VCBench: Benchmarking LLMs in Venture Capital
Abstract: Benchmarks such as SWE-bench and ARC-AGI demonstrate how shared datasets accelerate progress toward artificial general intelligence (AGI). We introduce VCBench, the first benchmark for predicting founder success in venture capital (VC), a domain where signals are sparse, outcomes are uncertain, and even top investors perform modestly. At inception, the market index achieves a precision of 1.9%. Y Combinator outperforms the index by a factor of 1.7x, while tier-1 firms are 2.9x better. VCBench provides 9,000 anonymized founder profiles, standardized to preserve predictive features while resisting identity leakage, with adversarial tests showing more than 90% reduction in re-identification risk. We evaluate nine state-of-the-art LLMs. DeepSeek-V3 delivers over six times the baseline precision, GPT-4o achieves the highest F0.5, and most models surpass human benchmarks. Designed as a public and evolving resource available at vcbench.com, VCBench establishes a community-driven standard for reproducible and privacy-preserving evaluation of AGI in early-stage venture forecasting.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces VCBench, a shared test (called a benchmark) that checks how well AI LLMs can predict which startup founders will become very successful. Venture capital (VC) is a good real-world challenge because success is rare, information is messy, and even top human investors don’t get it right very often. VCBench includes 9,000 carefully cleaned and anonymized founder “profiles” so different AIs—and humans—can be compared fairly without risking anyone’s privacy.
The main questions the paper asks
- Can we build a fair, privacy-safe benchmark to test how well AIs predict startup success from founder histories?
- Can we clean and standardize real-world data (like LinkedIn and Crunchbase) so models don’t get confused by messy entries?
- Can we prevent “cheating,” where an AI simply recognizes a founder from the internet instead of truly reasoning?
- How do today’s leading AIs compare to human-level investing performance in this task?
- Can the community use this benchmark (and its leaderboard) to improve AI decision-making over time?
How they did it (in simple terms)
Think of each founder profile like a detailed, anonymized “resume card.” The team built VCBench in four steps:
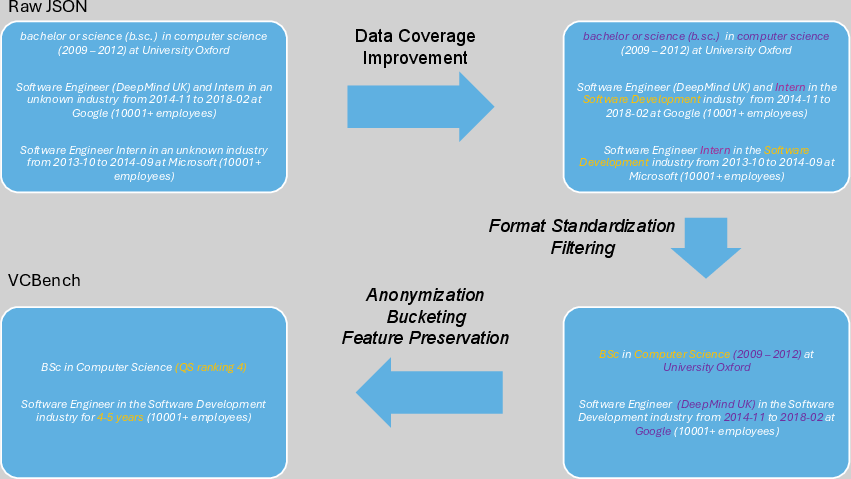
- Improve coverage: They matched and filled in missing facts using multiple sources (like checking another database if one field is empty).
- Standardize formats: They cleaned up messy text—like turning “p.h.d.”, “PhD”, and “Doctor of Philosophy” into the same degree label—so the data means the same thing everywhere. They also filtered out “noisy” entries (like short courses or internships) that can confuse models.
- Anonymize (protect privacy): They removed names, company names, locations, and exact dates. They also grouped rare details into buckets (for example, turning exact job lengths into ranges like “2–3 years”) and clustered industries into 61 larger groups. This makes it much harder to identify a person while keeping the useful patterns.
- Test against “attackers”: They ran adversarial tests where powerful AIs tried to guess who a founder was. If the attackers succeeded too often, the team adjusted the data to make it safer, then tested again.
To measure prediction performance, they used:
- Precision: Of the founders the model says will succeed, how many actually do? (Being careful when saying “yes.”)
- Recall: Of all the founders who actually succeed, how many did the model find? (Catching as many real winners as possible.)
- F0.5 score: A combined score that cares more about precision than recall. This matches VC reality: false alarms (bad bets) are costly.
They split the 9,000 profiles into six parts (called folds) to test models fairly and averaged the results.
What counts as “success”? A founder is labeled successful if their company had a big exit or IPO (over $500M) or raised over$500M. If a company raised $100K–$4M early on but didn’t hit a big milestone within 8 years, it’s labeled unsuccessful.
What they found and why it matters
- Strong privacy protection with useful signal: Their anonymization cut identity re-matching by about 92% (offline tests) and about 80% (online with web search), while keeping enough information for prediction.
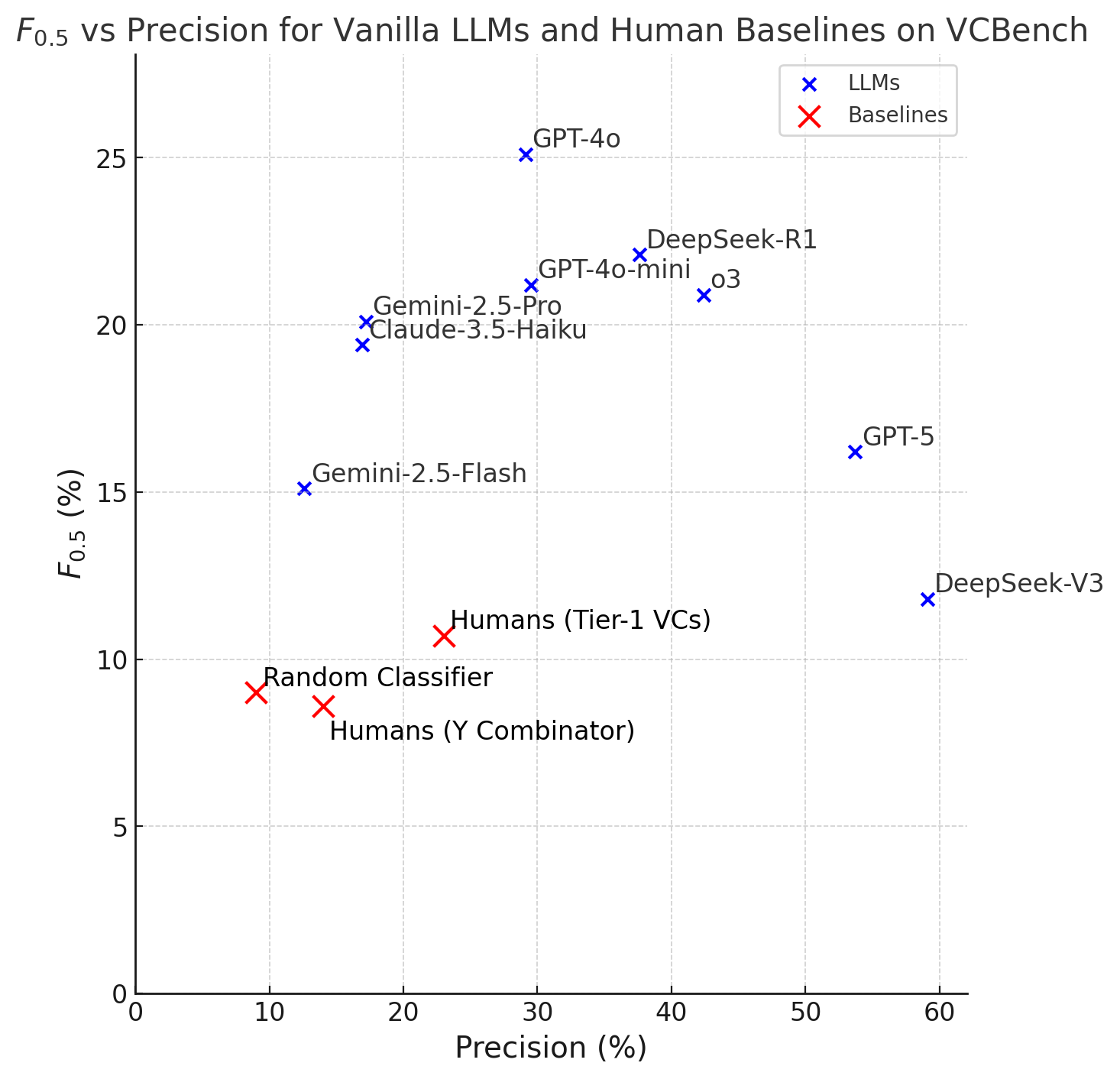
- Real performance gains: Several top AI models beat human baselines.
- GPT-4o got the best overall F0.5 score (25.1), meaning it stayed relatively cautious while still finding real winners.
- DeepSeek-V3 achieved very high precision (it was right most of the times it said “this founder will succeed”), over 6× the market baseline precision, but it missed many winners (low recall).
- Gemini-2.5-Flash found many winners (high recall) but with lower precision.
- Fairness checks: They investigated a suspiciously good result in one data split and confirmed it wasn’t due to identity leaks—just a tough subset with more extreme outcomes.
- Public but safe: To avoid future AI models “memorizing” the whole dataset during training, they only released half publicly. The other half is used privately for the leaderboard to keep scoring honest.
Why this matters: This is one of the first benchmarks that tests AI decision-making in a high-stakes, uncertain, real-world setting—not just solving math problems or answering trivia. It shows that anonymized founder histories alone can be surprisingly predictive and that AIs can match or beat some human-level standards.
What this could mean going forward
- Better decision tools: If AIs can reliably spot patterns linked to success, investors could use them as assistants to filter opportunities and reduce bias.
- Safer data sharing: The paper shows a practical way to share useful, real-world data while protecting people’s identities.
- A living community testbed: With a public leaderboard and evolving dataset, researchers can keep improving methods and compare fairly over time.
- Caution still needed: The benchmark’s success rate (9%) is higher than the real world (about 1.9%). That makes testing easier, but it also means results won’t translate perfectly to live investing. The data also inherits some bias from public sources and has time-related limitations (some companies haven’t had enough years to show outcomes).
In short: VCBench is like a fair, privacy-safe “tournament” for AIs (and humans) to predict which founders will build big successes. It proves that careful data cleaning and anonymization can keep both privacy and predictive power—and it sets the stage for better, more realistic tests of AI judgment in the future.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to guide future research efforts.
- Success labeling robustness: No sensitivity analysis on the $500M$ exit/IPO/funding threshold; test alternative thresholds (e.g., $100M$, $250M$, $1B$) and alternate success definitions (e.g., profitability, sustained revenue growth, category leadership).
- Right-censoring correction: The eight-year horizon induces label noise; implement time-to-event models (e.g., Cox PH, Aalen) or inverse-probability censoring weights to adjust success rates by founding year and outcome latency.
- Founders with multiple ventures: The benchmark pairs each founder to their most recent company; quantify how this choice affects labels and performance versus (i) first venture, (ii) best-known venture, or (iii) all ventures with multi-instance labels.
- Team-level effects: Current features are founder-centric; add co-founder team composition, prior collaboration networks, and role complementarities to measure incremental predictive value and fairness impacts.
- Company-level context: Omitted early company signals (product, market size, traction, patents) leave construct validity open; evaluate how minimal, anonymized company proxies (e.g., market maturity indices, patent counts, sector macro tailwinds) change predictive accuracy and privacy risk.
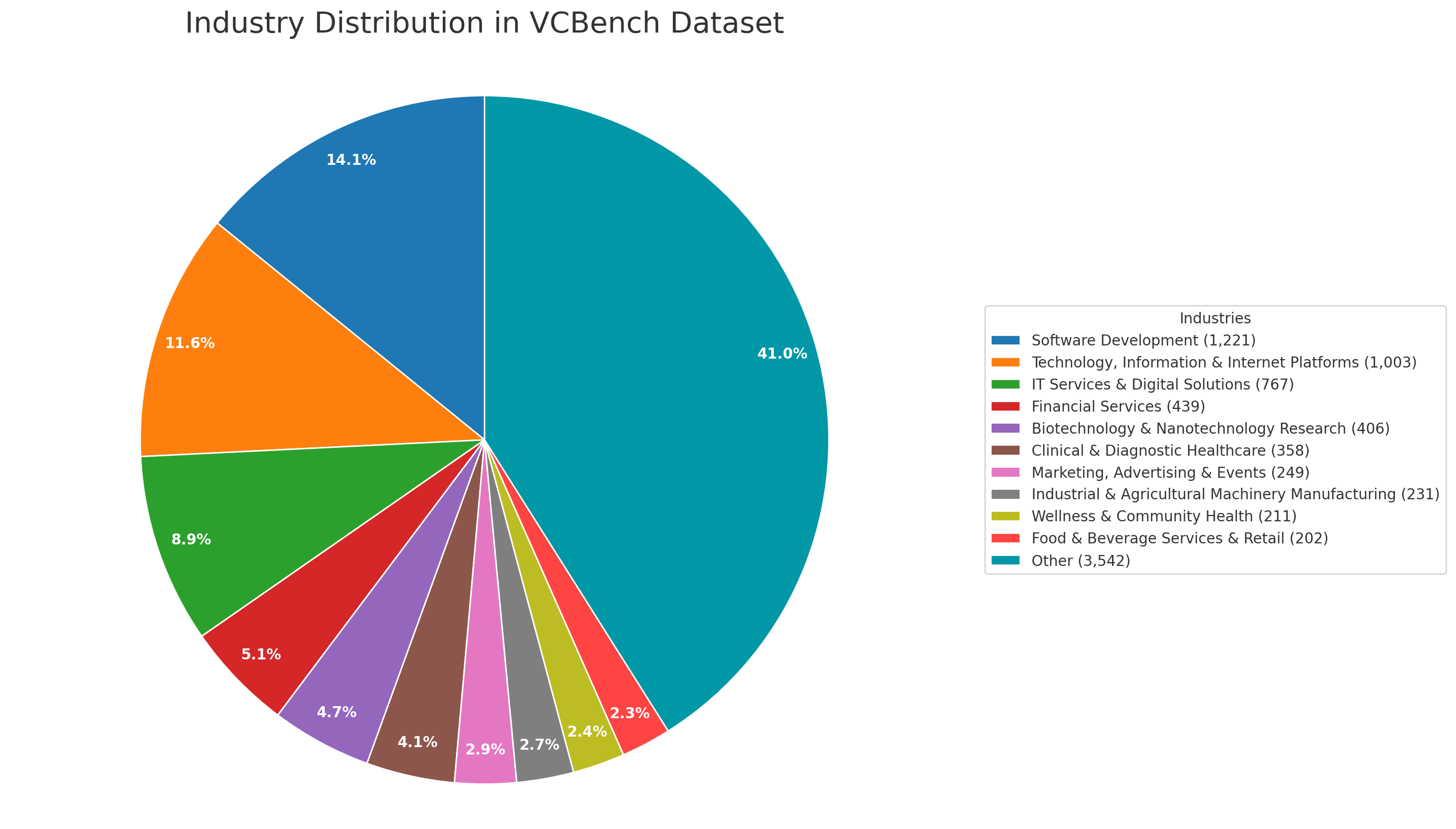
- Geographic and sector generalizability: Data is predominantly U.S. and tech-centric (2010–2018); test out-of-domain generalization across geographies, sectors (e.g., non-tech, deeptech, climate), and later vintages (post-2018).
- Sampling bias quantification: The LinkedIn/Crunchbase-centric sampling introduces visibility and sector skew; measure missingness and representativeness versus independent registries (e.g., business registries, SEC Edgar, PitchBook subsets) and document selection bias effects on performance.
- Label completeness: Many acquisition/IPO valuations are undisclosed or noisy; estimate label reliability and perform label-audits (e.g., manual validation samples, probabilistic labels) and quantify outcome misclassification rates.
- Prevalence shift handling: While caution is noted (9% vs 1.9%), there is no method to recalibrate predictions; provide prevalence-adjusted thresholds, post-hoc calibration (Platt scaling, isotonic), and decision policies for low-prevalence deployment.
- Evaluation metrics breadth: Only is reported; add AUPRC, calibration (Brier score, reliability curves), decision-theoretic metrics (utility-weighted gains, cost-sensitive loss), and ranking metrics (NDCG) to capture portfolio allocation trade-offs.
- Statistical significance: No confidence intervals or hypothesis tests for model comparisons; use bootstrap or stratified resampling to provide uncertainty (CIs) and significance of differences across folds and models.
- Prompting and inference settings: Predictive prompts, sampling parameters, and run-time constraints are unspecified; release full prompt templates, temperature/top-p settings, context lengths, and random seeds to ensure reproducibility.
- Web access policy in prediction: The predictive evaluation policy re: web search/grounding is unclear; standardize offline vs online modes and report their impact on performance and leakage.
- Cross-fold anomalies: Fold-specific variation is high and only one fold underwent deeper leakage checks; conduct systematic fold-by-fold leakage audits and variance analyses across all folds.
- Token and compute normalization: Cost per 1M tokens is reported but not actual tokens used per profile; standardize and disclose tokens/profile, max reasoning steps, and compute budgets to enable fair efficiency comparisons.
- Pre/post-anonymization performance gap: The paper does not quantify predictive performance degradation due to anonymization; measure models on pre-anonymized vs anonymized profiles (in a secure enclave or synthetic proxy) to estimate the trade-off.
- Formal privacy guarantees: Anonymization relies on empirical tests; evaluate k-anonymity, l-diversity, t-closeness, and differential privacy baselines (even if critiqued) to provide quantifiable privacy risk bounds.
- Adversary coverage: Re-identification tests use two models and 300 successful founders; expand to more adversaries (including human red-teamers and specialized deanonymization algorithms), larger samples, and continuous updates as models improve.
- QS ranking effects: QS rankings unexpectedly reduce identification; study robustness to updated QS lists over time, potential fairness impacts on non-ranked/regional institutions, and whether this effect persists for future LLMs.
- Industry clustering validity: Provide objective cluster quality metrics (e.g., silhouette, Davies–Bouldin), reproducibility across seeds/embeddings, and privacy-utility trade-offs for 61-industry clusters.
- High-cardinality field anonymization: Current clustering works for industries but not roles or fields of study; develop scalable anonymization/clustering for job titles and education fields and evaluate privacy/utility impact.
- Entity resolution and coverage: “Direct match apparent” cross-source matching is under-specified; document entity resolution algorithms, error rates, and coverage gains with quantitative missingness reduction.
- LLM-assisted cleaning accuracy: No audit of LLM-based reformatting/tagging; measure precision/recall for exclusion categories (e.g., “Intern”, “Course”), inter-annotator agreement vs humans, and downstream impacts on model performance.
- Duplicate founders/companies: Deduplication handling is unclear; audit for duplicates (e.g., multiple founders from the same company, repeated careers) and quantify effects on leakage and performance.
- Removal of identifiable founders: Founders identified ≥2 times were removed; quantify how removals alter the success distribution, sector mix, and generalizability, and provide a principled removal policy.
- Fairness and subgroup performance: No fairness analysis by demographic proxies (gender, race, region), institution tier, or industry; add subgroup performance, disparity metrics, and bias mitigation studies compatible with anonymization.
- Human baseline comparability: The scaling-based normalization assumes identical opportunity distributions; run controlled human evaluations on the anonymized task (without identity cues) to establish a directly comparable baseline.
- Portfolio and sequential decision simulation: The proposed simulation mode is future work; design and report a standardized tournament with budgets, follow-ons, dilution, and IRR/MOIC metrics to connect predictions to investable outcomes.
- External validity to market cycles: Models were tested within a specific period; evaluate robustness under macro shifts (e.g., 2010–2012 vs 2016–2018 vs post-2020) and stress-test against regime changes.
- Data licensing and ethics: Data source licensing, ToS compliance, and ethical review are not detailed; document legal compliance, IRB/ethics approvals, and user consent considerations for public release.
- Public/private split integrity: Releasing 50% publicly reduces leakage risk but not eliminates it; formalize rotating private test sets, canary entries, and periodic refreshes to monitor/prevent benchmark contamination.
- Open-source pipeline availability: The full transformation/anonymization code and versioning are not described; release code, configurations, and hashes for reproducible builds and community audits.
- Causal validity: Features (e.g., prestige) may encode spurious correlations; apply causal analysis (e.g., causal forests, sensitivity to unobserved confounders) to distinguish predictive heuristics from causal drivers.
- Integration of additional modalities: Text-only profiles omit signals available in images, code repos, or patents; explore privacy-preserving multi-modal features and measure incremental gains vs leakage risk.
Glossary
- Ablation: Systematically removing or modifying parts of a system or input to assess their impact on performance. "Ablation formats."
- Adversary class: A category of attacker with defined capabilities used to assess privacy/anonymization robustness. "We consider three adversary classes by increasing identification capability: general-purpose LLMs (e.g., GPT-4o), reasoning models (e.g., o3), and tool-assisted models with web search."
- Adversarial re-identification: Attempts to infer identities from anonymized data using strong models or methods. "we conduct adversarial re-identification experiments, which reduce identifiable founders by 92% while preserving predictive features."
- Agglomerative hierarchical clustering: A bottom-up clustering algorithm that iteratively merges clusters based on a similarity metric. "Apply agglomerative hierarchical clustering with cosine similarity."
- Anonymization unit test: A targeted test designed to measure whether anonymized data still allows identity inference. "We designed anonymization unit tests in which models are explicitly instructed to re-identify founders rather than predict success."
- Bucketing: Grouping continuous or high-cardinality values into discrete intervals to reduce identifiability. "QS (bucketed)"
- Cosine similarity: A similarity metric based on the cosine of the angle between two vectors, often used on embeddings. "Apply agglomerative hierarchical clustering with cosine similarity."
- Data contamination: Unintended presence of benchmark or evaluation data in a model’s training set, biasing results. "data contamination, where LLMs can re-identify founders from profile text and bypass the intended prediction task."
- Dataset-level anonymization: Privacy techniques applied across the dataset to prevent linkage via rare attribute combinations. "Dataset-level anonymization."
- Deal flow: The stream of investment opportunities reviewed by venture capital investors. "VCs self-select their deal flow, and access is constrained by competition, reputation, and human bandwidth."
- Deterministic canonicalization: Rule-based normalization that maps varied strings to a single standard form. "Deterministic canonicalization: Trim whitespace, normalize conjunctions (
and'',{paper_content}'', ``/''), punctuation, and common aliases for degrees and roles." - Duration buckets: Discrete time ranges used to represent periods (e.g., job tenure) while hiding exact dates. "Job start and end dates are converted into duration buckets, expressed in years, which preserve career trajectory information while concealing exact timelines."
- Exit (VC): A liquidity event for a company, typically an acquisition or IPO, that returns capital to investors. "did not achieve an exit, IPO, or substantial follow-on funding within eight years of founding"
- F_{0.5}: A weighted F-score that emphasizes precision over recall (beta=0.5). "Performance is measured using the score, which weights precision twice as heavily as recall:"
- Grounding: The use of external tools or web search to connect model outputs to factual sources. "Gemini-2.5-Pro with grounding (web-search, online)."
- High-cardinality fields: Attributes with many distinct values that can increase re-identification risk. "high-cardinality fields like job roles or education."
- Identity leakage: Disclosure of true identities from anonymized data via direct or indirect cues. "designed to evaluate models fairly against human expertise while preventing identity leakage."
- Label drift: Inconsistency of labels for the same entity over time or across records. "Cross-record consistency. We enforce consistent values for the same entity across profiles (e.g., the industry label attached to the same organization) to reduce label drift."
- Label fragmentation: Proliferation of near-duplicate labels that dilute signal and hinder modeling. "Overall, this stage reduces label fragmentation and consolidates noisy vocabularies while preserving predictive structure"
- Precision--recall frontier: The trade-off curve capturing how gains in precision typically reduce recall, and vice versa. "DeepSeek and Gemini models highlight different points on the precision--recall frontier"
- Pre-training corpus: The large dataset used to train a foundation model before any task-specific fine-tuning. "leakage into the pre-training corpus of future LLMs"
- Prevalence shift: A change in the base rate of positives between evaluation and real-world settings. "Prevalence shift."
- QS university rankings: A global ranking system for universities used as a proxy for educational prestige. "Education prestige is preserved using QS university rankings"
- Reasoning model: An LLM variant optimized for multi-step logical inference, often distinct from general chat models. "reasoning models (e.g., o3)"
- Re-identification: Mapping anonymized records back to real-world identities. "more than 90\% reduction in re-identification risk"
- Right-censoring: Bias introduced when outcomes after a cutoff time are unobserved in time-to-event data. "The eight-year horizon used to define success introduces a right-censoring effect."
- Sequential simulation mode: An evaluation setting where decisions are made over time under resource constraints. "a sequential simulation mode for decision-making under resource constraints."
- Threat model: A formal description of attacker capabilities and goals for security/privacy evaluation. "We employed two adversaries representing distinct threat models"
- Tier-1 VC firms: Top venture firms with historically strong performance and reputations. "tier-1 VC firms are at 5.6\% ()."
- Tool-assisted model: A model augmented with external tools (e.g., web search) during inference. "tool-assisted models with web search"
- Vanilla LLM: A baseline LLM used without task-specific fine-tuning or specialized tools. "Predictive performances of nine vanilla LLMs on VCBench, with human-level baselines."
- Vocabulary compression: Reducing the number of unique tokens/labels via normalization to improve consistency. "Table~\ref{tab:standardisation_and_filtering} summarizes vocabulary compression after standardization and filtering."
Collections
Sign up for free to add this paper to one or more collections.