- The paper proposes bias-only fine-tuning by updating only select bias terms, significantly reducing parameters while maintaining performance.
- It leverages both angular and magnitude changes to dynamically select the optimal bias term, outperforming traditional magnitude-based approaches.
- Evaluations on GLUE, SuperGLUE, and autoregressive models demonstrate that BEFT yields robust adaptation and improved resource efficiency across diverse architectures.
BEFT: Bias-Efficient Fine-Tuning of LLMs
The paper "BEFT: Bias-Efficient Fine-Tuning of LLMs" addresses the challenge of fine-tuning LLMs efficiently by focusing on bias terms exclusively, aiming to reduce computational overhead and resource consumption. Traditionally, parameter-efficient fine-tuning (PEFT) methods have explored various strategies to update only a subset of parameters in LLMs, but this paper proposes a novel approach that leverages the efficiency and practicality of bias-only fine-tuning.
Introduction to Bias-Efficient Fine-Tuning
Bias-efficient fine-tuning offers a practical solution by updating only the bias terms in LLMs, which drastically reduces the number of trainable parameters. The approach is particularly beneficial in low-data regimes, where it competes with full-parameter fine-tuning despite updating significantly fewer parameters. The paper identifies the link between fine-tuning specific bias terms (such as those in query, key, or value projections) and downstream performance as an area needing clarity. Existing methods that rely on the magnitude of bias change or empirical Fisher information fall short in guiding the selection of which bias term to fine-tune effectively.
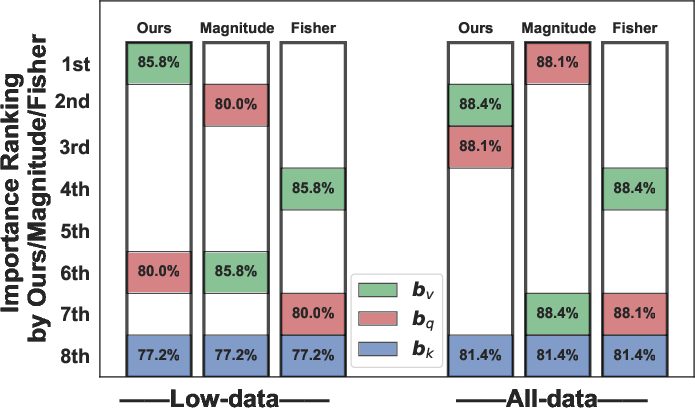
Figure 1: Importance ranking and accuracy (\%) of fine-tuning different bias terms (query, key, value) on the SST-2 dataset using various bias-selection approaches.
Proposed Approach: Angular and Magnitude Considerations
The authors propose a bias-efficient approach that selects the bias term for fine-tuning by considering both the angular change and the magnitude of bias change before and after fine-tuning. This method evaluates the projection ratios, providing a dynamic measure that surpasses traditional approaches like the Magnitude and Fisher methods.
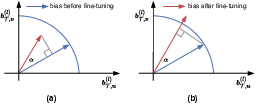
Figure 2: Our bias-efficient approach jointly considers both the angular change and magnitude change, to measure the projection ratio.
Comparison and Evaluation
The paper's approach is evaluated against existing methods on various LLM architectures with sizes ranging from 110M to 6.7B parameters. The extensive evaluation on GLUE and SuperGLUE benchmarks, as well as autoregressive models like OPT-1.3B and OPT-6.7B, demonstrates the effectiveness of the bias-efficient approach across classification, multiple-choice, and generation tasks.
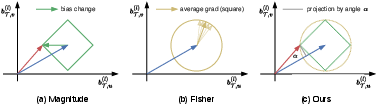
Figure 3: Approaches to select different bias terms for fine-tuning.
Efficiency and Effectiveness
The proposed BEFT method is shown to be highly efficient. It dramatically reduces the percentage of trainable parameters and runtime while maintaining a competitive adaptation performance. Fine-tuning only the targeted bias term consistently delivers better downstream performance than tuning all bias terms or all parameters, highlighting the potential of fine-tuning individual bias terms.
Generalizability to Diverse Models
The findings indicate that the insights gained from the selection of bias terms generalize across different datasets and model architectures. Importantly, fine-tuning the selected bias term (typically the value bias term) yields superior performance compared to others, regardless of the LLM type or its size.
Conclusion
The paper concludes that bias-only fine-tuning provides a robust, efficient strategy for adapting LLMs, especially in scenarios with limited data. The proposed approach not only improves the accuracy of selecting which bias terms to fine-tune but also enhances the overall parameter efficiency of LLM adaptation strategies.
The evaluation supports BEFT's promise as a competitive alternative to mainstream PEFT techniques across various architectures and tasks, establishing a basis for further exploration into bias-driven fine-tuning methodologies.
In summary, BEFT represents a step forward in bias-focused adaptation of LLMs, challenging traditional norms and paving the way for more resource-effective AI applications.

