- The paper's main contribution is introducing a unified denoising approach that integrates text and image generation using consistency distillation.
- It employs parallel decoding and trajectory segmentation to markedly reduce sampling steps while achieving improved GenEval, HPS, IR, and CLIP scores.
- Results demonstrate a 1.5x speedup in image-to-text tasks and robust multimodal performance, highlighting practical efficiency gains.
UniCMs: A Unified Consistency Model For Efficient Multimodal Generation and Understanding
Introduction
The paper introduces "Show-o Turbo", an enhanced version of Show-o, a multimodal generative model capable of both text-to-image (T2I) and image-to-text (I2T) tasks. Show-o combines discrete diffusion for images and autoregressive decoding for text, but suffers from inefficiency due to lengthy sampling processes required for both modalities. Show-o Turbo addresses this inefficiency by unifying the generation process under a denoising perspective, leveraging parallel decoding algorithms for text and consistency distillation (CD) principles inspired by diffusion model acceleration.
Methodology
Unified Denoising Perspective
The authors propose a unified denoising view for both image and text generation by utilizing parallel text decoding algorithms, such as Jacobi Decoding. This approach iteratively refines text tokens in parallel, akin to the denoising pattern observed in image generation (Figure 1).
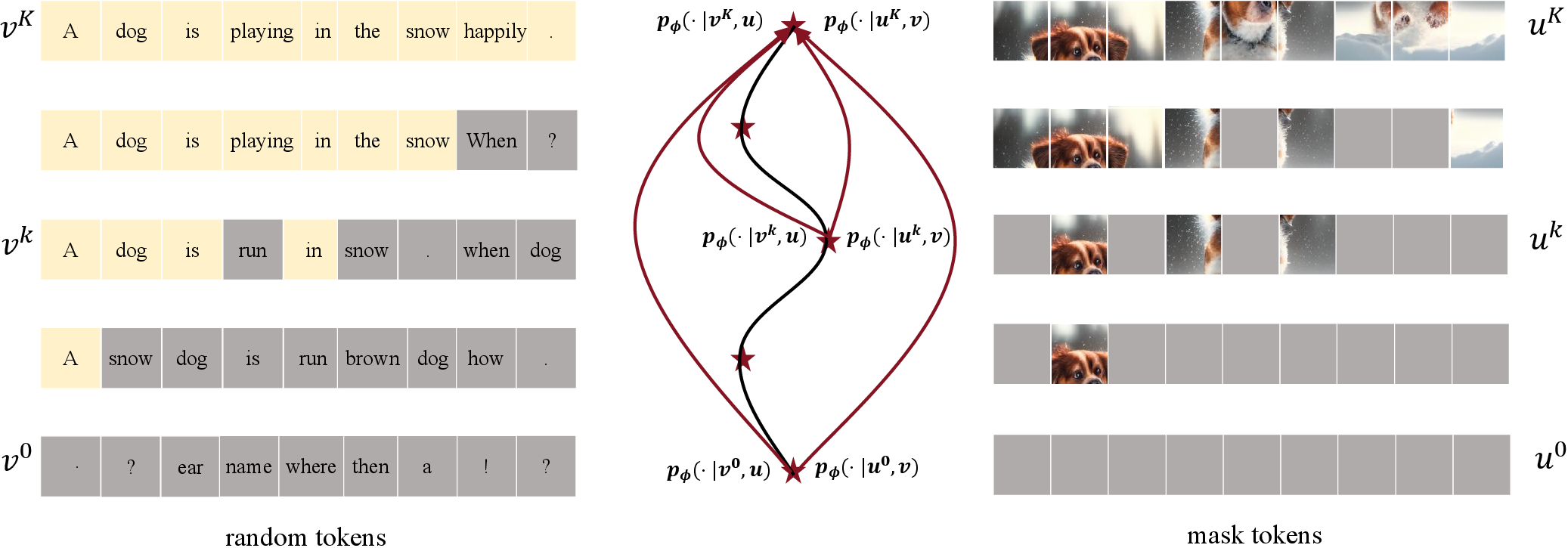
Figure 1: Illustration of the sampling trajectories of text and image tokens in Show-o. As shown, they both display a denoising pattern.
Consistency Distillation
Show-o Turbo applies consistency distillation by mapping any point on the sampling trajectory to the same endpoint. This adaptation of CD to multimodal trajectories, combined with trajectory segmentation and curriculum learning strategies, aids in improving training convergence, enabling efficient sampling with fewer steps.
Implementation Details
To ensure convergence, a combination of global consistency loss and regularizations related to text generation and prediction distributions is used. For efficient training, trajectory segmentation divides the sampling process into segments with decreasing lengths, while curriculum learning adapts the learning objectives as the student model deviates from the teacher's trajectories.
Results
Text-to-Image and Image-to-Text Generation
Empirically, Show-o Turbo achieves significant improvements in generation speed without notable performance degradation. For T2I generation, the model delivers superior GenEval, Human Preference Score (HPS), ImageReward (IR), and CLIP Score (CS) metrics, even in reduced sampling steps compared to Show-o with classifier-free guidance (CFG) (Figure 2).






Figure 2: Comparison between Show-o and Show-o Turbo on 512 resolution in T2I generation. The former crashes in two-step sampling, while the latter maintains good performance.
In image-to-text tasks, Show-o Turbo executes with a 1.5x speedup, maintaining competitive accuracy on benchmarks like Flickr30K and NoCaps and robustness across multiple-choice MMU tasks.
Multimodal Understanding
For MMU tasks requiring one-token responses, Show-o Turbo retains strong question-answering capabilities, reinforcing the model's broad applicability across diverse multimodal scenarios.
Limitations and Future Work
The primary trade-off observed is between acceleration and performance in description tasks. The authors suggest using more sophisticated MMU corpora for distillation as a potential optimization approach. Additionally, extending the consistency distillation principle to more complex or hierarchical sampling trajectories could further enhance efficiency without sacrificing accuracy.
Conclusion
Show-o Turbo demonstrates effective acceleration strategies for multimedia generative models through unified consistency modeling and parallel decoding techniques. By addressing inefficiencies endemic to discrete models through robust distillation processes and innovative training methodologies, this adaptation sets a new standard for multimodal generation without relying on additional guidance mechanisms such as CFG. This contribution opens pathways for further exploration in unified models capable of efficiently handling diverse generative and understanding tasks across modalities.

