- The paper's main contribution is a novel method that uses scene graphs to focus on task-relevant objects and improve robotic compositional generalization.
- It integrates graph neural networks with diffusion-based imitation learning to create robust feature embeddings for atomic skill execution.
- Real-world and simulation experiments show significantly higher success rates compared to state-of-the-art methods for long-horizon manipulation tasks.
Compose by Focus: Scene Graph-based Atomic Skills
The paper, "Compose by Focus: Scene Graph-based Atomic Skills," introduces a novel approach for robotic skill composition by leveraging scene graph-based representations to address compositional generalization in visuomotor policies. This method integrates graph neural networks (GNNs) with diffusion-based imitation learning, aiming to improve the robustness and compositional generalization of robots executing long-horizon manipulation tasks.
Introduction
Compositional generalization is integral for enabling robots to solve complex tasks by efficiently combining atomic skills. Previous work has focused on synthesizing high-level planners that sequence pre-learned skills, yet the execution of individual skills often falters due to distribution shifts caused by varied scene compositions. The paper introduces scene graphs that concentrate on task-relevant objects, thus reducing sensitivity to irrelevant variations. These graphs serve as interpretable and structured inputs for skill learning, integrating with a vision-LLM (VLM)-based planner.
Real-world experiments demonstrate that using scene graphs achieves significantly higher success rates than leading models, such as Diffusion Policy and π0, validating the approach's robustness in both simulated and real-world settings.

Figure 1: Real world vegetable picking. A policy trained to pick up a single vegetable on a clean table is evaluated by placing all vegetables into the basket in a cluttered scenario.
Methodology
Scene Graph Construction
The paper proposes constructing 3D semantic scene graphs from RGB and depth data obtained during expert demonstrations. Grounded SAM segments task-relevant objects from images, and objects are encoded using lightweight MLP networks and vision-LLMs (VLMs), such as ChatGPT, identify inter-object relations.
Visual input is transformed into scene graphs where nodes encode 3D geometry and semantic features, while edges capture dynamic relations. This structured representation facilitates robust skills composition, focusing computation on essential parts of the scene graph.
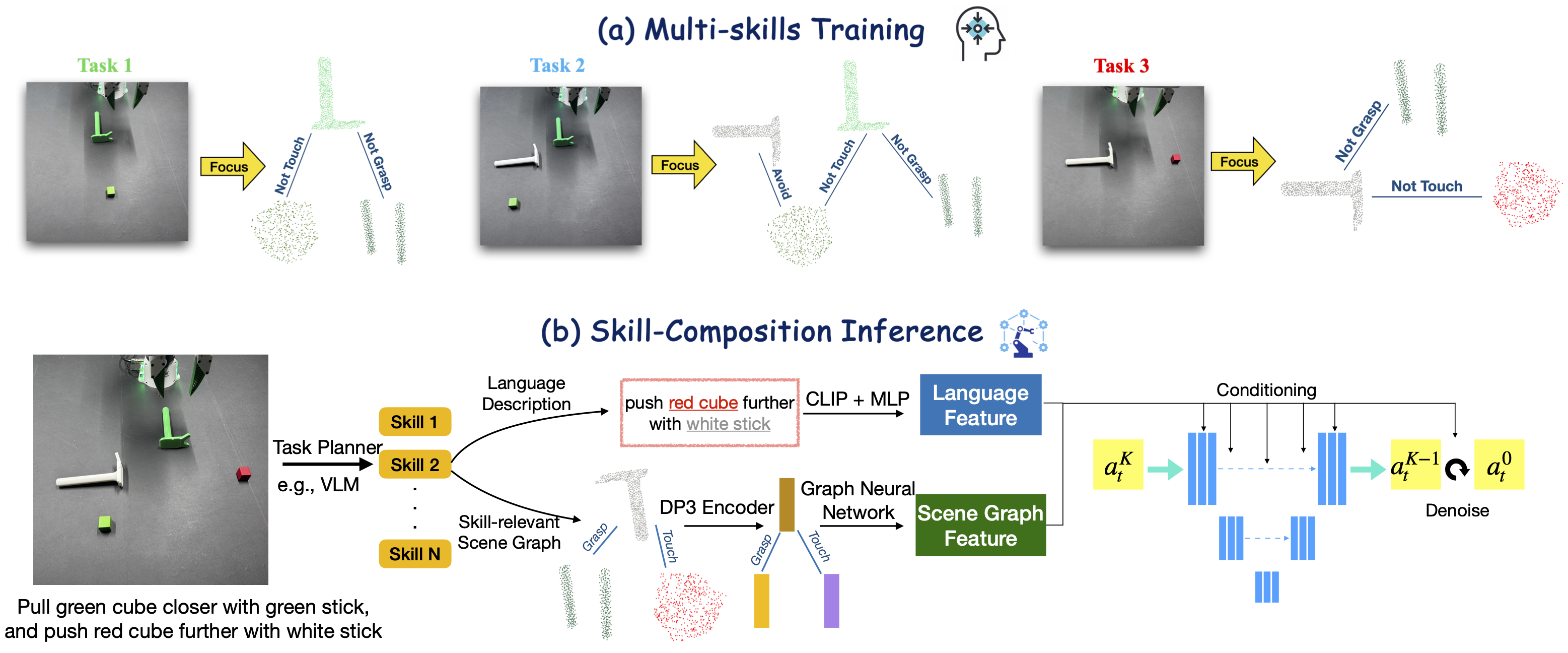
Figure 2: Compose by focus. (a) A single policy is trained on focused scene graphs across all sub-skills. (b) During inference, a task planner (e.g., VLM) decomposes a long-horizon task into N sub-skills. For each sub-skill, CLIP encodes the description, Grounded SAM segments the relevant objects and extracts point clouds as graph nodes, and edges represent inter-object relations.
Multi-skill Policy Training
Implementing a Graph Attention Network (GAT), the paper constructs feature embeddings from nodes, enabling robust policy training focused on relevant sub-scene graphs. The policy utilizes diffusion models, conditioned on graph features and skill descriptions, applying denoising methods to transform Gaussian noise into actionable tasks.
Such policy schemes ensure efficient learning and execution of atomic skills, endowing systems with adaptability to diverse environmental conditions.
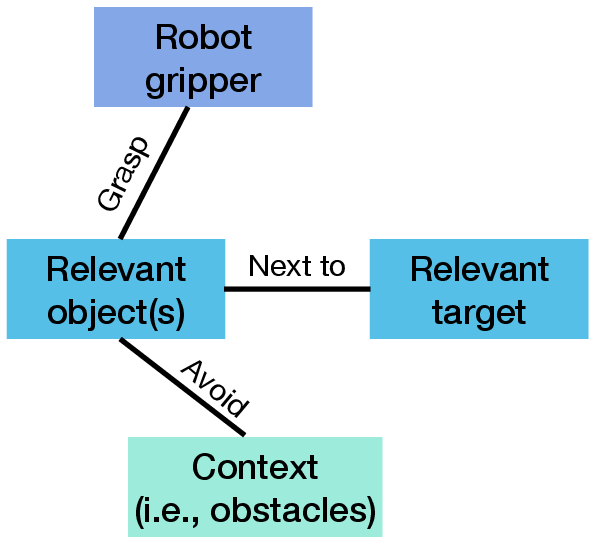
Figure 3: Illustration of a scene graph.
Simulation and Real-world Experiments
Extensive simulation tasks were devised to test the approach using the ManiSkill2 platform. Evaluation indicated that scene graph-based methods vastly outperformed raw 2D and 3D visual input methods in skill composition tasks, demonstrating strong resilience to distribution shifts. The need for structured data representation was reaffirmed through ablations showing failures in 2D-only and concatenated point cloud approaches.
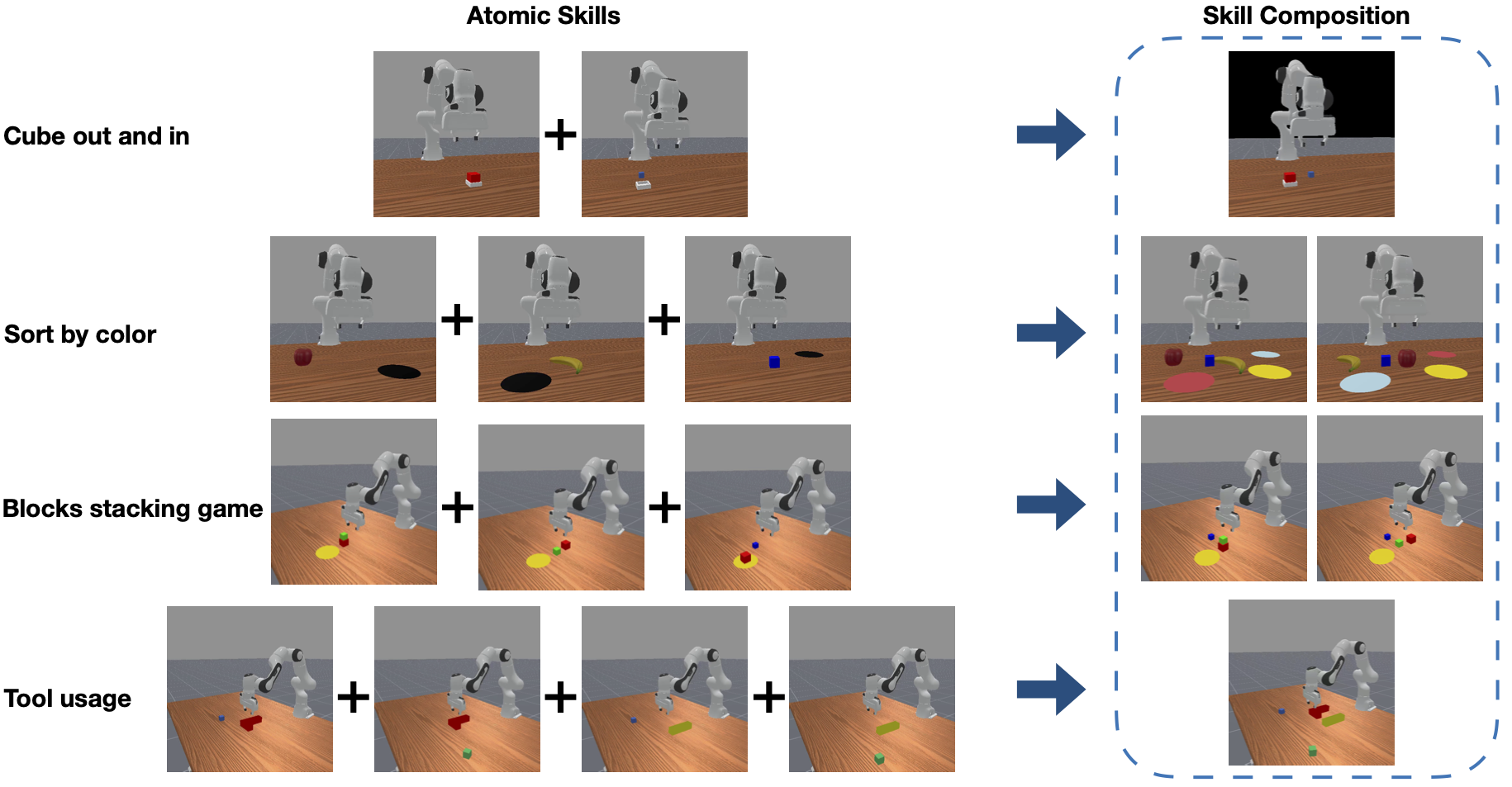
Figure 4: Simulation tasks. [Left] Visualization of atomic skills in each task, which is the training data. [Right] Evaluation scenarios, involving multiple objects to be operated with possibly changed background.
In real-world trials, the approach effectively combined skills (e.g., tool usage and vegetable harvesting) with high success rates, showcasing its applicability and efficiency.
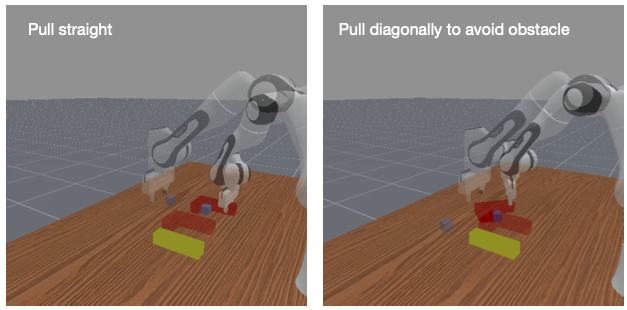
Figure 5: Obstacle avoidance. The sub-scene graph includes the robot gripper, relevant objects, and an obstacle node (yellow stick), enabling the policy to learn trajectories that depend on the cubeâobstacle relation.
Implications and Future Directions
This research significantly enhances compositional generalization in robotics, offering a robust framework for synthesizing skills adaptable to real-world environments. By exploiting structured scene graphs, the approach reduces the computational burden and improves reaction to scene perturbations and distractors.
Future developments could refine visual processing accuracy, streamline graph construction, and broaden applicability to varied disciplines beyond manipulation tasks. Advancements in VLMs and foundation models promise to further enhance integration of scene graphs with adaptive learning strategies.
Conclusion
The scene graph-based approach for skill composition in robots addresses longstanding challenges in visuomotor policy robustness and generalization. By leveraging structured representations and cutting-edge diffusion-based imitation learning, this framework sets a benchmark for future research in effective skill synthesis, marking a pivotal step forward in enabling autonomous robots to deftly handle complex, cluttered, and dynamically shifting environments.
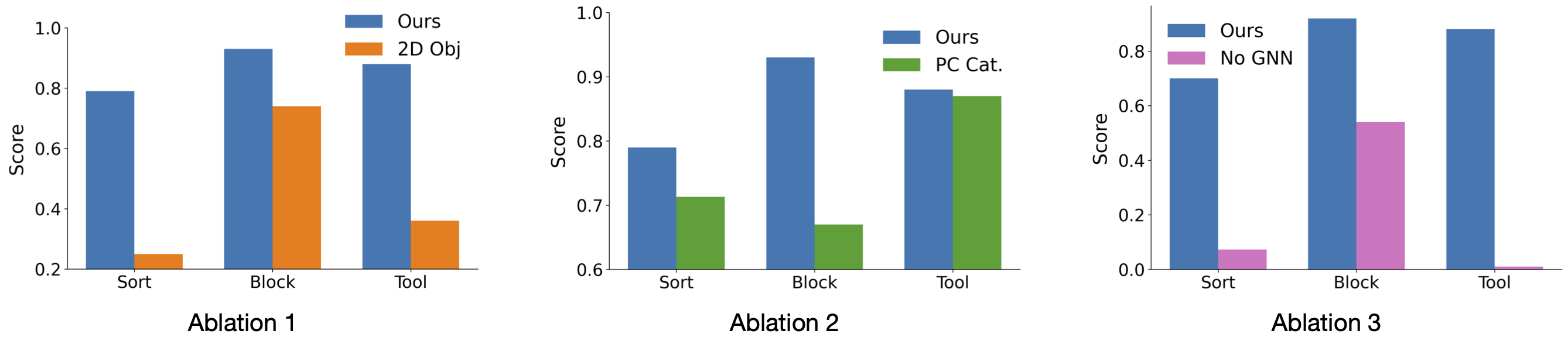
Figure 6: Ablation studies highlighting the importance of 3D scene graph representations for skill composition.