models can achieve superior representation quality without necessitating expansive datasets. This approach not only aids in mitigating the data limitations but also enriches the model's linguistic and commonsense reasoning capabilities.
The study's conclusion opens avenues for exploring longer-term pretraining strategies and the potential of languages beyond English. Future work can focus on integrating other forms of text rewriting, such as paraphrasing or style transfer, which might complement the benefits observed here. Additionally, larger model configurations and diverse linguistic domains remain unexplored territories.
Conclusion
This paper significantly contributes to the understanding of pretraining in data-constrained settings by affirming that text simplification and curriculum learning offer measurable advantages over conventional repeated data exposure. The insights gained from their four-schedule comparative analysis highlight the scalability of curriculum-based approaches when model size and pretraining resources are carefully matched. Though the observed improvements are indeed modest, they offer a scaffold for optimizing portrayal learning techniques. These findings pave the way for more efficient utilization of existing data, encouraging further innovations in curriculum learning methodologies and broader applicability in multilingual contexts.