- The paper introduces permutation generation as a novel LLM instruction that directly ranks passages in zero-shot settings.
- Empirical evaluations reveal GPT-4’s superior nDCG@10 performance over state-of-the-art models across multiple benchmarks.
- A permutation distillation strategy efficiently transfers LLM ranking capabilities to smaller models, enhancing cost-effectiveness.
LLMs as Passage Re-Ranking Agents: An In-Depth Analysis
Introduction and Motivation
The paper "Is ChatGPT Good at Search? Investigating LLMs as Re-Ranking Agents" (2304.09542) systematically examines the capabilities of generative LLMs, specifically ChatGPT and GPT-4, in the context of passage re-ranking for information retrieval (IR). The study addresses two primary research questions: (1) the effectiveness of LLMs as zero-shot re-ranking agents, and (2) the feasibility of distilling their ranking capabilities into smaller, specialized models suitable for practical deployment.
Instructional Paradigms for LLM-Based Re-Ranking
The authors compare three instructional paradigms for leveraging LLMs in passage re-ranking: query generation, relevance generation, and permutation generation. The permutation generation approach, introduced in this work, directly instructs the LLM to output a ranked permutation of passage identifiers based on relevance to a query, bypassing the need for intermediate relevance scores or log-probabilities.

Figure 1: Three types of instructions for zero-shot passage re-ranking with LLMs: (a) query generation, (b) relevance generation, and (c) permutation generation.
Permutation generation is shown to be more effective and compatible with black-box LLM APIs (e.g., ChatGPT, GPT-4) that do not expose token-level log-probabilities. To address context length limitations, a sliding window strategy is proposed, where overlapping windows of passages are re-ranked iteratively.
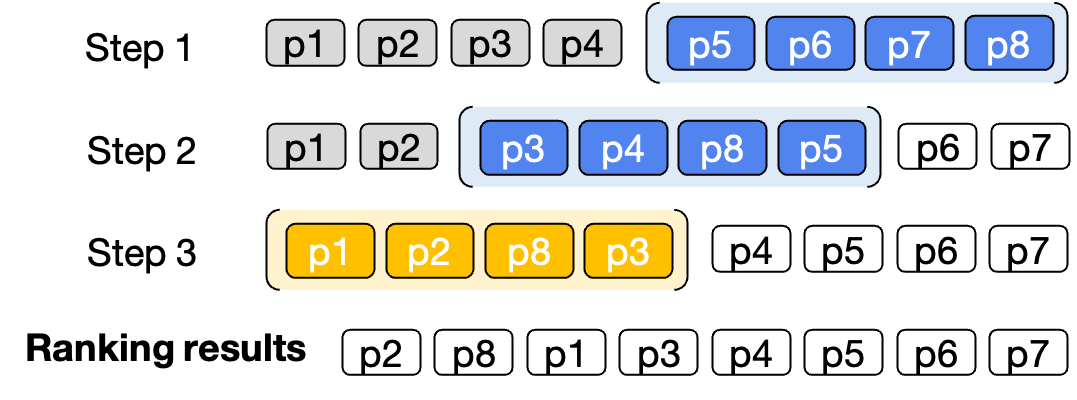
Figure 2: Sliding window strategy for re-ranking passages, enabling LLMs to process large candidate sets despite context length constraints.
Empirical Evaluation on Standard and Novel Benchmarks
The study conducts comprehensive experiments on established IR benchmarks (TREC-DL, BEIR, Mr.TyDi) and introduces NovelEval, a new test set designed to mitigate data contamination by focusing on post-training knowledge.
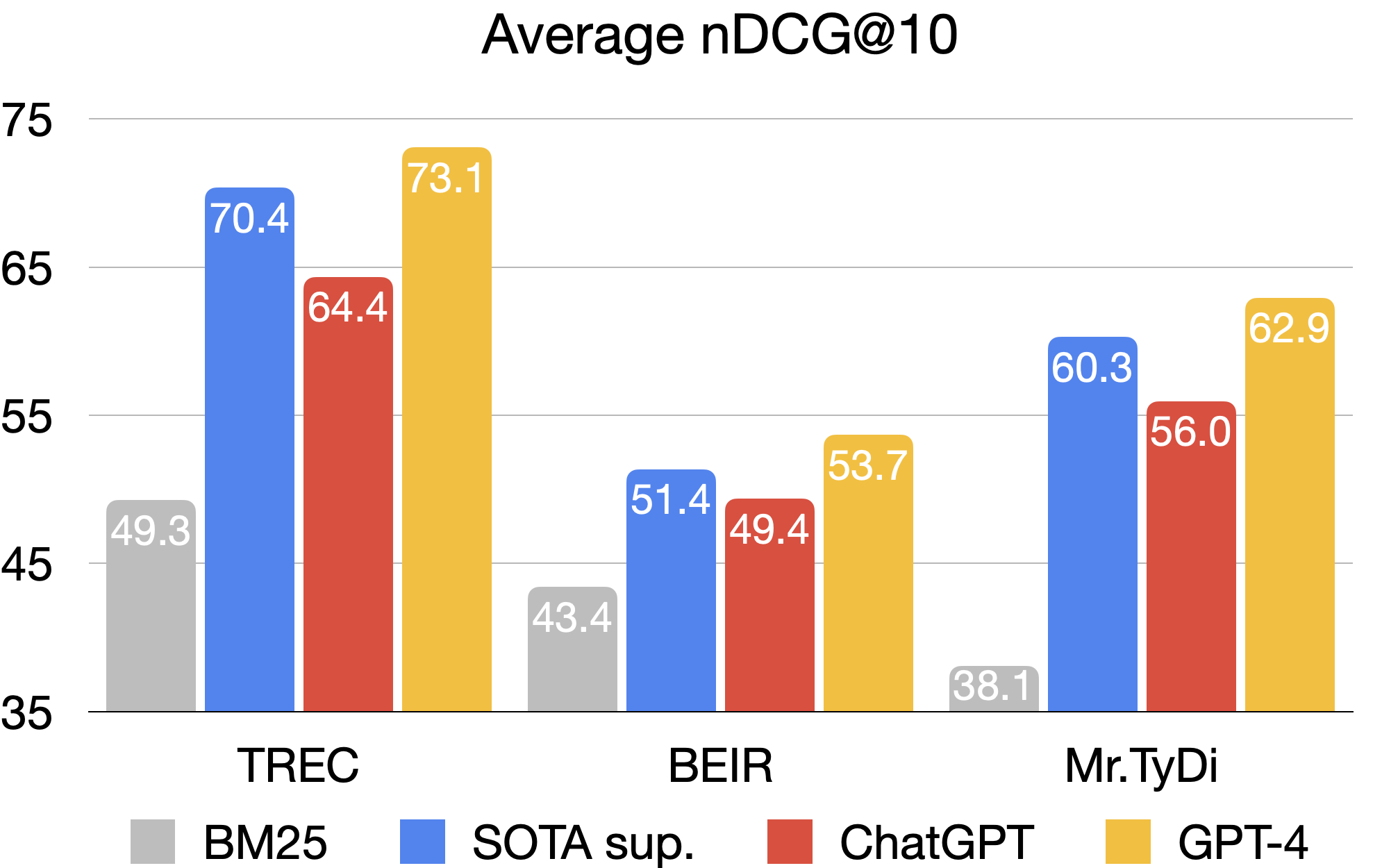
Figure 3: Average results of ChatGPT and GPT-4 (zero-shot) on passage re-ranking benchmarks, compared with BM25 and previous best-supervised systems.
Key findings include:
- GPT-4 with permutation generation achieves average nDCG@10 improvements of 2.7 (TREC), 2.3 (BEIR), and 2.7 (Mr.TyDi) over the previous SOTA monoT5 (3B) model.
- ChatGPT (gpt-3.5-turbo) also outperforms most supervised baselines on BEIR.
- On the NovelEval set, GPT-4 achieves nDCG@10 of 90.45, significantly surpassing monoT5 (3B) at 84.62, demonstrating robust generalization to previously unseen knowledge.
The results on Mr.TyDi further indicate that GPT-4 outperforms supervised systems in most low-resource languages, though performance degrades in languages with weaker LLM coverage, likely due to tokenization inefficiencies and limited pretraining data.
Permutation Distillation: Specializing Small Models
To address the high inference cost and latency of LLMs, the authors propose permutation distillation: using ChatGPT-generated permutations as supervision to train smaller, efficient re-ranking models. The distillation process employs a RankNet-based pairwise loss, optimizing the student model to match the teacher's (ChatGPT's) output orderings.
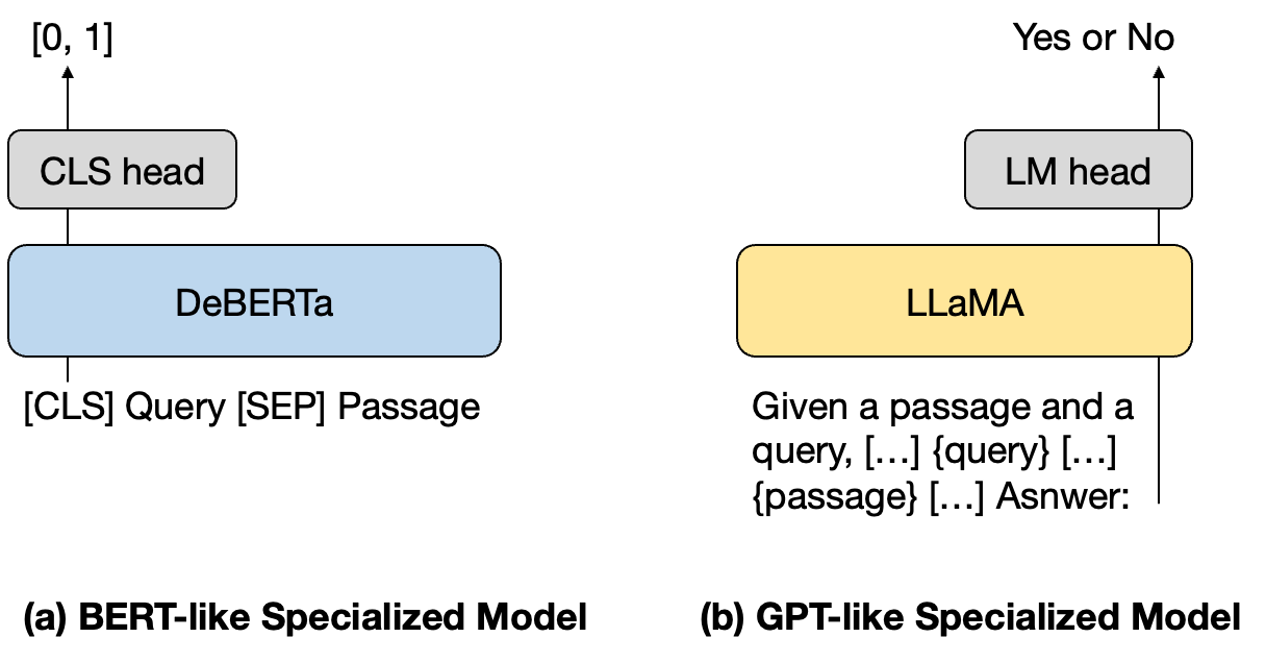
Figure 4: Model architecture of BERT-like (cross-encoder) and GPT-like (autoregressive) specialized models used for permutation distillation.
Both BERT-like (DeBERTa) and GPT-like (LLaMA) architectures are evaluated. The distilled DeBERTa-large (435M) model, trained on 10K ChatGPT-labeled queries, outperforms the 3B monoT5 SOTA model on BEIR (nDCG@10: 53.03 vs. 51.36), while being significantly more cost-efficient.
Scaling Analysis: Model and Data Size
The scaling analysis demonstrates that permutation-distilled models consistently outperform supervised models across a range of model sizes (70M–435M) and training data sizes (500–10K queries). Notably, even with only 1K training queries, the distilled DeBERTa model surpasses monoT5 (3B) on BEIR.
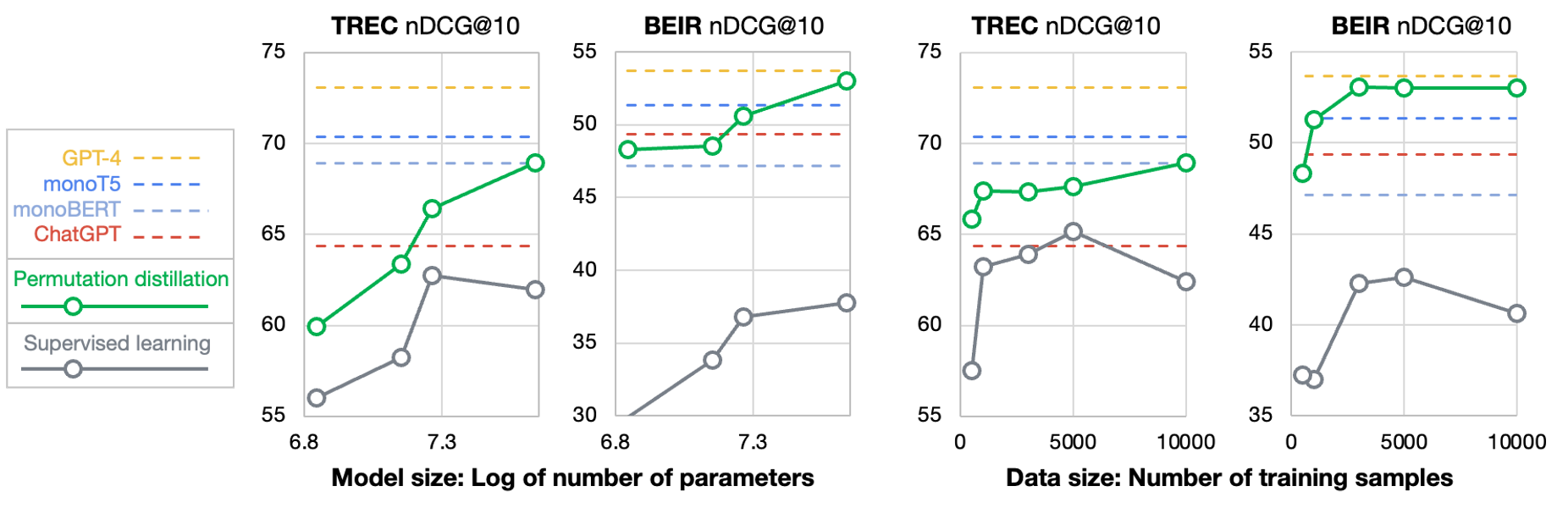
Figure 5: Scaling experiment showing performance of specialized DeBERTa models via permutation distillation and supervised learning across model/data sizes.
Increasing model size yields greater performance gains than increasing training data, and permutation-distilled models exhibit more stable performance than their supervised counterparts, which are susceptible to label noise in MS MARCO.
Practical Considerations and Limitations
- Cost and Latency: Direct use of GPT-4 for re-ranking is expensive and slow (e.g., $0.60 per query, 32s latency). The sliding window and hybrid strategies (e.g., ChatGPT for top-100, GPT-4 for top-30) can reduce cost with minimal performance loss.
- Stability: GPT-4 is more stable than ChatGPT in generating valid permutations, with fewer missing or duplicate identifiers.
- Sensitivity to Initial Order: The re-ranking effect is highly sensitive to the initial passage order, typically determined by the first-stage retriever (e.g., BM25).
- Open-Source Models: Current open-source LLMs (e.g., FLAN-T5, ChatGLM-6B, Vicuna-13B) lag significantly behind ChatGPT/GPT-4 in permutation generation for re-ranking, highlighting a gap in open-source IR capabilities.
Theoretical and Practical Implications
The findings challenge the assumption that LLMs' generative pretraining objectives are misaligned with ranking tasks. With appropriate instruction (permutation generation), LLMs can perform listwise ranking competitively, even in zero-shot settings. The success of permutation distillation suggests that LLMs encode rich, transferable relevance signals that can be efficiently transferred to smaller models, mitigating the cost and latency barriers to deployment.
The introduction of NovelEval addresses the critical issue of test set contamination and provides a template for future IR evaluation in the era of rapidly evolving LLMs.
Future Directions
- Improving Open-Source LLMs: Bridging the performance gap in permutation-based re-ranking remains an open challenge.
- Robustness to Initial Retrieval: Developing LLM-based re-ranking methods less sensitive to the initial candidate order could further improve reliability.
- First-Stage Retrieval: Extending LLM-based approaches to the retrieval stage, not just re-ranking, is a promising direction.
- Continual Evaluation: Regularly updating evaluation sets (e.g., NovelEval) is necessary to ensure fair assessment as LLMs' knowledge evolves.
Conclusion
This work provides a rigorous evaluation of LLMs as passage re-ranking agents, demonstrating that with proper instruction, models like GPT-4 can surpass strong supervised baselines in zero-shot settings. The permutation distillation approach enables the transfer of LLM ranking capabilities to smaller, efficient models, offering a practical path for real-world deployment. The results have significant implications for the design of future IR systems and the broader application of LLMs in ranking-centric tasks.