- The paper introduces a miniature multimodal model that achieves 90% of large-model performance using just 5% of the parameters.
- It employs a compact vision encoder distilled from a larger model and integrates with pre-trained LLMs via an MLP projector for visual instruction tuning.
- The unified adaptation framework reformulates diverse visual tasks into a VQA format, enabling efficient domain transfer and specialized applications.
The paper "Mini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance" introduces a series of lightweight Multimodal LLMs (MLLMs) designated as Mini-InternVL. These models promise significant efficiency improvements, achieving approximately 90% of the performance of much larger counterparts using only 5% of the parameters. This breakthrough allows for enhanced application in various specialized domains including autonomous driving, medical imaging, and remote sensing.
Architecture of Mini-InternVL
Mini-InternVL incorporates an innovative architecture which prominently features InternViT-300M as a compact vision encoder. This vision encoder, distilled from a larger InternViT-6B model, acquires world knowledge through a unique knowledge distillation process.
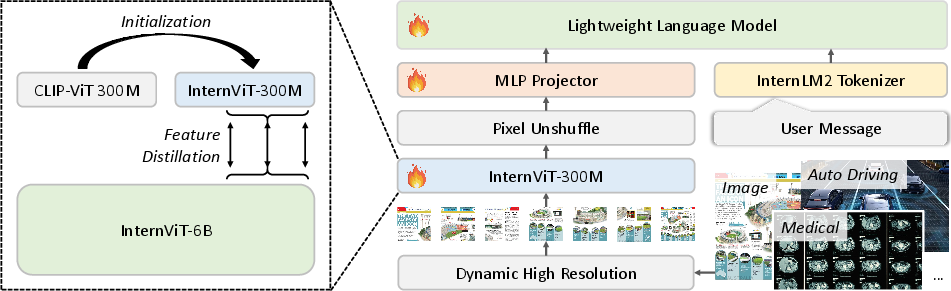
Figure 1: Training method and architecture of Mini-InternVL. Left: We employ InternViT-6B as the teacher model to perform knowledge distillation on the student model.
Three versions of the model exist, scaling from 1 billion to 4 billion parameters. They integrate the vision encoder with various pre-trained LLMs, relying on an MLP projector for seamless integration. Training involves two main stages: language-image alignment, followed by visual instruction tuning, to endow Mini-InternVL with robust multimodal understanding capabilities.
Unified Adaptation Framework
To facilitate easy domain transfer, the paper introduces a streamlined adaptation framework. This framework reformulates diverse visual tasks into a Visual Question Answering (VQA) format, simplifying model adjustments across various tasks such as image classification, region perception, and video-related tasks.
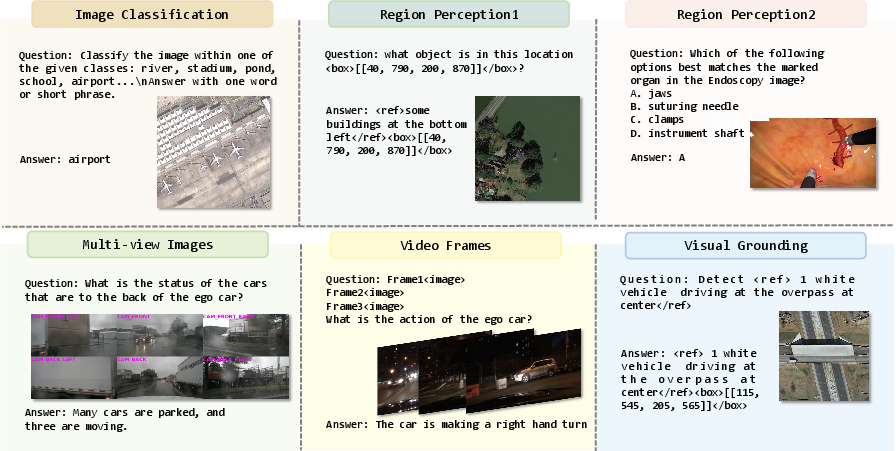
Figure 2: The data format of our adaptation framework. We formulate other visual tasks (i.e., image classification, region perception, multi-view image tasks, video-related tasks, and visual grounding) into VQA format in our framework.
The adaptation framework standardizes model architecture, data format, and training schedules, thus allowing swift domain adaptation with low marginal costs.
Transfer Learning and Domain Adaptation
The proposed transfer learning paradigm leverages the strengths of Mini-InternVL for specialized domains. By using a blend of domain-specific and general training data, these models exhibit remarkable performance and versatility across a vast array of tasks. The framework integrates data from multiple publicly available datasets, promoting robust model training and domain adaptation.
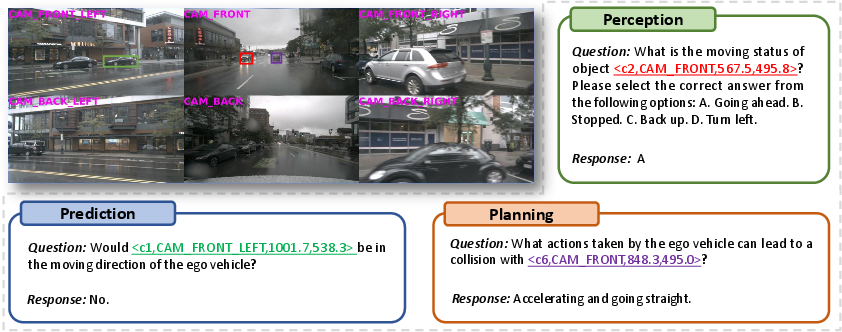
Figure 3: Qualitative Results of . In the upper left corner is a multi-view image from DriveLM-nuScenes version-1.1 after data processing. The model's outputs align with human driving behavior.
Extensive testing across various benchmarks demonstrates that Mini-InternVL achieves impressive performance metrics, particularly excelling in tasks involving OCR and specialized image analysis. The study also conducts a thorough examination of different training mechanisms, evaluating their impacts on computational efficiency and model performance.
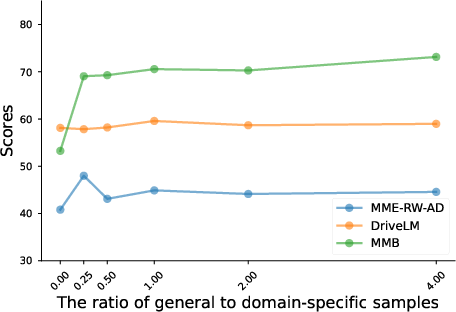
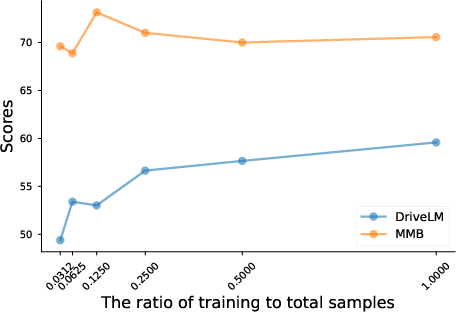
Figure 4: The impact of the proportion of general data.
For example, in autonomous driving scenarios, after domain adaptation, models exhibited enhanced perception, prediction, and planning capabilities. Additionally, the effects of different adaptation techniques and training sample sizes on end performance are analyzed, illustrating the nuanced trade-offs between performance and computational resource allocation.
Conclusion
The Mini-InternVL series addresses the increasing demand for efficient multimodal models capable of operating effectively within constrained computational resources. By unifying model adaptation processes and streamlining domain transfer, Mini-InternVL stands as a significant contribution to the practical deployment of MLLMs. The paper invites future exploration into expanding the capabilities and applications of such efficient models within other demanding domains.