- The paper introduces a toy-play training strategy that uses a limited set of geometric primitives to achieve zero-shot grasp generalization.
- It employs the LEGO architecture with an object-centric DetPool mechanism, leading to a 67% success rate across 64 YCB objects.
- The approach proves data-efficient and scalable, outperforming larger models while transferring across different robotic embodiments.
Generalizable Robotic Grasping via Compositional Toy Play
Introduction and Motivation
The paper "Learning to Grasp Anything by Playing with Random Toys" (2510.12866) addresses the persistent challenge of generalization in robotic manipulation. While recent advances in robotic policies have enabled impressive performance on in-domain tasks, these systems typically exhibit poor transfer to novel, out-of-distribution (OOD) objects. Drawing inspiration from developmental psychology, which suggests that infants acquire generalizable manipulation skills by interacting with a small set of simple toys, the authors propose a compositional approach: training robots exclusively on objects constructed from a limited set of geometric primitives, then evaluating zero-shot transfer to real-world objects.
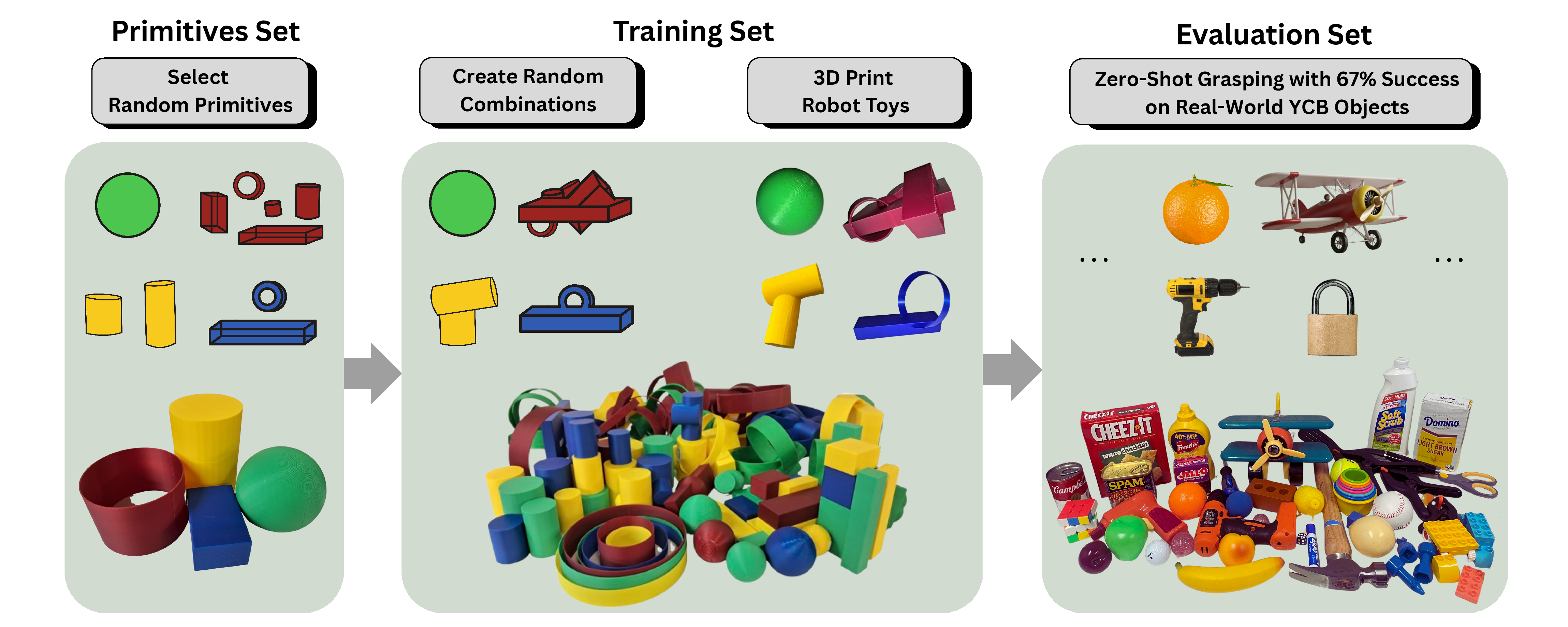
Figure 1: The grasping policy is trained solely on random compositions of four basic primitives and achieves 67% zero-shot success on 64 YCB objects.
CÉZANNE Toy Dataset: Compositional Object Generation
The core of the methodology is the construction of a synthetic dataset of "Cézanne toys," each generated by randomly assembling 1–5 instances of four shape primitives: spheres, cuboids, cylinders, and rings. The primitives' dimensions and colors are randomized, and their spatial arrangement ensures physical connectivity and compositional diversity.

Figure 2: Example Cézanne toys, each a random composition of 1–5 primitives with randomized dimensions and colors.
This compositional dataset is both OOD with respect to real-world objects and structurally rich, providing a principled testbed for evaluating generalization. The dataset is instantiated both in simulation (ManiSkill) and physically via 3D printing, enabling data collection across both domains.
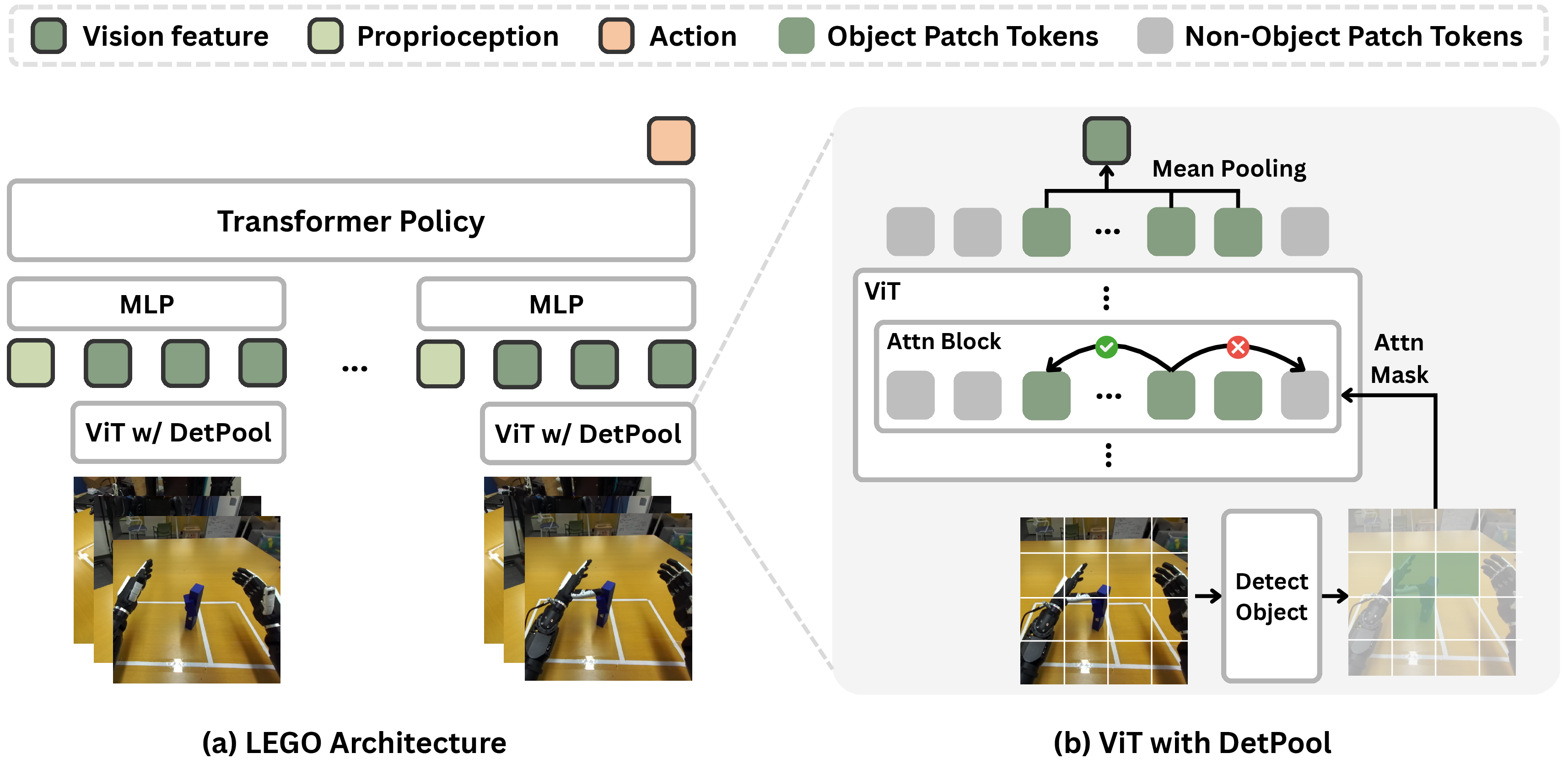
LEGO: Object-Centric Policy Architecture
The proposed policy architecture, LEGO (LEarning to Grasp from tOys), is designed to maximize generalization by enforcing object-centricity in the visual representation. The architecture consists of:
The policy is trained via behavior cloning with an ℓ1 loss on action sequences, using only demonstration data collected on Cézanne toys.
Experimental Evaluation
Zero-Shot Generalization
The primary evaluation is zero-shot grasping on the YCB object set, both in simulation and on real hardware (Franka Emika Panda with Robotiq gripper, and Unitree H1-2 humanoid with Inspire dexterous hands). The policy is trained exclusively on Cézanne toys and never exposed to real objects during training.
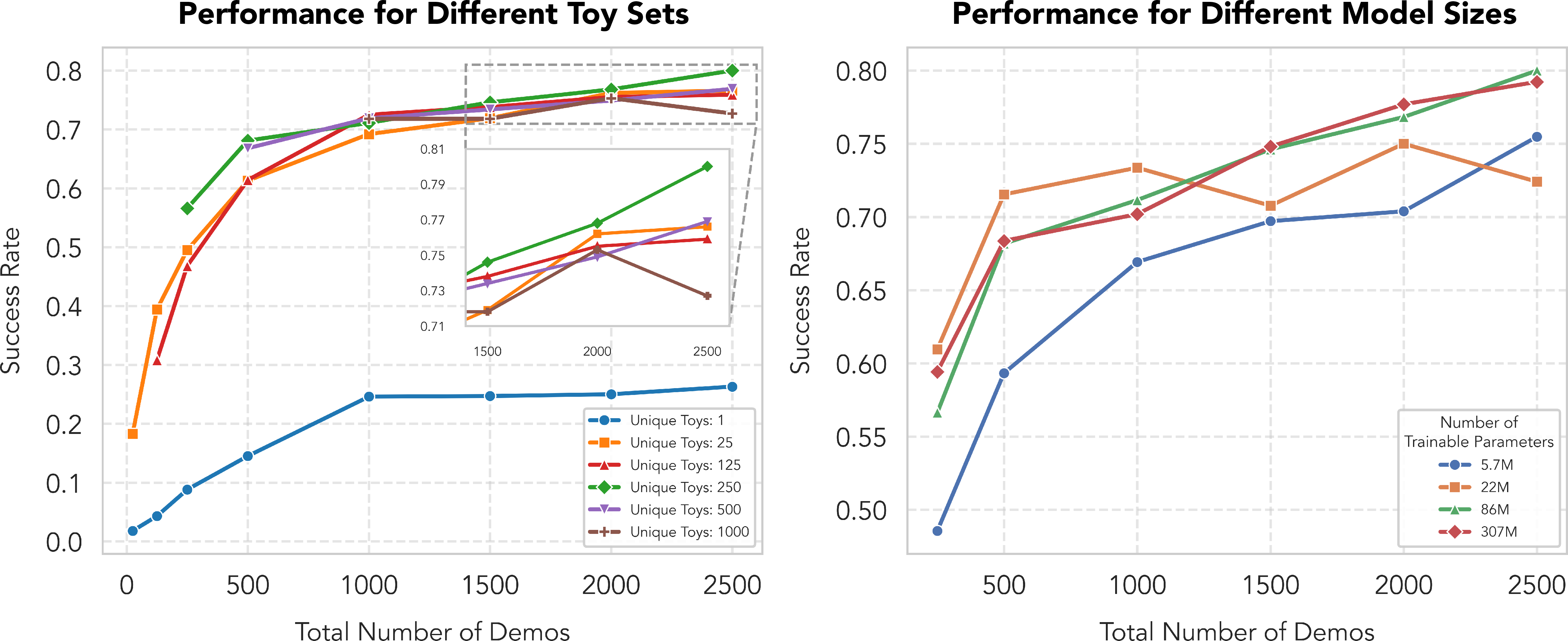
Scaling Laws and Ablations
The authors conduct extensive scaling studies:
Hardware and Data Collection
The approach is validated on two distinct robotic platforms, with detailed hardware configurations and teleoperation-based demonstration collection. The policy is robust to embodiment changes, requiring only proprioceptive adaptation.
Figure 6: Franka Emika Panda with Robotiq Gripper.

Figure 7: H1-2 Humanoid with Inspire Dexterous Hands.
Analysis and Implications
Object-Centricity as the Key to Generalization
Ablations demonstrate that DetPool is essential: replacing it with standard mean, attention, or CLS pooling degrades zero-shot performance by 22–48%. The object-centric representation induced by DetPool enables the policy to ignore background and context, focusing exclusively on the target object. This is consistent with findings in cognitive science and object-centric vision literature, and contrasts with prior approaches that rely on large-scale pretraining or heavy data augmentation.
Data Efficiency and Model Simplicity
The results challenge the prevailing assumption that large-scale, in-domain data and massive models are prerequisites for generalization in robotic manipulation. The LEGO policy, with only 86M parameters and a few hours of demonstration data, matches or exceeds the performance of models orders of magnitude larger and more data-hungry.
Practical and Theoretical Implications
- Practical: The approach enables scalable, data-efficient training of generalist grasping policies, reducing the need for costly real-world data collection and annotation. The compositional toy dataset is easy to generate and physically instantiate.
- Theoretical: The findings support the hypothesis that compositionality and object-centricity are sufficient for generalization in manipulation, echoing theories of human cognitive development and compositional representation learning.
- Limitations: The method's generalization may degrade for objects with physical properties not represented in the toy set (e.g., deformable, articulated, or highly textured objects). The current focus is on single-step grasping; extension to long-horizon, multi-step tasks remains open.
Future Directions
Potential avenues for future research include:
- Extending the compositional approach to more complex manipulation tasks (e.g., tool use, assembly, deformable object handling).
- Incorporating additional primitive types or physical properties (e.g., mass, compliance) to further enhance generalization.
- Exploring more efficient architectures for deployment on resource-constrained hardware.
- Investigating the integration of language or multimodal conditioning for task specification.
Conclusion
This work demonstrates that robust, general-purpose robotic grasping can be achieved by training on a small set of compositional, primitive-based toys, provided that the policy architecture enforces object-centricity via detection pooling. The approach achieves strong zero-shot transfer to real-world objects and diverse robotic embodiments, outperforming state-of-the-art models that rely on large-scale pretraining. These results suggest a scalable and theoretically grounded path toward generalizable robotic manipulation, with significant implications for both research and practical deployment.