- The paper showcases a novel framework (ZK-Coder) that significantly improves LLM accuracy for zero-knowledge proof code synthesis.
- It introduces ZK-Eval, a benchmark evaluating LLM performance on syntax, gadget implementation, and end-to-end ZKP generation.
- Empirical results show up to 94.12% accuracy on Noir and 89.23% on Circom, underscoring the benefits of agentic augmentation.
LLMs for Zero-Knowledge Proof Code Generation: Evaluation and Enhancement
Introduction
This paper addresses the intersection of LLMs and zero-knowledge proof (ZKP) program synthesis, focusing on the unique challenges posed by ZK programming compared to mainstream software development. ZKPs require developers to encode mathematical constraints over finite fields, leveraging domain-specific languages (DSLs) such as Circom and Noir, and to compose reusable gadgets for constraint systems. The authors introduce ZK-Eval, a comprehensive benchmark for evaluating LLM capabilities in ZK code generation, and ZK-Coder, an agentic framework that augments LLMs with constraint sketching, retrieval-augmented generation (RAG), and interactive repair. The empirical results demonstrate substantial improvements in end-to-end ZK program synthesis, with ZK-Coder achieving up to 94.12% accuracy on Noir and 89.23% on Circom, compared to baseline rates below 33%.
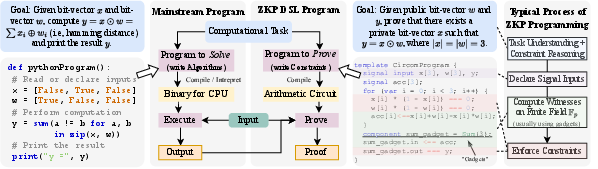
Figure 1: Comparison between mainstream and ZK programming workflows, highlighting the constraint-oriented nature of ZK development.
ZK Programming: Challenges and Requirements
ZK programming diverges fundamentally from imperative paradigms. Instead of specifying computation, developers encode relations $R(x, w) = 1$ over public inputs $x$ and private witnesses $w$, which are compiled into arithmetic circuits. DSLs such as Circom and Noir expose different abstraction levels: Circom requires explicit circuit wiring and signal management, while Noir offers Rust-like syntax and type safety. The complexity of ZK development is compounded by the need to compose and implement gadgets—modular building blocks for constraints—where correctness is not always enforced by compilers.
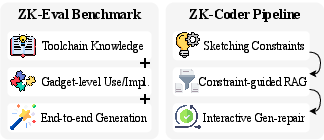
Figure 2: Overview of the ZK-Eval benchmark and ZK-Coder agentic framework.
ZK-Eval: Benchmarking LLMs for ZK Code Generation
ZK-Eval is designed to probe LLM capabilities at three granular levels:
- Language and Toolchain Knowledge: Assessed via multiple-choice questions (MCQs) covering syntax, advanced features, API references, and compiler principles for Circom and Noir.
- Gadget-Level Competence: Evaluated by tasks requiring the use or implementation of 35 representative gadgets, spanning logical, arithmetic, and composite operators.
- End-to-End Program Generation: Adapted from HumanEval, reformulated as verification problems suitable for ZK DSLs, with dual test suites for soundness and completeness.
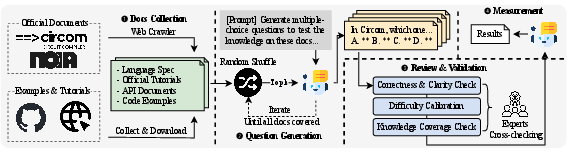
Figure 3: Design of the MCQ benchmark for evaluating LLM knowledge of ZK languages.

Figure 4: Example MCQ on Circom syntax and summary of knowledge categories.
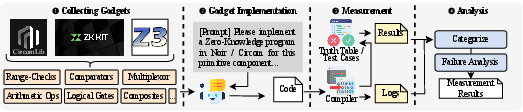
Figure 5: Gadget benchmark design for assessing LLMs' ability to encode constraints using gadgets.
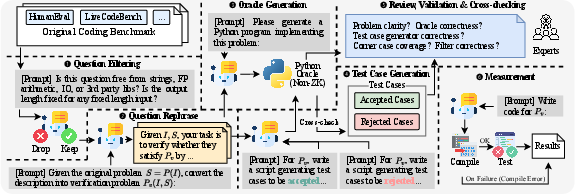
Figure 6: End-to-end ZK program generation benchmark adapted from HumanEval.
Four LLMs were evaluated: GPT-o4-mini, GPT-o3, DeepSeek-V3, and Qwen3. Key findings include:
- Language Knowledge: Reasoning models (GPT-o4-mini, GPT-o3) achieve near-human expert accuracy (88.1% and 87.2%), outperforming open-source models (DeepSeek-V3, Qwen3 at ~79%).
- Gadget Competence: All models struggle, with logical gadgets reaching only ~52% accuracy and arithmetic/composite gadgets dropping below 20%. Typing errors and signal mismanagement are prevalent.
- End-to-End Generation: Baseline pass rates are low (Circom: 17.35–20.29%, Noir: 27.94–32.21%), with semantic correctness lagging behind syntactic validity.
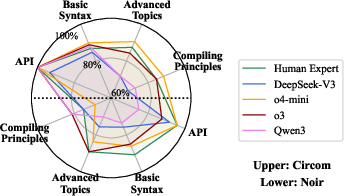
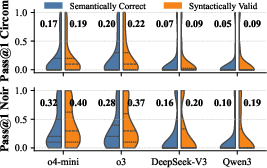
Figure 7: Accuracy of LLMs and human experts on the MCQ benchmark for ZK language knowledge.
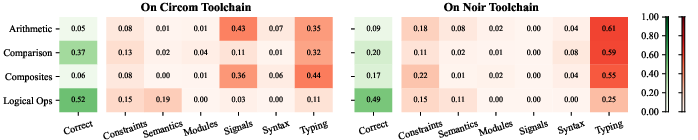
Figure 8: Error distribution in gadget implementations across languages, types, and causes.
ZK-Coder: Agentic Enhancement of LLMs
ZK-Coder is introduced to bridge the gap between surface-level language knowledge and reliable ZK program synthesis. Its pipeline consists of:
- Constraint Sketching: Translates natural language specifications into ZKSL, an intermediate sketch language abstracting constraints.
- Constraint-Guided Retrieval: Analyzes sketches to extract required gadgets and retrieves implementation hints from a curated knowledge base, enforcing operator/type/arity matching.
- Interactive Generation and Repair: Iteratively generates code, compiles, and tests against semantic oracles, repairing based on diagnostics and counterexamples until correctness is achieved.
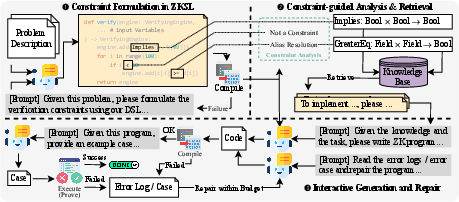
Figure 9: Overview of ZK-Coder's design, illustrating the agentic workflow from sketching to repair.
Experimental Results: ZK-Coder vs. Baseline
ZK-Coder demonstrates substantial improvements over direct LLM prompting:
- Circom: GPT-o4-mini achieves 83.38% overall accuracy, GPT-o3 89.23%.
- Noir: GPT-o4-mini reaches 90.05%, GPT-o3 94.12%.
- Token Cost: The agentic pipeline incurs higher token usage but remains cost-effective (<0.1 USD per task).
Ablation studies confirm the necessity of each component: removing sketching, RAG, or repair loops results in significant accuracy drops (e.g., disabling syntax repair reduces accuracy to 35% on Circom).
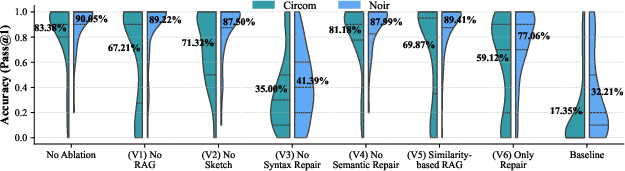
Figure 10: Accuracy comparison of ZK-Coder ablation variants, highlighting the impact of each design component.
Robust Generalization and Failure Analysis
On the contamination-free LiveCodeBench benchmark, ZK-Coder maintains strong performance (Circom: 72.25%, Noir: 82.32%), far exceeding baseline rates. Failure analysis reveals that most errors stem from exceeding the repair budget or incorrect sketch generation, underscoring the need for improved ZK-specific training data and more robust sketch grounding.
Illustrative Example: Sudoku Verification
The paper provides a detailed workflow example where ZK-Coder generates a ZKP program for verifying Sudoku correctness, demonstrating the translation from natural language to ZKSL, constraint-guided retrieval, and iterative repair.
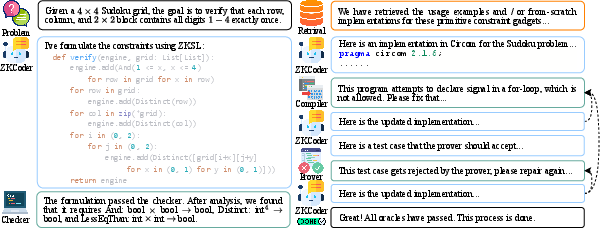
Figure 11: ZK-Coder's workflow for proving Sudoku correctness.
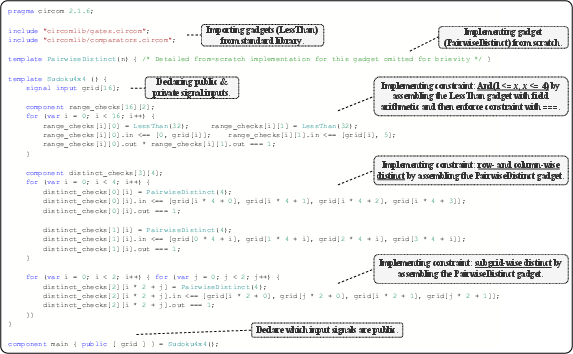
Figure 12: Example Circom program generated by ZK-Coder for Sudoku verification.
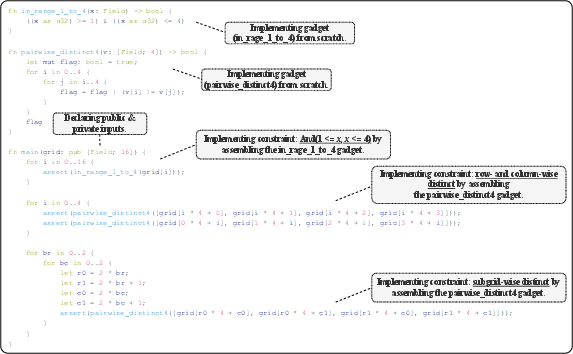
Figure 13: Example Noir program generated by ZK-Coder for Sudoku verification.
Implications and Future Directions
The results establish that while LLMs possess strong surface-level knowledge of ZK DSLs, reliable gadget construction and end-to-end synthesis require agentic augmentation. ZK-Coder's pipeline—combining sketching, RAG, and interactive repair—substantially lowers the barrier for ZK program development and advances trustworthy computation. The findings suggest several avenues for future research:
- Circuit Optimization: Guiding LLMs to produce efficient circuits, not just correct ones, by incorporating ZK-friendly primitives and optimization strategies.
- Training Data Expansion: Systematic generation of ZK DSL examples to support targeted LLM fine-tuning and domain adaptation.
- Benchmark Extension: Incremental addition of advanced and cryptographic gadgets to the evaluation suite.
Conclusion
This work presents ZK-Eval, the first systematic benchmark for LLM-based ZK program synthesis, and ZK-Coder, an agentic framework that significantly enhances LLM performance in this domain. The empirical evidence demonstrates that agentic augmentation is essential for bridging the gap between language knowledge and reliable ZK code generation, with practical implications for privacy-preserving computation and secure software engineering.