- The paper introduces SpatialVID as a large-scale video dataset with dense spatial annotations, enabling unified spatiotemporal modeling.
- It details a three-stage curation pipeline that filters, annotates, and samples millions of video clips to ensure high geometric and semantic accuracy.
- The dataset supports advanced tasks like 3D reconstruction, controllable video generation, and embodied navigation through explicit camera data and dynamic motion insights.
SpatialVID: A Large-Scale Video Dataset with Explicit Spatial Annotations
Motivation and Context
SpatialVID addresses a critical bottleneck in spatial intelligence and world modeling: the lack of large-scale, real-world video datasets with dense geometric and semantic annotations. Existing datasets either provide scale and semantic diversity without explicit 3D information, or offer geometric fidelity but are limited in diversity, scale, and dynamic content. This dichotomy impedes the development of unified models for spatiotemporal reasoning, 3D reconstruction, and controllable video generation. SpatialVID is designed to bridge this gap by providing millions of dynamic, in-the-wild video clips with per-frame camera poses, depth maps, structured captions, and serialized motion instructions.
Dataset Construction and Curation Pipeline
SpatialVID comprises 2.7 million clips (7,089 hours) curated from 21,000+ hours of raw YouTube videos. The curation pipeline consists of three stages: filtering, annotation, and sampling.
- Filtering: Raw videos are manually screened for diverse camera motion and scene content. Clips are segmented (3–15s) and filtered using multi-dimensional criteria: aesthetic quality (CLIP+MLP predictor), luminance, OCR-based text interference, and motion intensity (VMAF). Only clips with sufficient parallax, minimal dynamic foreground occlusion, and proper exposure are retained.




Figure 1: Aesthetics Filtering. Clips are scored for visual appeal; only those above threshold are retained for annotation.
- Annotation: Geometric annotation is performed using an enhanced MegaSaM pipeline, which integrates monocular depth priors (UniDepth v2, Depth Anything v2), motion probability maps, and uncertainty-aware bundle adjustment. Dynamic object segmentation is refined with SAM2, and dynamic ratio metrics are computed. Motion instructions are derived from temporally smoothed camera pose sequences, mapped to a controlled vocabulary of cinematographic terms. Structured captions are generated via a two-stage VLLM+LLM pipeline (Gemini-2.0-flash, Qwen3-30B-A3B), integrating scene semantics, camera motion, and hierarchical attributes (weather, lighting, time of day).
- Sampling: A high-quality subset (SpatialVID-HQ, 1,146 hours) is curated by raising quality thresholds and balancing semantic tags and trajectory statistics, ensuring comprehensive coverage for downstream tasks.
Annotation Modalities and Statistical Properties
SpatialVID provides dense multimodal annotations:
- Camera Poses and Depth Maps: Per-frame extrinsics and depth, enabling explicit 3D grounding.
- Dynamic Masks: Robust segmentation of moving objects for dynamic scene understanding.
- Motion Instructions: Serialized, interpretable motion commands for controllable video generation and navigation.
- Structured Captions: Multi-level textual descriptions, including scene summaries, shot-level narratives, and hierarchical semantic tags.
Statistical analysis reveals a broad and balanced distribution of motion directions, scene types, and semantic attributes. Caption length distributions show significant enrichment after spatial enhancement, supporting both high-level and fine-grained reasoning.
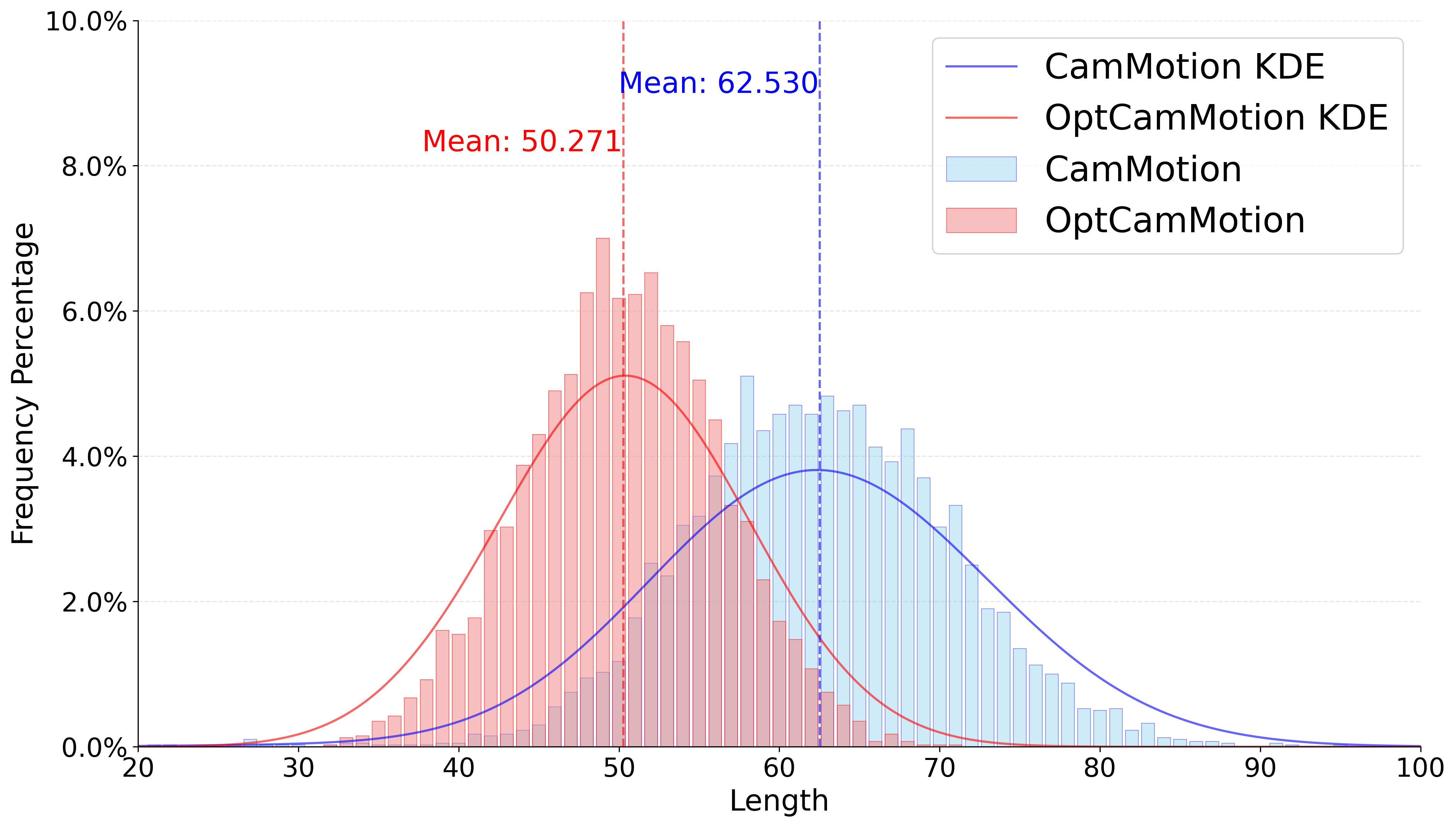
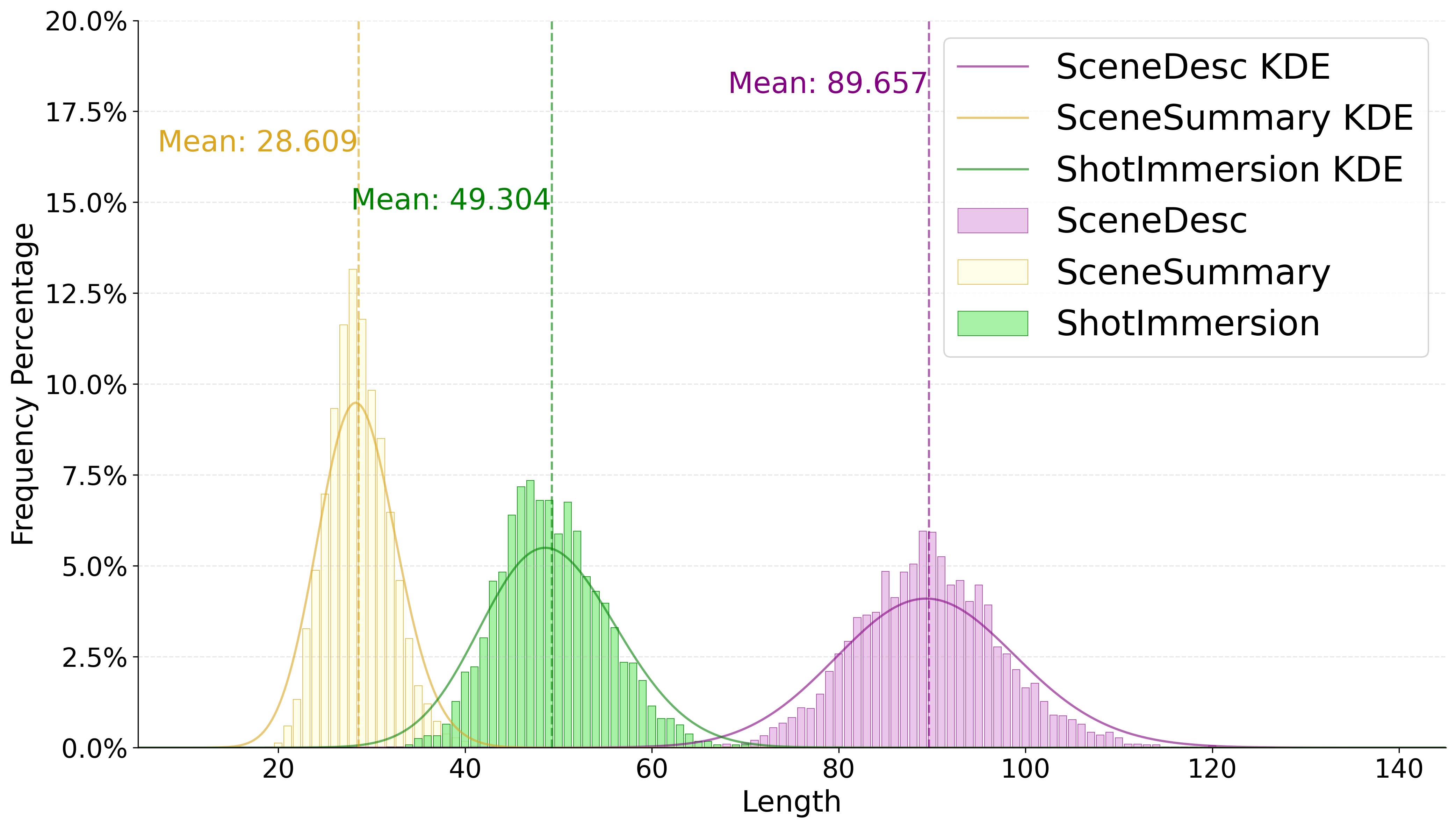
Figure 2: Motion caption length distribution. Enhanced captions are longer and more informative, supporting richer supervision.
Figure 3: Scene tags distribution. Sunburst chart shows hierarchical coverage of weather, time, crowd density, lighting, and scene type.
Comparative Analysis and Quality Assessment
SpatialVID is compared against Panda-70M and other spatial datasets. Key findings:
- Quality: SpatialVID-HQ exhibits superior consistency and higher average scores in aesthetics, luminance, and motion metrics.
- Motion Diversity: Unlike Panda-70M, which is dominated by static videos, SpatialVID features balanced and realistic camera movements, including complex trajectories and turns.
- Reconstruction Feasibility: Over 80% of Panda-70M videos are unsuitable for geometric annotation due to insufficient motion, whereas SpatialVID is explicitly curated for reconstructability.
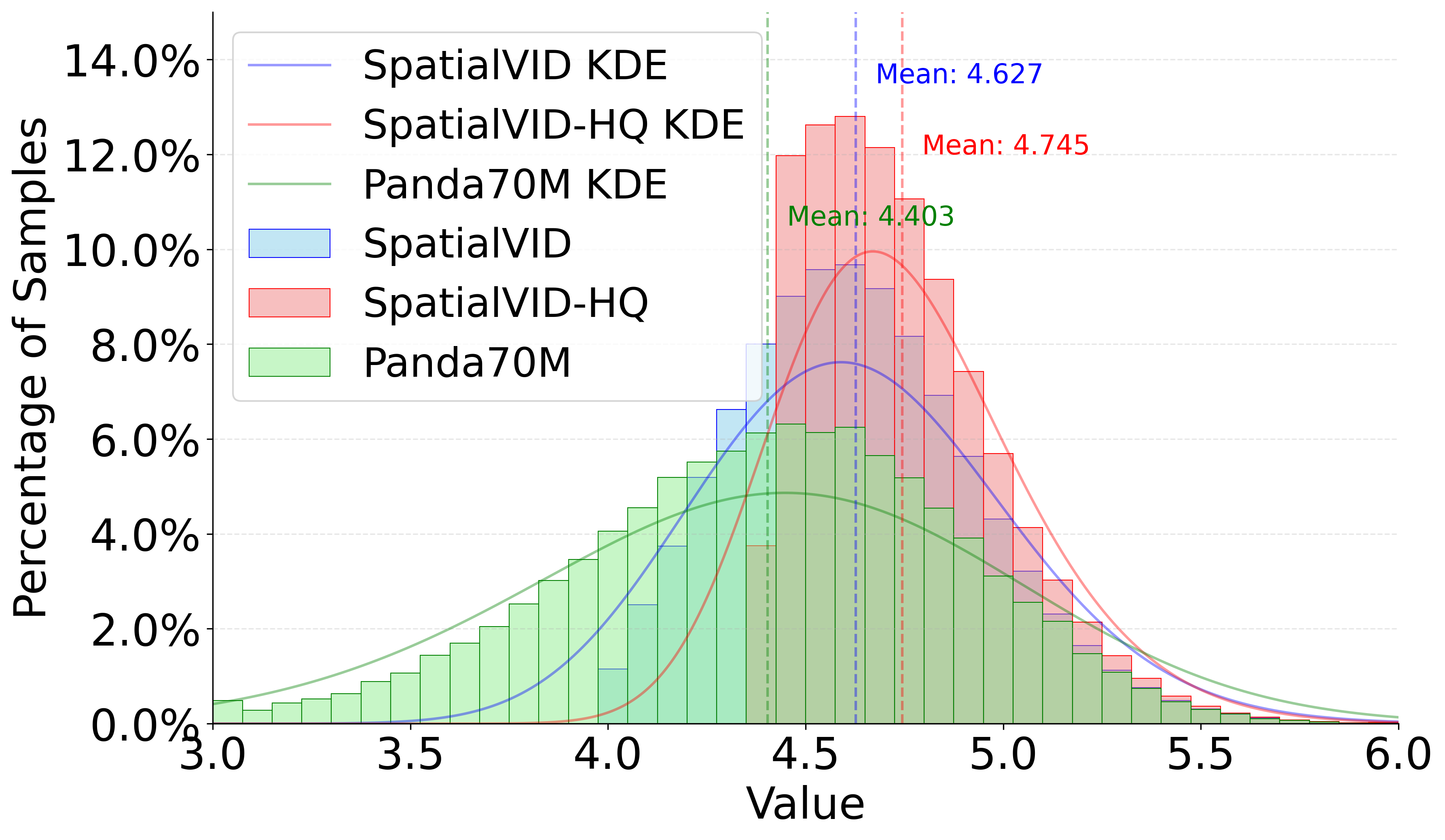
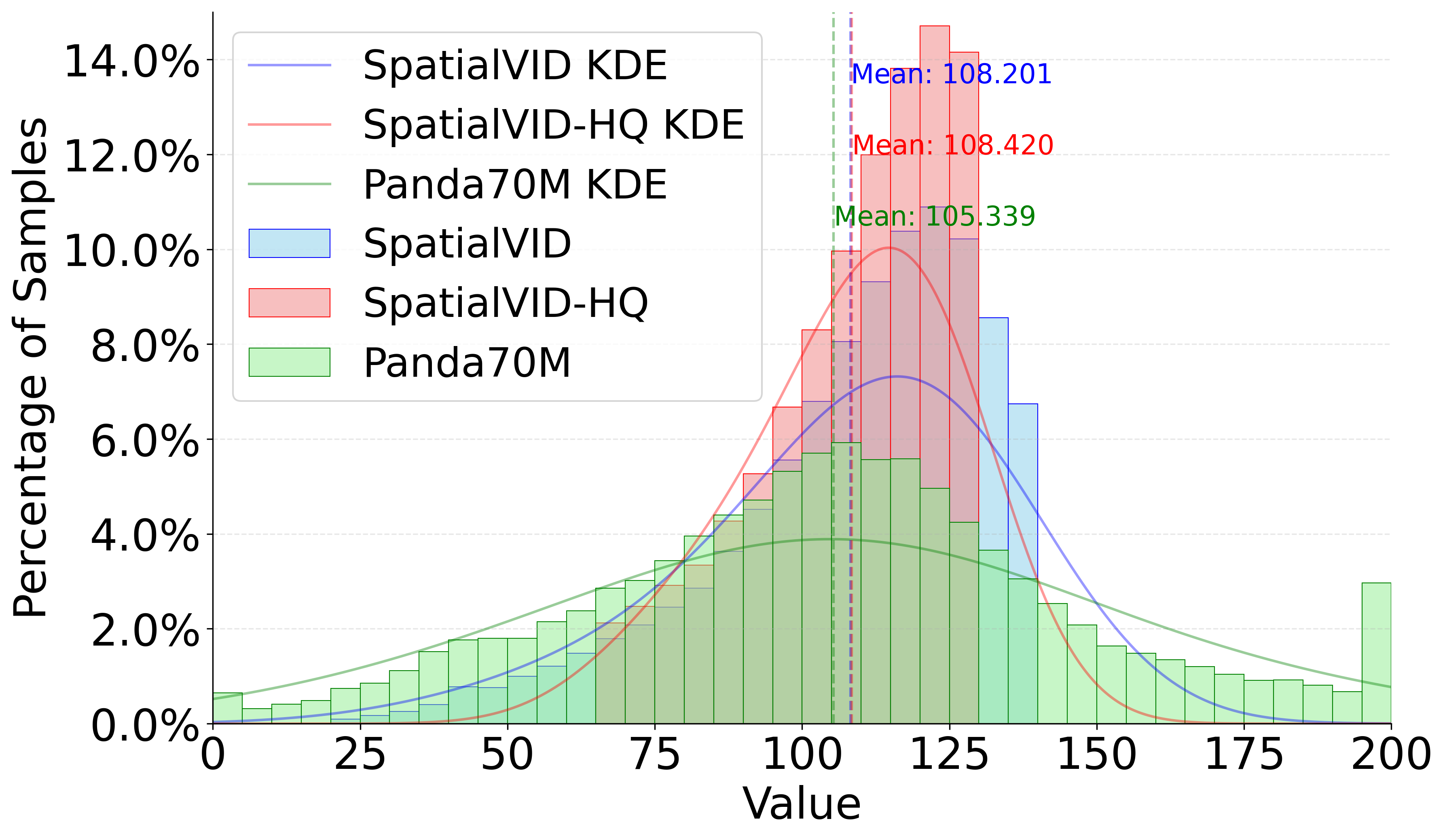
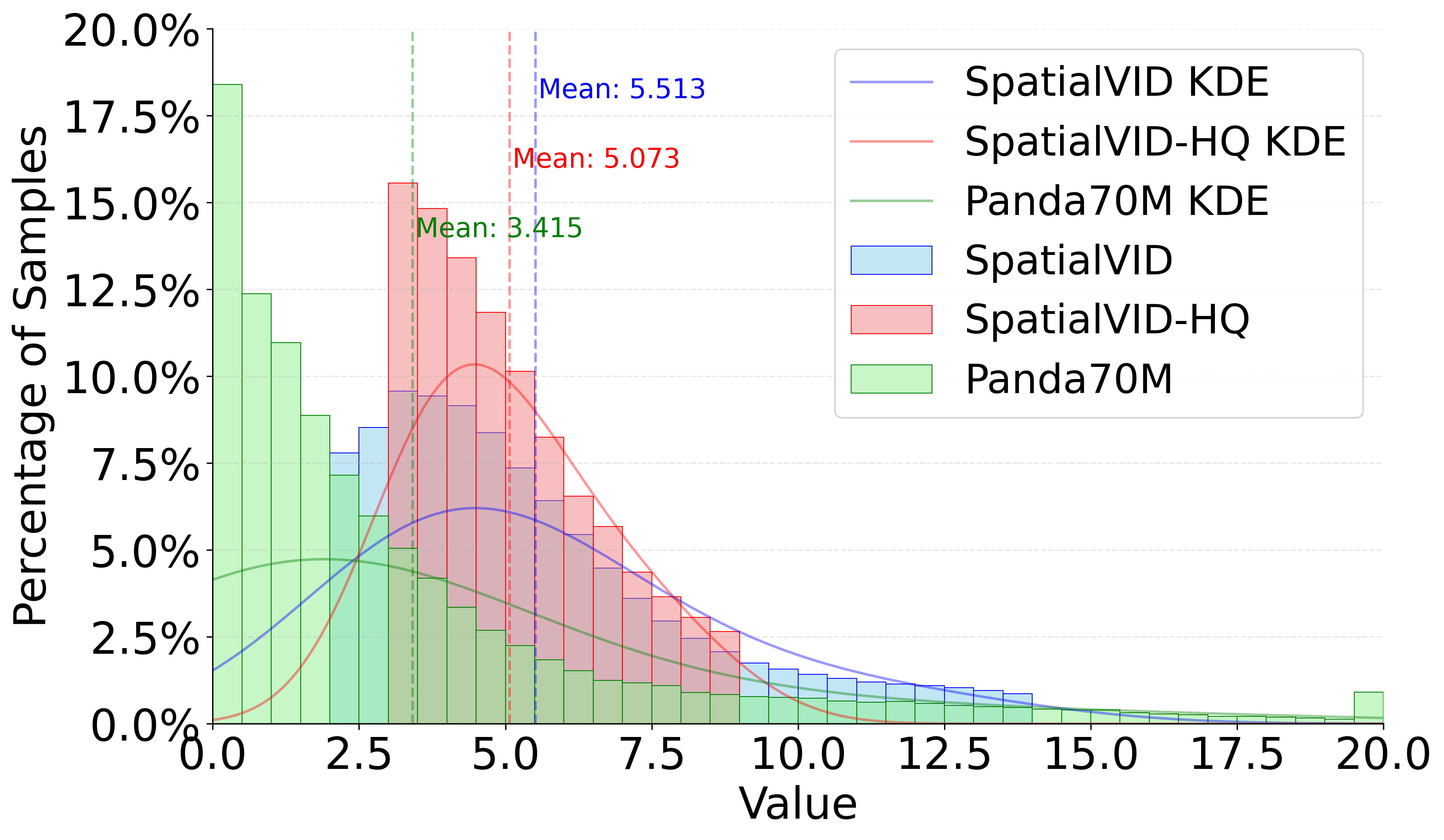
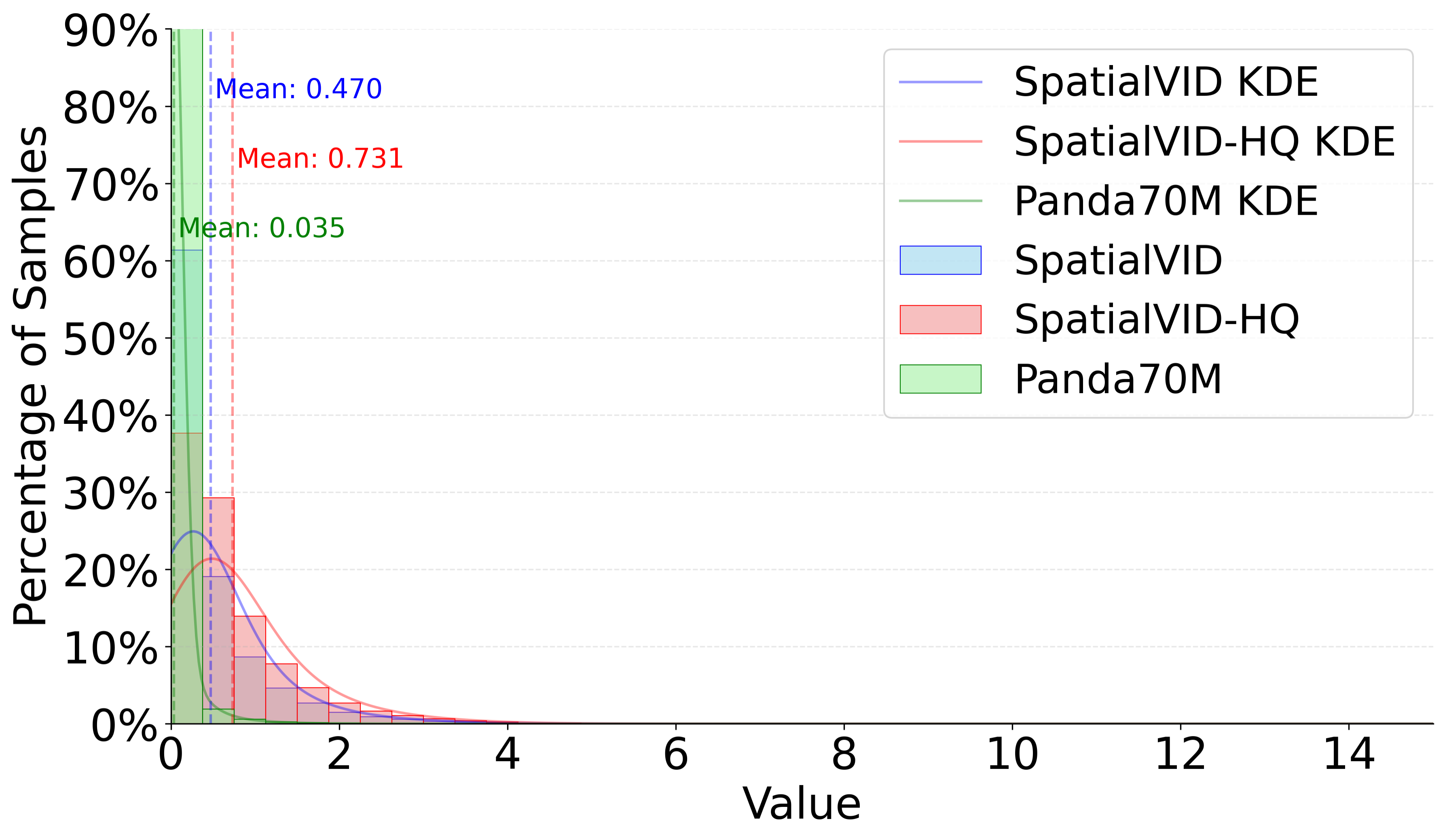
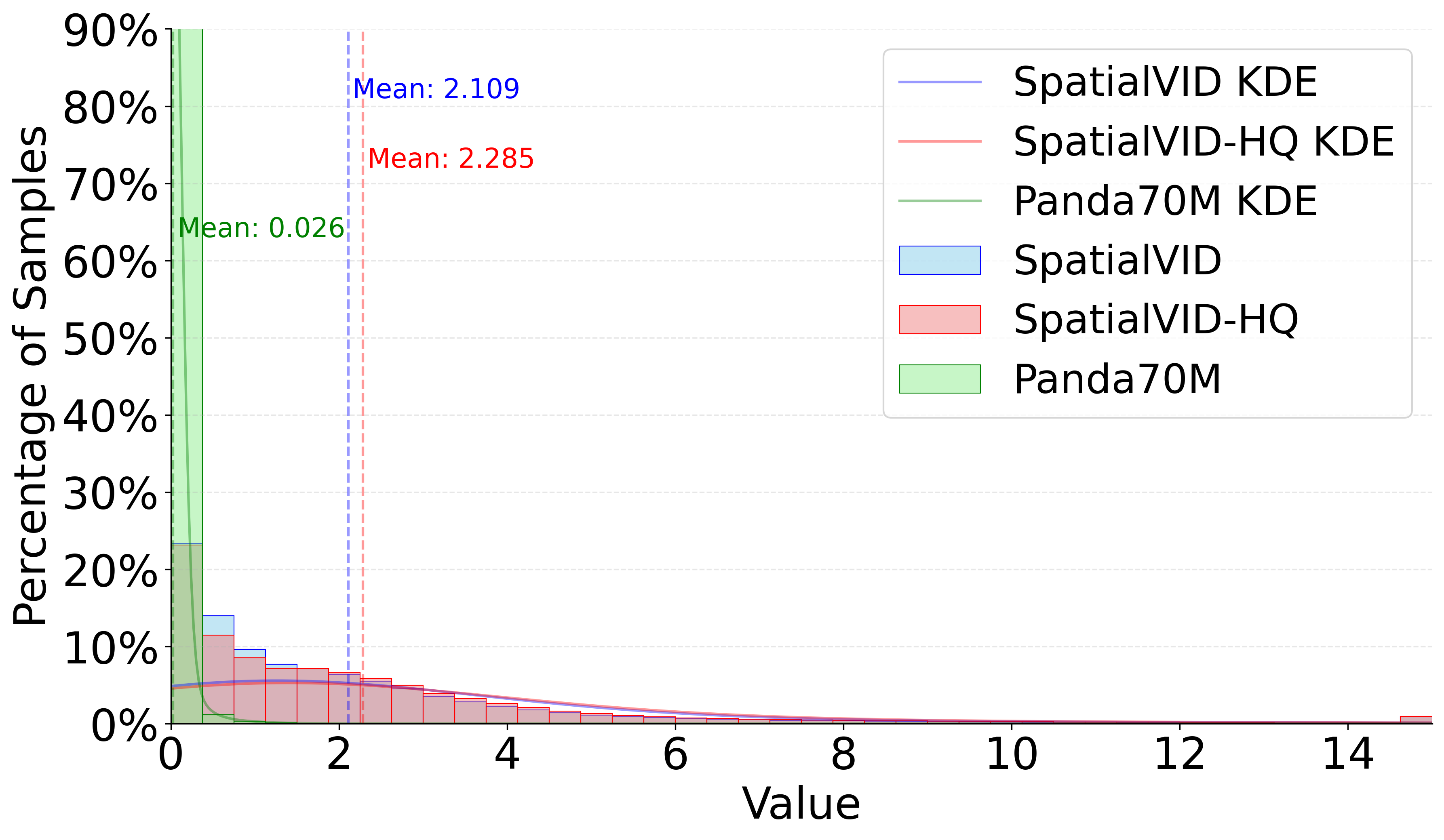
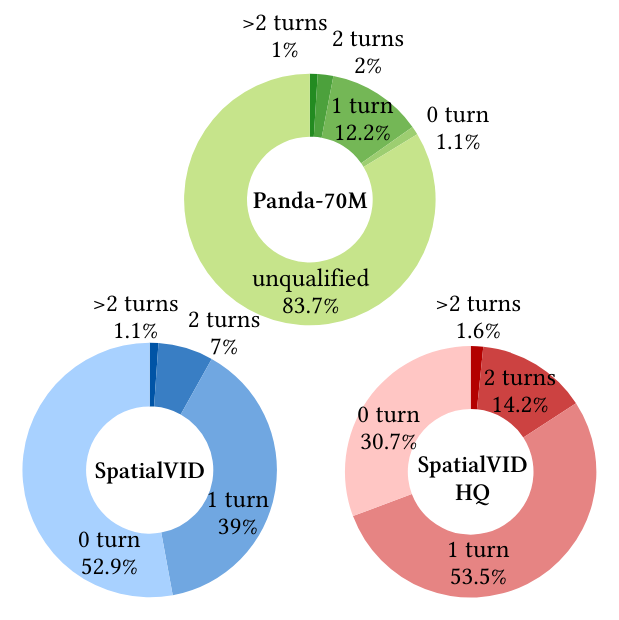
Figure 4: Aesthetics Distribution. SpatialVID-HQ demonstrates a compact, high-quality distribution compared to baseline datasets.
Implications for 3D Vision and World Modeling
SpatialVID establishes a new standard for large-scale, multimodal video datasets with explicit spatial annotations. Its contributions enable:
- Scalable Training of 3D-Aware Models: Facilitates data-driven approaches for 3D reconstruction, novel view synthesis, and dynamic scene understanding.
- Controllable Video Generation: Supports training of models with explicit camera and motion control, advancing physically grounded world simulation.
- Embodied Agents and Navigation: Provides dense supervision for navigation, exploration, and interaction in real-world scenarios.
- Unified Spatial Intelligence: Bridges the gap between semantic-rich video corpora and geometry-centric datasets, fostering the development of unified spatiotemporal models.
Limitations and Future Directions
While MegaSaM provides robust geometric annotation, limitations remain in handling extreme dynamic scenes, variable focal lengths, and radial distortion. Future integration of advanced camera estimators (e.g., ViPE) and depth models will further enhance annotation quality. The dataset's scale and diversity open avenues for research in physically grounded video generation, embodied AI, and interactive world modeling.
Conclusion
SpatialVID delivers a large-scale, richly annotated video dataset that unifies semantic and geometric information for dynamic, real-world scenes. Its procedural curation pipeline, dense multimodal annotations, and balanced sampling strategy set a new benchmark for spatial intelligence research. SpatialVID is poised to catalyze advances in 3D reconstruction, controllable video generation, and embodied agents, laying the foundation for future work in physically grounded, interactive world simulation.