- The paper introduces VCBench, a benchmark featuring 1,720 multimodal problems designed to evaluate integrated visual and mathematical reasoning in LVLMs.
- It employs multi-image tasks spanning spatial, temporal, and geometric domains, demonstrating significant performance gaps relative to human benchmarks.
- It reveals that while Chain-of-Thought reasoning can enhance complex tasks, models still struggle with perceptual integration and pattern recognition.
Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency
Introduction
The paper "Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency" introduces VCBench, a detailed benchmark designed to evaluate multimodal mathematical reasoning in LVLMs. VCBench is crafted to close the gap identified in existing benchmarks that predominantly focus on domain-specific knowledge, neglecting reasoning capabilities in fundamental mathematical and visual contexts. Through 1,720 problems and 6,697 images spread across six cognitive domains, VCBench demands that models integrate visual information from multiple sources, assessing their reasoning capabilities in realistic scenarios.
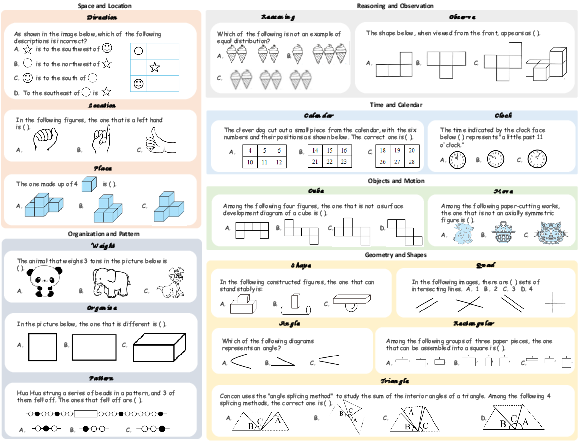
Figure 1: Representative examples from the VCBench, showcasing diverse question types and categories including Space and Location, Reasoning and Observation, Time and Calendar, Objects and Motion, Organization and Pattern, and Geometry and Shapes.
Current LVLM benchmarks such as MathVista and MathVision largely focus on assessing specialized domain knowledge rather than core reasoning abilities. This paper proposes a shift in focus towards elementary-level math problems that hinge on visual perceptual skills necessary for AGI. VCBench evaluates 26 state-of-the-art LVLMs and reports a significant performance disparity, highlighting an area where even leading models underperform compared to human benchmarks.
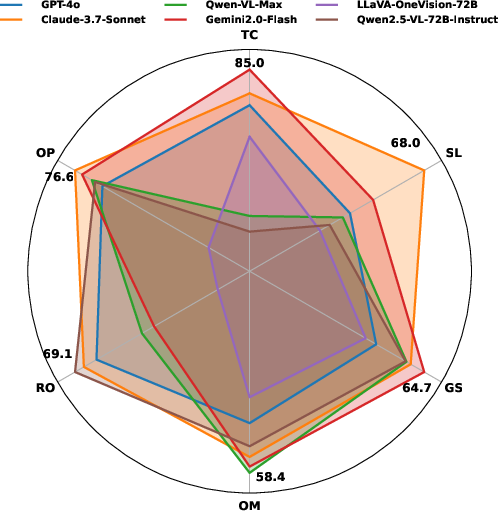
Figure 2: Comparative performance (\%) of six various prominent LVLMs across categories: Time and Calendar, Space and Location, Geometry and Shapes, Objects and Motion, Reasoning and Observation, and Organization and Pattern.
Experimentation
The evaluation conducted using VCBench reveals glaring performance gaps among LVLMs. No model exceeded a 50% average accuracy score across cognitive domains, demonstrating significant weaknesses in pattern recognition and multi-image reasoning.
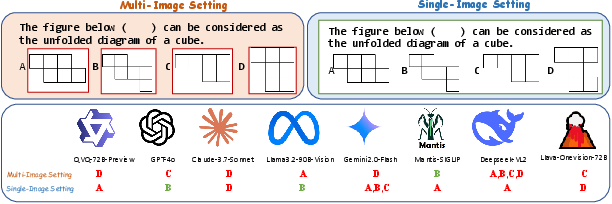
Figure 3: Comparative evaluation of LVLMs under Multi-Image and Single-Image settings for the same question.
Key contributions include the emphasis on perceptual reasoning devoid of specialized knowledge, multi-image tasks requiring information synthesis, and an evaluation framework highlighting core visual reasoning abilities in LVLMs.
Benchmark Design and Statistics
VCBench stands out with its multi-image tasks and emphasis on temporal, spatial, geometric, logical, and pattern-based reasoning. The benchmark includes a total of 6,697 images, averaging 3.9 images per question, forcing models to reason across multiple visual inputs. This design addresses gaps in real-world applications where visual information is distributed.

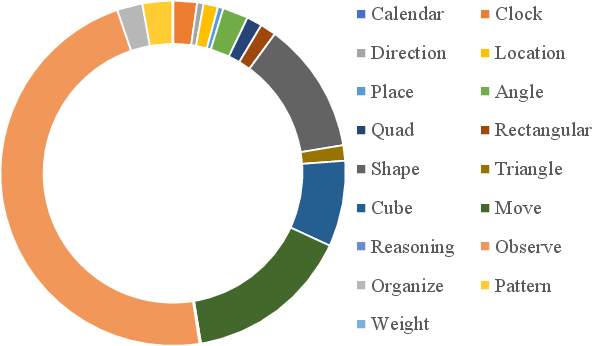
Figure 4: Overview of the VCBench dataset structure illustrating question-type distributions across major categories.
Single-Image Setting Insights
The results from single-image settings reveal a bias in existing models towards single-image optimization, with average improvements over multi-image tasks. This suggests ongoing challenges in models' ability to integrate multiple sources of visual information, a core reasoning capability.
Influence of Chain-of-Thought
Chain-of-Thought (CoT) reasoning shows varying influences on model performance. Generally, CoT improves outcomes in complex reasoning tasks but remains less effective in perception-centric challenges. This suggests structured reasoning prompts could enhance future model capabilities in complex tasks.
Error Distribution Analysis
Error categorization highlights visual perception shortcomings across models, which is identified as a key challenge for multimodal reasoning. Patterns show consistent weaknesses in perception and logical processing, indicating critical areas for model improvement.
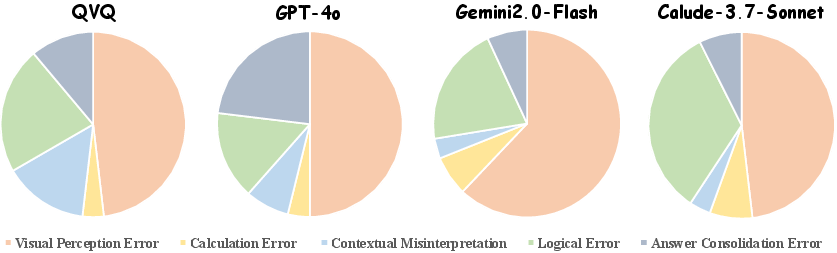
Figure 5: Error distribution among models for various error categories including visual perception errors, calculation errors, contextual misunderstandings, logical errors, and answer integration errors.
Conclusion
VCBench effectively illustrates the current limitations of LVLMs in multimodal mathematical reasoning with explicit visual dependencies, underscoring the need for improved models capable of cross-image integration and reasoning. While outstanding difficulties persist, VCBench contributes critical insights towards advancing AGI capabilities through enhanced evaluation methodologies.
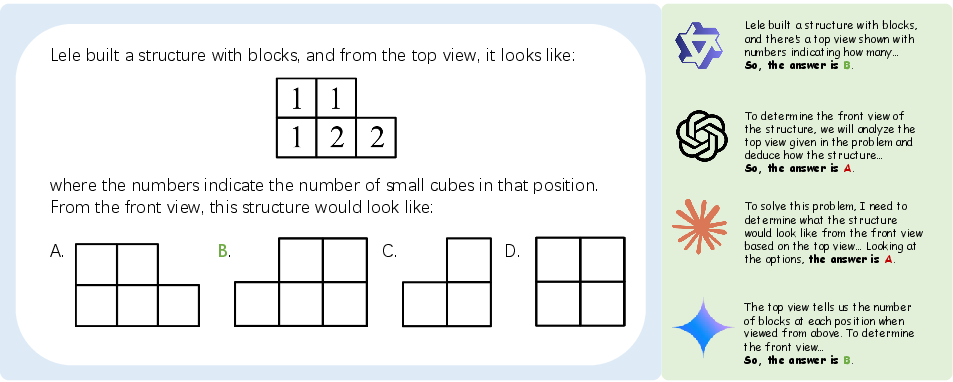
Figure 6: An example case highlighting visual perception errors encountered by models.
VCBench serves as a foundational resource for future research aimed at elevating the capabilities of LVLMs in complex, multimodal contexts.

