- The paper introduces Progressive Knowledge Enhancement (PKE), a multi-stage prompting method that improves ALPG code generation for semiconductor test equipment.
- It demonstrates that organizing examples by difficulty—from easy to hard—yields 11-15% improvements in metrics like Exact Match and BLEU.
- Results validate that curriculum-inspired prompts activate latent domain knowledge, enabling LLMs to tackle low-resource, hardware-specific languages effectively.
Automating Code Generation for Semiconductor Equipment Control from Developer Utterances with LLMs
Introduction
The paper addresses the challenge of automating code generation for semiconductor equipment control, specifically targeting the Algorithmic Pattern Generator (ALPG) language, a proprietary, low-level language used in semiconductor test equipment. Unlike high-level languages, ALPG is characterized by hardware-specific instructions, nanosecond-level timing, and non-standard control flow, making it inaccessible to non-experts and difficult for LLMs to generate code for, due to limited training data and lack of public documentation. The authors propose Progressive Knowledge Enhancement (PKE), a multi-stage prompting framework that systematically extracts and activates latent knowledge in LLMs, guiding them from simple to complex examples to improve code generation accuracy without extensive fine-tuning.
PKE Framework: Design and Implementation
PKE is a four-stage prompting pipeline designed to elicit and structure domain knowledge within LLMs for specialized code generation tasks.
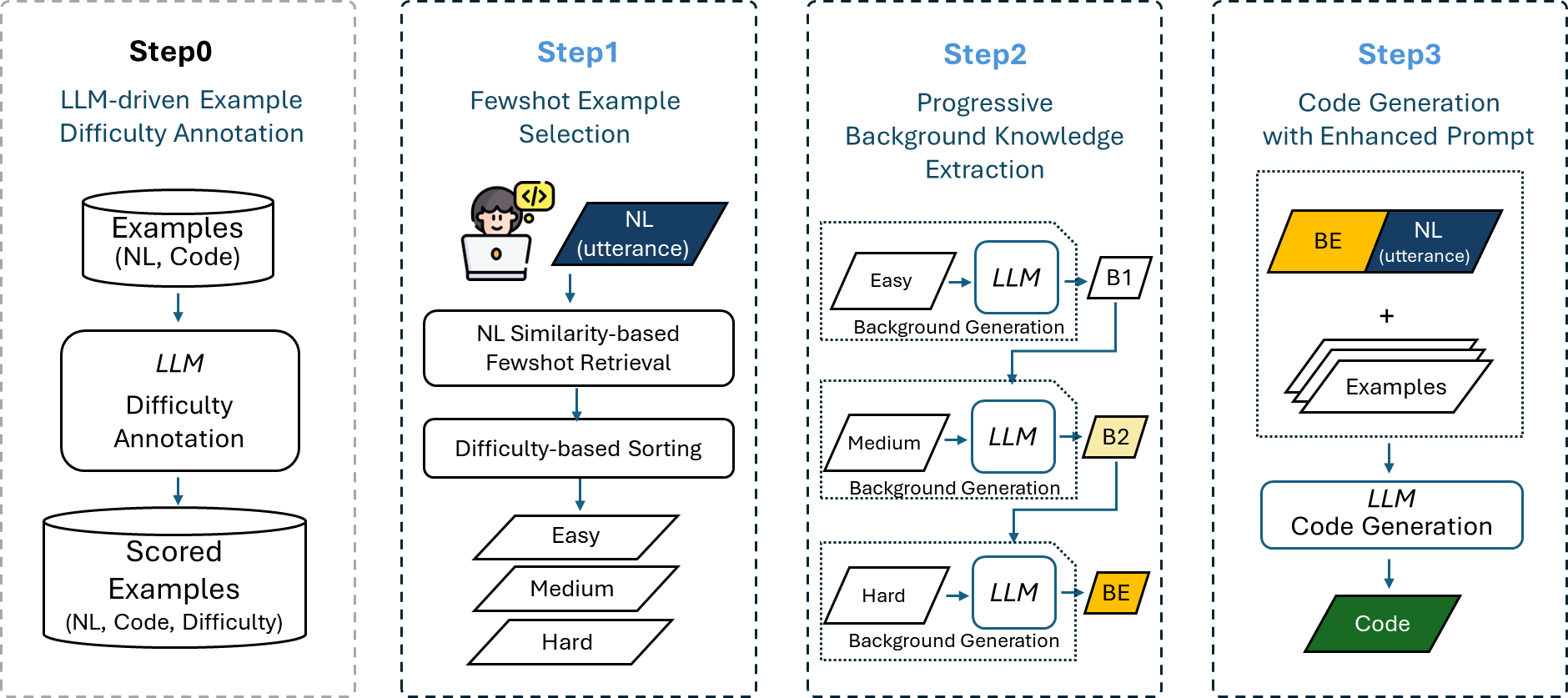
Figure 1: PKE Framework Overview. The framework consists of four main stages: Step 0 performs LLM-adaptive difficulty annotation, Step 1 conducts dynamic few-shot example selection, Step 2 implements sequential reasoning enhancement, and Step 3 generates the final ALPG code.
Step 0: LLM-Adaptive Difficulty Annotation
The process begins by annotating a corpus of NL-ALPG pairs with difficulty scores, using an LLM to rate each example on a 0–100 scale based on syntax complexity, hardware interaction, timing constraints, and implementation challenge. Multiple temperature settings are used to ensure robustness, and the average score is used for each example. This step is performed once per corpus and enables subsequent stages to leverage difficulty-aware curriculum learning.
Step 1: Dynamic Few-Shot Example Selection
For each developer utterance, semantically similar examples are retrieved from the annotated corpus using BM25 or similar retrieval metrics. The selected examples are then sorted by difficulty, ensuring that the LLM is exposed to a progression from easy to hard, which is critical for effective knowledge extraction in the next stage.
Step 2: Sequential Reasoning Enhancement
The LLM is prompted to extract and synthesize background knowledge by sequentially processing easy, medium, and hard examples. At each stage, the model is asked to articulate domain knowledge necessary for generating the corresponding ALPG code, cumulatively building a knowledge base (BE) that reflects increasing complexity and domain specificity.
Step 3: Enhanced Code Generation
The final prompt concatenates the enhanced background knowledge (BE), the selected few-shot examples, and the developer's NL query. This structure ensures that the LLM first internalizes domain principles before seeing concrete implementation patterns, leading to more accurate and contextually appropriate ALPG code generation.
Experimental Setup
The evaluation uses a proprietary dataset of 271 NL-ALPG pairs, with ground-truth code verified by domain experts. Two in-house LLMs (70B and 65B parameters) are used to ensure data privacy. The primary metrics are Exact Match (EM), BLEU, and Levenshtein distance, providing a comprehensive assessment of syntactic and semantic correctness as well as post-editing effort.
Baselines include zero-shot prompting, standard few-shot prompting (BM25-based), MapCoder (multi-agent code generation), and μFix (iterative specification refinement). All baselines are adapted to the ALPG domain by prompt engineering.
Results and Analysis
PKE outperforms all baselines across all metrics. For the 70B model, PKE achieves an EM of 0.315, BLEU of 0.745, and Levenshtein of 0.813, representing 11.1% (EM), 3.8% (BLEU), and 4.0% (Levenshtein) improvements over the second-best approach. The 65B model shows even larger gains, with EM improvement of 15.2%. Zero-shot and SOTA baselines perform poorly, often failing to generate valid ALPG syntax or hardware-specific logic.
Progressive extraction based on similarity yields modest improvements over few-shot baselines, but difficulty-aware ordering (easy-to-hard) yields the largest gains. For the 65B model, EM increases from 0.289 (few-shot) to 0.333 (PKE), a 15.2% absolute improvement. This demonstrates that curriculum-inspired ordering is critical for activating relevant knowledge in LLMs for low-resource, domain-specific languages.
Sensitivity to Example Difficulty
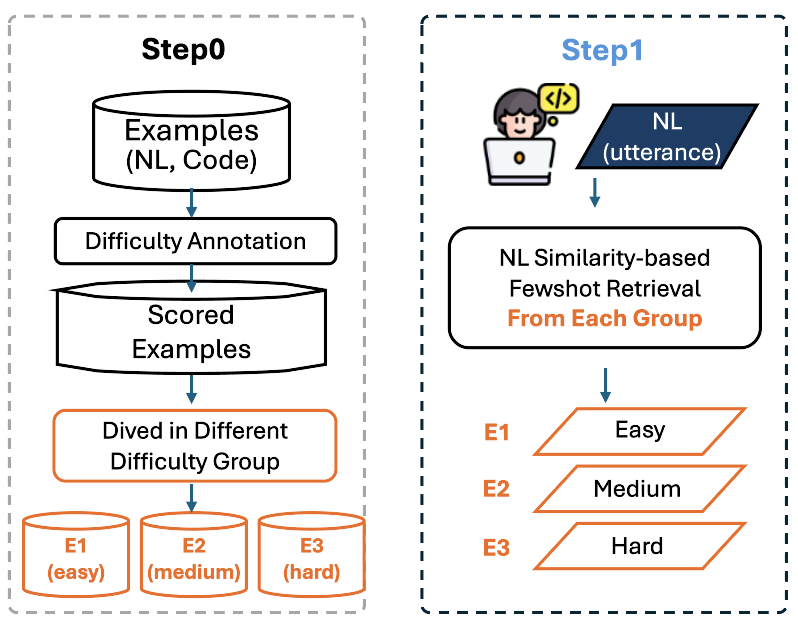 *Figure 2: D{additional_guidance}R Configuration in Step0 and step1. *
*Figure 2: D{additional_guidance}R Configuration in Step0 and step1. *
Experiments with the Divide-and-Retrieve (D{content}R) configuration show that using only hard or medium examples leads to a collapse in performance (EM drops to near zero), while using only easy examples is suboptimal. The best D{content}R performance is achieved with a mix of easy, medium, and hard examples, but PKE's retrieve-and-sort approach, which prioritizes similarity and then orders by difficulty, consistently outperforms all D{content}R variants. This highlights the importance of both semantic relevance and difficulty progression in example selection.
Practical and Theoretical Implications
PKE demonstrates that LLMs possess latent knowledge of low-level, hardware-specific programming concepts, but this knowledge is not activated by standard prompting. By structuring prompts to mimic human curriculum learning, PKE enables LLMs to synthesize and apply domain knowledge for specialized code generation tasks. This approach is practical for industrial settings where fine-tuning is infeasible due to data scarcity or privacy constraints.
Theoretically, the results suggest that prompt-based curriculum learning can serve as a substitute for data-intensive fine-tuning in low-resource domains. The strong sensitivity to example difficulty also indicates that LLMs' internal representations are more effectively leveraged when exposed to a structured progression of complexity.
Future Directions
Potential extensions include integrating human-provided knowledge with model-extracted knowledge, scaling to other proprietary or low-level languages, and quantifying productivity gains in real-world developer workflows. Further research could explore automated curriculum construction, adaptive example selection, and the interplay between prompt engineering and model architecture for domain adaptation.
Conclusion
The PKE framework provides a systematic, prompting-based approach for automating code generation in proprietary, low-level equipment control languages. By leveraging LLM-adaptive difficulty annotation, dynamic example selection, and progressive knowledge extraction, PKE achieves substantial improvements over standard and SOTA prompting methods. The findings underscore the importance of curriculum-inspired prompt design for activating latent domain knowledge in LLMs, offering a practical pathway for deploying LLMs in specialized industrial software development contexts.

